
Serhii Maksymenko,
Data Science Solution Architect
Technologie rozpoznávání obličejů se dnes jeví v jiném světle. Případy použití zahrnují široké spektrum aplikací od odhalování trestné činnosti až po identifikaci genetických onemocnění.
Ačkoli vlády po celém světě investují do systémů rozpoznávání obličejů, některá americká města, například Oakland, Somerville a Portland, je zakázala kvůli obavám o občanská práva a soukromí.
Co je to – časovaná bomba, nebo technologický průlom? Tento článek otevírá, co je rozpoznávání obličejů z technologického hlediska a jak hluboké učení zvyšuje jeho schopnosti. Teprve když si uvědomíme, jak technologie rozpoznávání obličejů funguje zevnitř, je možné pochopit, čeho je schopna.
Aktualizováno 06/09/2020:
Jak může hluboké učení modernizovat software pro rozpoznávání obličejů
Stáhnout PDF
Počítačový algoritmus softwaru pro rozpoznávání obličeje se trochu podobá rozpoznávání lidského zraku. Jestliže však lidé ukládají vizuální data do mozku a automaticky si je vybavují, jakmile je to potřeba, počítače by si měly vyžádat data z databáze a porovnat je, aby identifikovaly lidskou tvář.
Zjednodušeně řečeno, počítačový systém vybavený kamerou rozpozná a identifikuje lidskou tvář, extrahuje rysy obličeje, jako je vzdálenost mezi očima, délka nosu, tvar čela a lícních kostí. Poté systém rozpozná obličej a porovná jej s obrázky uloženými v databázi.
Tradiční technologie rozpoznávání obličeje však ještě není zcela dokonalá. Má silné i slabé stránky:
| Silné stránky
Bezkontaktní biometrická identifikace Zpracování dat do jedné sekundy Kompatibilita s většinou fotoaparátů Snadná integrace |
Slabé stránky
Dvojice. a rasové zkreslení Problémy s ochranou osobních údajů Útoky na prezentaci (PA) Nízká přesnost při špatných světelných podmínkách |
Realizace slabých stránek systémů rozpoznávání obličejů, šli datoví vědci ještě dál. Použitím tradičních technik počítačového vidění a algoritmů hlubokého učení vyladili systém rozpoznávání obličejů tak, aby zabránil útokům a zvýšil přesnost. Takto funguje technologie proti falšování obličejů.
Hluboké učení je jedním z nejnovějších způsobů, jak vylepšit technologii rozpoznávání obličejů. Jde o to, že se z obrázků s tvářemi extrahují embeddings obličeje. Takováto vložená zobrazení obličeje budou pro různé obličeje jedinečná. A trénování hluboké neuronové sítě je nejoptimálnějším způsobem, jak tento úkol provést.
V závislosti na úloze a časovém rámci existují dvě běžné metody použití hlubokého učení pro systémy rozpoznávání obličejů:
Použít předtrénované modely, jako jsou dlib, DeepFace, FaceNet a další. Tato metoda vyžaduje méně času a úsilí, protože předtrénované modely již mají sadu algoritmů pro účely rozpoznávání obličejů. Předtrénované modely můžeme také jemně doladit, abychom se vyhnuli zkreslení a systém rozpoznávání obličejů fungoval správně.
Vyvinout neuronovou síť od nuly. Tato metoda je vhodná pro složité systémy rozpoznávání obličejů, které mají víceúčelové funkce. Vyžaduje více času a úsilí a vyžaduje miliony obrázků v trénovací datové sadě, na rozdíl od předtrénovaného modelu, který v případě přenosového učení vyžaduje pouze tisíce obrázků.

Pokud však systém rozpoznávání obličejů obsahuje jedinečné funkce, může to být z dlouhodobého hlediska optimální způsob. Klíčové body, kterým je třeba věnovat pozornost, jsou:
- Správný výběr architektury CNN a ztrátové funkce
- Optimalizace doby inference
- Výkon hardwaru
Při vývoji architektury sítě se doporučuje použít konvoluční neuronové sítě (CNN), protože se osvědčily v úlohách rozpoznávání a klasifikace obrazu. Abyste dosáhli očekávaných výsledků, je lepší použít jako základ obecně uznávanou architekturu neuronové sítě, například ResNet nebo EfficientNet.
Při trénování neuronové sítě pro účely vývoje softwaru pro rozpoznávání obličejů bychom měli ve většině případů minimalizovat chyby. Zde je rozhodující zvážit ztrátové funkce používané pro výpočet chyby mezi skutečným a předpovídaným výstupem. Nejčastěji používané funkce v systémech pro rozpoznávání obličejů jsou tripletová ztráta a AM-Softmax.
- Tripletová ztrátová funkce předpokládá, že máme k dispozici tři obrázky dvou různých osob. Pro jednu osobu jsou dva obrazy – kotevní a pozitivní – a pro druhou osobu třetí – negativní. Parametry sítě se učí tak, aby se stejné osoby v prostoru příznaků přiblížily a různé osoby oddělily.
- Funkce AM-Softmax je jednou z nejnovějších modifikací standardní funkce softmax, která využívá zvláštní regularizaci založenou na aditivní marži. Umožňuje dosáhnout lepší oddělitelnosti tříd, a tím zlepšuje přesnost systému rozpoznávání obličejů.
Existuje také několik přístupů ke zlepšení neuronové sítě. V systémech rozpoznávání obličejů jsou nejzajímavější destilace znalostí, přenosové učení, kvantizace a hloubkově separovatelné konvoluce.
- Destilace znalostí zahrnuje dvě různě velké sítě, kdy velká síť učí svou vlastní menší variantu. Klíčovou hodnotou je, že po tréninku pracuje menší síť rychleji než velká a dává stejný výsledek.
- Přístup přenosového učení umožňuje zlepšit přesnost trénováním celé sítě nebo jen některých vrstev na konkrétní sadě dat. Například pokud má systém rozpoznávání obličejů problémy s rasovým zkreslením, můžeme vzít určitou sadu obrázků, řekněme obrázky Číňanů, a trénovat síť tak, aby dosáhla vyšší přesnosti.
- Kvantizační přístup zlepšuje neuronovou síť, aby dosáhla vyšší rychlosti zpracování. Aproximací neuronové sítě, která používá čísla s pohyblivou řádovou čárkou, neuronovou sítí čísel s malou šířkou bitů můžeme snížit velikost paměti a počet výpočtů.
- Hloubkově oddělitelné konvoluce jsou třídou vrstev, které umožňují sestavit CNN s mnohem menší sadou parametrů ve srovnání se standardními CNN. Tato funkce má sice malý počet výpočtů, ale může zlepšit systém rozpoznávání obličeje tak, aby byl vhodný pro aplikace mobilního vidění.
Klíčovým prvkem technologií hlubokého učení je požadavek na výkonný hardware. Při použití hlubokých neuronových sítí pro vývoj softwaru pro rozpoznávání obličeje je cílem nejen zvýšit přesnost rozpoznávání, ale také zkrátit dobu odezvy. Proto je například GPU pro systémy rozpoznávání obličeje poháněné hlubokým učením vhodnější než CPU.
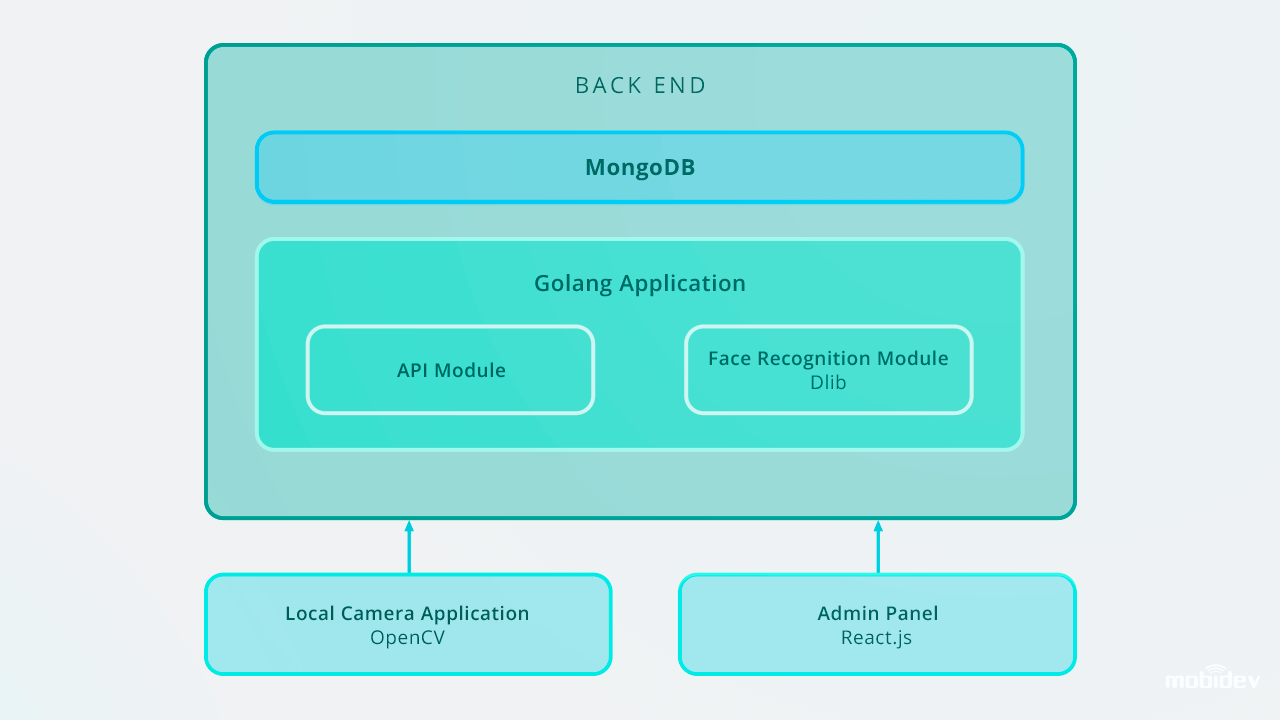
Při vývoji aplikace Big Brother (ukázková aplikace s kamerou) ve společnosti MobiDev jsme se zaměřili na vytvoření softwaru pro biometrické ověřování s přenosem videa v reálném čase. Vzhledem k tomu, že Big Brother je lokální konzolová aplikace pro Ubuntu a Raspbian, je napsána v jazyce Golang a nakonfigurována s identifikátorem lokální kamery a typem čtečky kamery prostřednictvím konfiguračního souboru JSON. Toto video popisuje, jak Big Brother funguje v praxi:
Zevnitř se pracovní cyklus aplikace Big Brother skládá z:
1. Detekce obličejů
Aplikace detekuje obličeje ve videoproudu. Po zachycení obličeje je obraz oříznut a odeslán na zadní stranu prostřednictvím požadavku na formulářová data HTTP. Rozhraní API zadního konce uloží obrázek do místního souborového systému a uloží záznam do protokolu detekce s identifikátorem osoby.
Zadní konec využívá Golang a kolekce MongoDB k ukládání dat o zaměstnancích. Všechny požadavky na rozhraní API jsou založeny na rozhraní RESTful API.

2. Okamžité rozpoznávání obličejů
Zadní konec má na pozadí pracovníka, který vyhledává nové neklasifikované záznamy a používá Dlib k výpočtu 128rozměrného deskriptorového vektoru rysů obličeje. Kdykoli je vektor vypočítán, je porovnán s několika referenčními obrazy obličeje výpočtem euklidovské vzdálenosti ke každému vektoru rysů každé osoby v databázi a nalezne shodu.
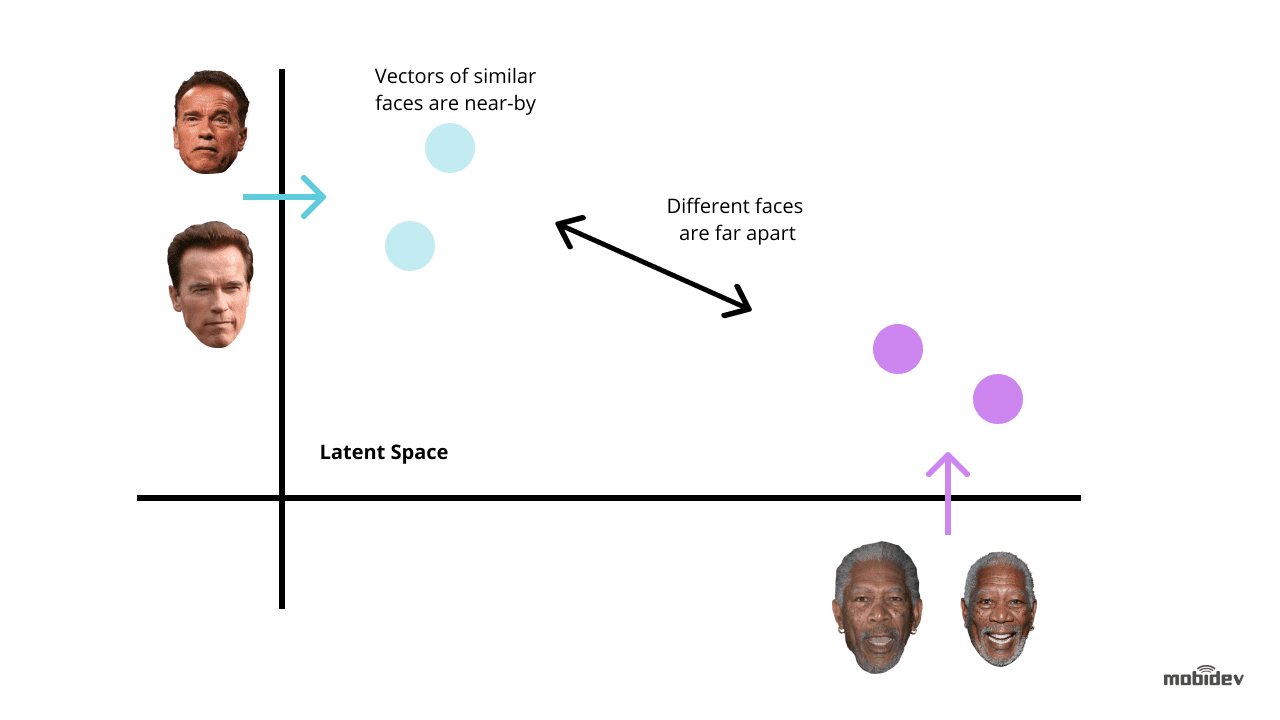
Je-li euklidovská vzdálenost k rozpoznané osobě menší než 0,6, pracovník nastaví do protokolu detekce identifikátor osoby a označí ji jako klasifikovanou. Pokud je vzdálenost větší než 0,6, vytvoří do protokolu nové ID osoby.
3. Následné akce: upozornění, udělení přístupu a další
Obrázky neidentifikované osoby jsou odeslány příslušnému správci s upozorněním prostřednictvím chatbotů v messengerech. V aplikaci Big Brother jsme použili Microsoft Bot Framework a Errbot založený na Pythonu, což nám umožnilo implementovat výstražného chatbota během pěti dnů.

Poté lze tyto záznamy spravovat prostřednictvím panelu správce, který ukládá fotografie s ID do databáze. Software pro rozpoznávání obličejů pracuje v reálném čase a úlohy rozpoznávání obličejů provádí okamžitě. Využitím prostředí Golang a sbírky MongoDB pro ukládání dat zaměstnanců jsme zadali databázi IDs, která obsahuje 200 záznamů.
Takto je navržena aplikace rozpoznávání obličejů Big Brother:
V případě škálování na 10 000 záznamů bychom doporučili vylepšit systém rozpoznávání obličejů, aby byla zachována vysoká rychlost rozpoznávání na zadní straně. Jedním z optimálních způsobů je použití paralelizace. Nastavením load balanceru a vybudováním několika webových workerů můžeme zajistit správnou práci backendové části a optimální rychlost celého systému.
Rozpoznávání obličejů není jedinou úlohou, kde může vývoj softwaru založeného na hlubokém učení zvýšit výkon. Mezi další příklady patří:
Detekce a rozpoznávání maskovaných obličejů
Od doby, kdy COVID-19 donutil lidi v mnoha zemích nosit obličejové masky, se technologie rozpoznávání obličejů stala pokročilejší. Pomocí algoritmu hlubokého učení založeného na konvolučních neuronových sítích mohou nyní kamery rozpoznávat obličeje zakryté maskami. Datoví inženýři využívají takové algoritmy, jako jsou modely rozpoznávání obličeje na základě více očí a periokulární rozpoznávání, aby zlepšili schopnosti systému rozpoznávání obličeje. Díky identifikaci takových rysů obličeje, jako je čelo, obrys obličeje, oční a periokulární detaily, obočí, oči a lícní kosti, umožňují tyto modely rozpoznávat maskované obličeje s přesností až 95 %.
Dobrým příkladem takového systému je technologie rozpoznávání obličejů vytvořená jednou z čínských společností. Systém se skládá ze dvou algoritmů: rozpoznávání obličejů na základě hlubokého učení a infračerveného termovizního měření teploty. Když se lidé v obličejových maskách postaví před kameru, systém extrahuje rysy obličeje a porovnává je s existujícími snímky v databázi. Současně mechanismus infračerveného měření teploty měří teplotu, čímž detekuje osoby s abnormální teplotou.
Detekce vad
V posledních několika letech výrobci používají k detekci vad vizuální kontrolu založenou na umělé inteligenci. Vývoj algoritmů hlubokého učení umožňuje tomuto systému automaticky definovat i ty nejmenší škrábance a praskliny a vyhnout se tak lidskému faktoru.
Detekce tělesných abnormalit
Izraelská společnost Aidoc vyvinula řešení pro radiologii poháněné hlubokým učením. Analýzou lékařských snímků tento systém detekuje abnormality v hrudníku, krční páteři, hlavě a břiše.
Identifikace mluvčích
Technologie identifikace mluvčích vytvořená společností Phonexia rovněž identifikuje mluvčí s využitím přístupu metrického učení. Systém rozpoznává mluvčí podle hlasu a vytváří matematické modely lidské řeči nazvané voiceprints. Tyto hlasové otisky jsou uloženy v databázích, a když člověk promluví, technologie reproduktoru identifikuje jedinečný hlasový otisk.
Rozpoznávání emocí
Rozpoznávání lidských emocí je dnes proveditelný úkol. Sledováním pohybů obličeje prostřednictvím kamery technologie rozpoznávání emocí kategorizuje lidské emoce. Algoritmus hlubokého učení identifikuje orientační body lidské tváře, detekuje neutrální výraz obličeje a měří odchylky výrazů obličeje, přičemž rozpoznává spíše pozitivní nebo negativní výrazy.
Rozpoznávání emocí
Společnost Visual One, která je dodavatelem kamer Nest Cams, vybavila svůj produkt umělou inteligencí. S využitím technik hlubokého učení vyladila kamery Nest Cams tak, aby rozpoznávaly nejen různé objekty, jako jsou lidé, domácí zvířata, auta atd. ale také identifikovaly akce. Soubor rozpoznávaných akcí lze přizpůsobit a vybrat uživatelem. Kamera může například rozpoznat kočku škrábající na dveře nebo dítě hrající si s kamny.
Pokud to shrneme, hluboké neuronové sítě jsou pro lidstvo mocným nástrojem. A jen člověk rozhoduje o tom, jaká technologická budoucnost přijde příště.
Jak může hluboké učení modernizovat software pro rozpoznávání obličejů
Stáhnout PDF
.