Od Kajal Yadav, spisovatelky na volné noze píšící o datové vědě, startupech &podnikání.

Zdroj Unsplash, upraveno autorem.
Těšíte se na vstup do světa datové vědy? Gratulujeme vám! To je stále správná volba, protože v průběhu této pandemie dochází ke konečnému nárůstu potřeby práce v oblasti Data Science a umělé inteligence.
I když kvůli krizi se trh v současné době stává tvrdším, aby jej bylo možné znovu nastavit s větší mužskou silou, jak to dělají dříve. Takže je možné, že se budete muset psychicky připravit na dlouhodobou cestu najímání zaměstnanců a mnoho odmítnutí po cestě.
Při psaní tohoto článku předpokládám, že již víte, že portfolio datových věd je klíčové a jak ho vybudovat.
Možná trávíte většinu času chroustáním a zpracováváním dat a ne aplikací fantastických modelů.
Jednou z otázek, kterou mi nadšenci do datové vědy kladou stále dokola, je, že jaký druh projektů by měli zahrnout do svého portfolia, aby si vybudovali ohromně dobré a jedinečné portfolio.
Níže uvádím 8 jedinečných nápadů pro vaše portfolio datové vědy s přiloženými referenčními články, z nichž získáte přehled o tom, jak s některým konkrétním nápadem začít.
- Analýza sentimentu u deprese na základě příspěvků na sociálních sítích
- Sportovní zápas video na text shrnutí pomocí neuronové sítě
- Rozpoznávání ručně psaných rovnic pomocí CNN
- Generování shrnutí z obchodní schůzky pomocí NLP
- Rozpoznávání obličeje pro zjišťování nálady a navrhování písní podle toho
- Zjištění obyvatelných exoplanet ze snímků pořízených kosmickými přístroji jako Kepler
- Regenerace obrazu pro starý poškozený snímek z kotouče
- Generování hudby pomocí hlubokého učení
- ZÁVĚREČNÉ SLOVO

Foto: dole777 na Unsplash.
Toto téma je v dnešní době tak citlivé, že je třeba s ním něco dělat. Na světě je více než 264 milionů osob, které trpí depresí. Deprese je celosvětově hlavní příčinou invalidity a významně se podílí na celkové globální zátěži nemocemi a téměř 800 000 jedinců si každoročně trvale ukousne život kvůli sebevraždě. Sebevražda je druhou nejčastější příčinou úmrtí osob ve věku 15-29 let. Léčba deprese je často opožděná, nepřesná nebo zcela chybí.
Život na internetu dává hlavní šanci na změnu služeb včasné mediace melancholie, zejména u mladých dospělých lidí. Důsledně je na Twitteru tweetováno zhruba 6 000 tweetů, což se týká více než 350 000 tweetů odeslaných za každý okamžik, 500 milionů tweetů za každý den a přibližně 200 miliard tweetů za každý rok.
Jak uvádí Pew Research Center, 72 % veřejnosti používá nějaký druh internetového života. Datové soubory zveřejňované ze sociálních sítí jsou důležité pro řadu oborů, například pro vědu o člověku a výzkum mozku. Podpory z odborného hlediska však zdaleka nestačí a explicitní metodiky mají zoufale málo štěstí.
Analýzou jazykových markerů v příspěvcích na sociálních sítích je možné vytvořit model hlubokého učení, který může dát jednotlivci náhled na jeho duševní zdraví mnohem dříve než tradiční přístupy.
- You Are What You Tweet – Detecting Depression in Social Media via Twitter Usage
- Early Detection of Depression:
- Detekce deprese z dat sociálních sítí pomocí technik strojového učení
Sportovní zápas video na text shrnutí pomocí neuronové sítě

Foto: Aksh yadav na Unsplash.
Tato myšlenka projektu je v podstatě založena na získání přesného shrnutí z videa sportovního zápasu. Existují sportovní webové stránky, které vyprávějí o nejzajímavějších momentech zápasu. Pro úlohu extraktivního shrnutí textu byly navrženy různé modely, ale neuronové sítě odvádějí nejlepší práci. Shrnutí zpravidla odkazuje na představení informací ve stručné struktuře, soustředění se na části, které zprostředkovávají fakta a informace, při zachování důležitosti.
Automatické vytvoření osnovy videozáznamu zápasu přináší úkol rozlišit fascinující minuty nebo hlavní momenty zápasu.
Toho lze dosáhnout pomocí některých technik hlubokého učení, jako jsou 3D-CNN (trojrozměrné konvoluční sítě), RNN (rekurentní neuronové sítě), LSTM (sítě s dlouhodobou krátkodobou pamětí) a také pomocí algoritmů strojového učení rozdělením videa na různé části a následným použitím algoritmů SVM (Support vector machines), NN (neuronové sítě) a k-means.
Pro lepší pochopení si podrobně přečtěte přiložený článek.
- Klasifikace scén pro sumarizaci sportovních videí pomocí přenosového učení – Tento článek navrhuje novou metodu klasifikace scén sportovních videí.
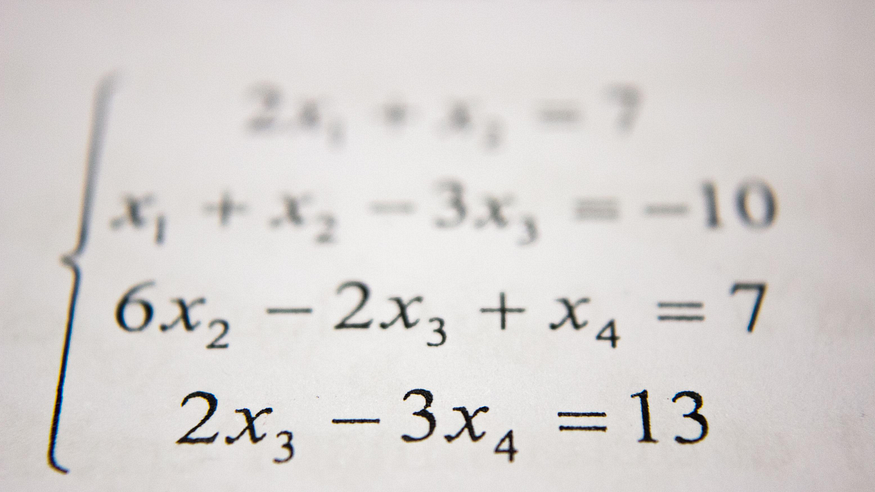
Foto: Antoine Dautry na Unsplash.
Rozpoznávání ručně psaných matematických výrazů je jedním z nejasných problémů v oblasti výzkumu počítačového vidění. Řešitele ručně psaných rovnic lze trénovat podle ručně psaných číslic a matematických symbolů pomocí konvoluční neuronové sítě (CNN) s některými technikami zpracování obrazu. Vývoj takového systému vyžaduje trénink našich strojů s daty, aby se zdatně učily a prováděly požadované předpovědi.
Pro lepší pochopení si přečtěte níže připojené články.
- Ručně psaný řešitel rovnic pomocí konvoluční neuronové sítě
- vipul79321/Handwritten-Equation-Solver – An Handwritten Equation solver using CNN Equation can contain any digit from 0-9 and symbol.
- Počítačové vidění – Automatické třídění ručně psaných matematických odpovědních listů – Digitalizace kroků řešení matematické rovnice napsané volnou rukou na papíře.
- Rukou psané rovnice do LaTeXu
Generování shrnutí z obchodní schůzky pomocí NLP

Foto: Sebastian Herrmann na Unsplash.
Uvízli jste někdy v situaci, kdy všichni chtějí vidět shrnutí a ne celou zprávu? No, setkal jsem se s tím během svých školních a vysokoškolských let, kdy jsme strávili spoustu času přípravou celé zprávy, ale učitel má čas přečíst si pouze shrnutí.
Shrnutí vyvstalo jako neúprosně užitečný způsob, jak řešit problém přetížení daty. Získávání informací z rozhovorů může mít velmi dobrou komerční i vzdělávací hodnotu. To lze provést pomocí zachycení rysů statistických, jazykových a pocitových aspektů s dialogickou strukturou rozhovoru.
Ruční změna zprávy do shrnující podoby je příliš časově náročná, není-liž pravda? Lze se však spolehnout na techniky zpracování přirozeného jazyka (NLP).
Sumarizace textu pomocí hlubokého učení dokáže pochopit kontext celého textu. Není to splněný sen nás všech, kteří potřebujeme přijít s rychlým shrnutím dokumentu!
Pro lepší pochopení se podívejte na níže přiložené články.
- Komplexní průvodce sumarizací textu pomocí hlubokého učení v Pythonu – „Nechci celou zprávu, stačí mi shrnutí výsledků.“
- Pochopte sumarizaci textu a vytvořte si vlastní sumarizátor v Pythonu – Sumarizaci lze definovat jako úlohu vytvoření stručného a plynulého shrnutí při zachování klíčových informací.

Foto: Alireza Attari na Unsplash.
Lidská tvář je důležitou součástí těla jedince a hraje zejména významnou roli při poznávání duševního stavu člověka. Odpadá tak nudné a zdlouhavé ruční vyčleňování nebo seskupování skladeb do různých záznamů a pomáhá při vytváření vhodného seznamu skladeb na základě emocionálních vlastností jedince.
Lidé mají tendenci poslouchat hudbu podle své nálady a zájmů. Lze vytvořit aplikaci, která bude uživatelům navrhovat skladby na základě jejich nálady zachycením výrazů obličeje.
Počítačové vidění je interdisciplinární obor, který pomáhá zprostředkovat počítačům pochopení digitálních obrázků nebo videí na vysoké úrovni. Součásti počítačového vidění lze použít k určení emocí uživatele prostřednictvím výrazu obličeje.
Existují také tato rozhraní API, která mi připadají zajímavá a užitečná. Na nich jsem však nepracoval, ale přikládám je zde s nadějí, že vám pomohou.
- 20+ rozhraní API pro rozpoznávání emocí, která na vás udělají dojem, a obavy | Nordic API – Kdyby podniky mohly pomocí techniky neustále vnímat emoce, mohly by je využít k prodeji spotřebitelům.
Zjištění obyvatelných exoplanet ze snímků pořízených kosmickými přístroji jako Kepler

Foto: Nick Owuor (astro.nic.visuals) na Unsplash.
V posledním desetiletí bylo sledováno přes milion hvězd za účelem identifikace tranzitujících planet. Ruční interpretace potenciálních kandidátů na exoplanety je pracná a podléhá lidské chybě, jejíž důsledky lze jen těžko vyhodnotit. Konvoluční neuronové sítě jsou vhodné pro identifikaci exoplanet podobných Zemi v zašuměných datech časových řad s výraznější přesností než strategie nejmenších čtverců.
- Lov exoplanet pomocí strojového učení – Hunting worlds beyond our solar system.
- Umělá inteligence, data NASA použitá k objevení exoplanety – Naše sluneční soustava je nyní vyrovnaná v počtu planet kolem jedné hvězdy.
Regenerace obrazu pro starý poškozený snímek z kotouče

Zdroj Pikist.
Vím, jak časově náročné a bolestivé je získat zpět svou starou poškozenou fotografii v původní podobě, jaká byla dříve. Proto to lze provést pomocí hlubokého učení tak, že se najdou všechny vady obrazu (zlomy, oděrky, díry) a použijí se algoritmy pro inpainting, takže lze snadno odhalit vady na základě hodnot pixelů v jejich okolí a obnovit a vybarvit staré fotografie.
- Vybarvení a obnova starých snímků pomocí hlubokého učení – Vybarvení černobílých snímků pomocí hlubokého učení se stalo působivou ukázkou reálného použití.
- Průvodce inpaintingem obrazu:
- Jak provádět restaurování obrázků Absolutely DataSet Free
Generování hudby pomocí hlubokého učení

Foto: Abigail Keenan na Unsplash.
Hudba je sortiment tónů různých frekvencí. Automatické generování hudby je tedy proces skládání krátké hudební skladby s co nejmenším lidským zprostředkováním. V poslední době se špičkou pro programované generování hudby stalo inženýrství hlubokého učení.
- Generování hudby pomocí hlubokého učení
- Jak generovat hudbu pomocí neuronové sítě LSTM v Kerasu – úvod do vytváření hudby pomocí neuronových sítí LSTM
ZÁVĚREČNÉ SLOVO
Vím, že je to opravdový boj vybudovat skvělé portfolio datových věd. Ale s takovou sbírkou, kterou jsem poskytl výše, můžete v této oblasti udělat nadprůměrný pokrok. Sbírka je nová, což dává příležitost i pro výzkumné účely. Takže i výzkumníci v oblasti datové vědy si mohou vybrat tyto nápady, na kterých budou pracovat, aby jejich výzkum byl pro datové vědce velkou pomocí při zahájení projektu. Navíc je zábavné zkoumat stránky, které nikdo předtím nedělal. I když tato sbírka vlastně představuje nápady od začátečnické až po pokročilou úroveň.
Takže ji doporučím nejen nováčkům v oblasti datové vědy, ale i starším datovým vědcům. Otevře vám mnoho nových cest během vaší kariéry, a to nejen díky projektům, ale také díky nově získaným kontaktům.
Tyto nápady vám ukážou širokou škálu možností a dají vám nápady, jak myslet out of the box.
Pro mě a mé přátele jsou důležité faktory učení, přidávání hodnoty společnosti a neprozkoumané znalosti a svým způsobem i zábava. Takže mě v podstatě baví dělat takové projekty, které nám dávají možnost získat svým způsobem obrovské znalosti a umožňují nám prozkoumat neprobádané dimenze. Na to se zaměřujeme především, když věnujeme čas takovým projektům.
Originální. Přetištěno se svolením autora.
Bio: Kajal Yadav je spisovatelka na volné noze, která se specializuje na datovou vědu, startupy a podnikání. Píše pro několik publikací a zároveň spolupracuje se startupy na jejich obsahových marketingových strategiích.
Související:
- Začněte svou kariéru v oblasti strojového učení v karanténě
- Projekty, které zahrnout do portfolia datových věd
- Jak vytvořit portfolio datových věd
.