
Když všichni vstupujeme do třetího měsíce pandemie COVID-19 a hledáme nové projekty, které by nás zaměstnaly (čti: udržely při smyslech), můžeme vás zaujmout výukou základů počítačových úložišť? V tichosti jsme letos na jaře již probrali některé nezbytné základy, například jak otestovat rychlost disků a co je to sakra RAID. V druhém z těchto článků jsme dokonce slíbili pokračování zkoumající výkon různých topologií více disků v ZFS, souborovém systému nové generace, o kterém jste slyšeli, protože se objevuje všude od Applu po Ubuntu.
No, dnes je ten správný den na zkoumání, čtenáři zvědaví na ZFS. Jen dopředu vězte, že podceňovanými slovy vývojáře systému OpenZFS Matta Ahrense „je to opravdu složité.“
Ale než se dostaneme k číslům – a ta přijdou, slibuji!-všech způsobů, jak můžete utvářet osm disků systému ZFS, musíme si v první řadě promluvit o tom, jak systém ZFS ukládá data na disk.
Zpools, vdevs a zařízení
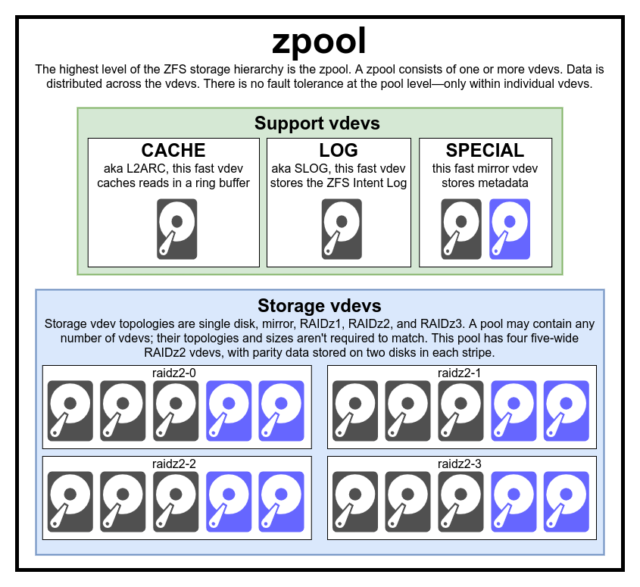

Chcete-li systému ZFS skutečně porozumět, musíte věnovat skutečnou pozornost jeho skutečné struktuře. Systém ZFS spojuje tradiční vrstvy správy svazků a souborového systému a používá transakční mechanismus kopírování při zápisu – obojí znamená, že systém je strukturálně velmi odlišný od běžných souborových systémů a polí RAID. První sadou hlavních stavebních bloků, kterým je třeba porozumět, jsou zpools, vdevs a devices.
zpool
Struktura zpool je nejvyšší strukturou systému ZFS. Zpool obsahuje jeden nebo více vdevs, z nichž každý zase obsahuje jeden nebo více devices. Zpooly jsou samostatné jednotky – jeden fyzický počítač může mít na sobě dva nebo více samostatných zpoolů, ale každý z nich je zcela nezávislý na ostatních. Zpooly nemohou mezi sebou sdílet vdevs.
Redundance systému ZFS je na úrovni vdev, nikoli na úrovni zpool. Na úrovni zpoolů neexistuje absolutně žádná redundance – pokud dojde ke ztrátě jakéhokoli úložného vdev nebo SPECIAL vdev, ztratí se s ním i celý zpool.
Moderní zpooly mohou přežít ztrátu CACHE nebo LOG vdev – i když mohou ztratit malé množství špinavých dat, pokud ztratí LOG vdev při výpadku napájení nebo pádu systému.
Bývá mylnou představou, že ZFS „prokládá“ zápisy napříč poolem – ale to je nepřesné. Zpool není legračně vypadající RAID0 – je to legračně vypadající JBOD se složitým distribučním mechanismem, který se může měnit.
Většinou se zápisy rozdělují mezi dostupné vdevy podle jejich dostupného volného místa, takže všechny vdevy se teoreticky zaplní současně. V novějších verzích ZFS může být zohledněno i vytížení vdev – pokud je jeden vdev výrazně vytíženější než jiný (např. kvůli zatížení čtením), může být dočasně pro zápis vynechán, přestože má nejvyšší poměr dostupného volného místa.
Mezinformace o využití zabudovaná v moderních metodách distribuce zápisu v systému ZFS může snížit latenci a zvýšit propustnost v obdobích neobvykle vysokého zatížení – neměla by se však zaměňovat za carte blanche libovolně míchat pomalé rezavé disky a rychlé SSD v jednom fondu. Takový nesourodý pool bude obecně stále fungovat, jako by byl celý složen z nejpomalejšího přítomného zařízení.
vdev
Každý zpool se skládá z jednoho nebo více vdevs(zkratka pro virtuální zařízení). Každé vdev se zase skládá z jednoho nebo více skutečných devices. Většina vdev se používá pro obyčejné úložiště, ale existuje také několik speciálních podpůrných tříd vdev – včetně CACHE, LOG a SPECIAL. Každý z těchto typů vdev může nabízet jednu z pěti topologií – jedno zařízení, RAIDz1, RAIDz2, RAIDz3 nebo zrcadlení.
RAIDz1, RAIDz2 a RAIDz3 jsou speciální odrůdy toho, čemu úložní šedivci říkají „diagonální paritní RAID“. Čísla 1, 2 a 3 označují, kolik paritních bloků je přiděleno každému datovému proužku. Namísto toho, aby byly celé disky vyhrazeny pro paritu, vdev RAIDz rozdělují tuto paritu částečně rovnoměrně mezi disky. Pole RAIDz může ztratit tolik disků, kolik má paritních bloků; pokud ztratí další, selže a vezme s sebou zpool.
Zrcadlové vdev jsou přesně takové, jak zní – v zrcadlovém vdev je každý blok uložen na každém zařízení vdev. Ačkoli nejběžnější jsou zrcadla se dvěma šířkami, zrcadlový vdev může obsahovat libovolný počet zařízení – třícestná jsou běžná ve větších sestavách kvůli vyššímu výkonu čtení a odolnosti proti chybám. Zrcadlový vdev může přežít jakoukoli poruchu, pokud alespoň jedno zařízení ve vdev zůstane zdravé.
Zrcadlové vdev s jedním zařízením jsou také přesně takové, jak zní – a jsou ze své podstaty nebezpečné. Zařízení vdev s jedním zařízením nemůže přežít žádné selhání – a pokud je používáno jako úložiště nebo SPECIAL zařízení vdev, jeho selhání s sebou strhne celé zařízení zpool. Zde buďte velmi, velmi opatrní.
CACHE, LOG a SPECIAL vdev lze vytvořit pomocí kterékoli z výše uvedených topologií – ale nezapomeňte, že ztráta SPECIAL vdev znamená ztrátu celého fondu, takže redundantní topologie se důrazně doporučuje.
device
Jedná se pravděpodobně o nejjednodušší termín související se systémem ZFS – je to doslova jen blokové zařízení s náhodným přístupem. Pamatujte, že vdevs se skládá z jednotlivých zařízení a zpool se skládá z vdevs.
Disky – buď rezavé, nebo pevné – jsou nejběžnější bloková zařízení používaná jako vdev stavební bloky. Fungovat však bude cokoli s deskriptorem v /dev, co umožňuje náhodný přístup – takže jako jednotlivá zařízení lze použít (a někdy se používají) celá hardwarová pole RAID.
Jedním z nejdůležitějších alternativních blokových zařízení, ze kterých lze vdev sestavit, je jednoduchý surový soubor. Testovací pooly vytvořené z řídkých souborů jsou neuvěřitelně pohodlným způsobem, jak si procvičit příkazy zpoolu a zjistit, kolik místa je k dispozici v poolu nebo vdev dané topologie.

Řekněme, že uvažujete o stavbě osmišachtového serveru a jste si téměř jisti, že budete chtít použít 10TB (~9300 GiB) disky – ale nejste si jisti, jaká topologie nejlépe vyhovuje vašim potřebám. Ve výše uvedeném příkladu jsme během několika sekund vytvořili testovací pool z řídkých souborů – a nyní víme, že vdev RAIDz2 složený z osmi 10TB disků nabízí 50TiB využitelné kapacity.
Existuje jedna speciální třída device – SPARE. Zařízení Hotspare patří na rozdíl od běžných zařízení do celého fondu, nikoliv do jediného vdev. Pokud dojde k poruše některého zařízení vdev ve fondu a k fondu je připojeno a dostupné zařízení SPARE, automaticky se připojí k poškozenému zařízení vdev.
Po připojení k poškozenému zařízení vdev začne zařízení SPARE přijímat kopie nebo rekonstrukce dat, která by měla být na chybějícím zařízení. V tradičním systému RAID by se tomu říkalo „přestavba“ – v systému ZFS se tomu říká „obnovení stříbra“.
Je důležité si uvědomit, že zařízení SPARE nenahrazují selhané zařízení natrvalo. Jsou to pouze zástupná zařízení, jejichž účelem je minimalizovat okno, během něhož vdevběží znehodnocené zařízení. Jakmile správce nahradí selhané zařízení vdev a nové, trvale nahrazující zařízení se obnoví, SPARE se odpojí od vdev a vrátí se k práci v celém poolu.
Datové sady, bloky a sektory
Další sada stavebních kamenů, kterým budete muset na své cestě ZFS porozumět, se netýká ani tak hardwaru, ale toho, jak jsou organizována a ukládána samotná data. Přeskočíme zde několik úrovní – například metasystém – v zájmu co největší jednoduchosti a zároveň pochopení celkové struktury.
Datové sady
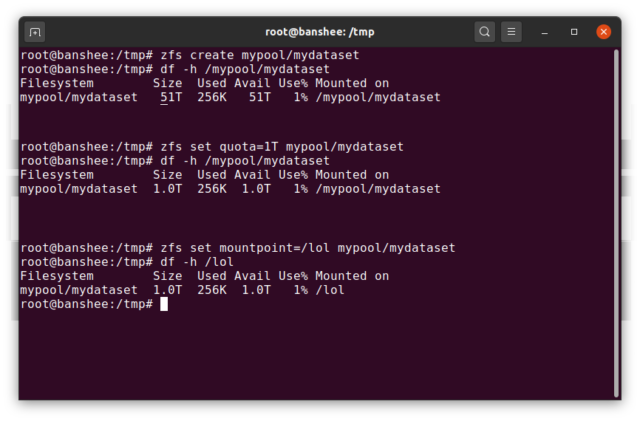

Systém ZFS dataset je zhruba obdobou standardního připojeného souborového systému – podobně jako běžný souborový systém se při náhodném pohledu jeví, jako by to byla „jen další složka“. Ale stejně jako běžné připojené souborové systémy má i každý systém souborů ZFS dataset vlastní sadu základních vlastností.
V první řadě může mít systém dataset přiřazenou kvótu. Pokud zfs set quota=100G poolname/datasetname, nebudete moci do systémově připojené složky /poolname/datasetname umístit více než 100 GB dat.
Všimli jste si přítomnosti – a nepřítomnosti – úvodních lomítek ve výše uvedeném příkladu? Každá datová sada má své místo jak v hierarchii systému ZFS, tak v hierarchii systémového připojení. V hierarchii systému ZFS není žádné úvodní lomítko – začínáte názvem fondu a pak cestou od jedné sady dat k další – např. pool/parent/child pro sadu dat s názvem child pod nadřazenou sadou dat parent v fondu s kreativním názvem pool.
Ve výchozím nastavení bude přípojný bod dataset odpovídat jeho hierarchickému názvu v systému ZFS s počátečním lomítkem – pool s názvem pool bude připojen na /pool, dataset parent bude připojen na /pool/parent a podřízený dataset child bude připojen na /pool/parent/child. Systémový přípojný bod datové sady však může být změněn.
Pokud bychom zfs set mountpoint=/lol pool/parent/child, datová sada pool/parent/child by byla ve skutečnosti v systému připojena jako /lol.
Kromě datových sad bychom měli zmínit zvols. zvol je zhruba obdobou dataset, až na to, že v něm ve skutečnosti není souborový systém – je to jen blokové zařízení. Můžete například vytvořit zvol s názvem mypool/myzvol, pak jej naformátovat souborovým systémem ext4 a tento souborový systém připojit – nyní máte souborový systém ext4, ale podpořený všemi bezpečnostními funkcemi systému ZFS! Na jednom počítači to může znít hloupě – ale jako zázemí pro export iSCSI to dává mnohem větší smysl.
Bloky
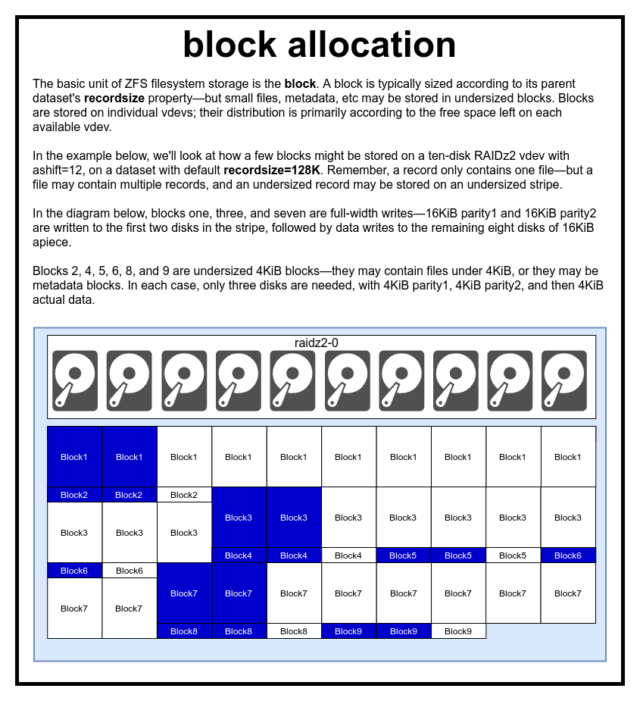

V souboru ZFS jsou všechna data – včetně metadat – uložena v blocks. Maximální velikost block je definována pro každý dataset ve vlastnosti recordsize. Velikost záznamu je proměnlivá, ale změna recordsize nezmění velikost ani rozložení žádného blocks, který již byl do datové sady zapsán, pouze pro nové bloky při jejich zápisu.
Pokud není definováno jinak, je aktuální výchozí recordsize 128KiB. To představuje jakýsi nelehký kompromis, kdy výkon nebude ideální pro mnoho věcí, ale nebude ani hrozný pro mnoho věcí. Recordsize lze nastavit na libovolnou hodnotu od 4K do 1M. (Recordsize lze při dodatečném ladění a dostatečném odhodlání nastavit i větší, ale málokdy je to dobrý nápad.)
Každý daný block odkazuje na data pouze z jednoho souboru – do jednoho block nelze nacpat dva různé soubory. Každý soubor se bude skládat z jednoho nebo více blocks, v závislosti na velikosti. Pokud je soubor menší než recordsize, bude uložen v bloku s nedostatečnou velikostí – například block obsahující 2KiB soubor bude na disku zabírat pouze jeden 4KiB sector.
Je-li soubor dostatečně velký, aby vyžadoval více blocks, všechny záznamy obsahující tento soubor budou mít délku recordsize – včetně posledního záznamu, který může být většinou volným místem.
Zvols nemají vlastnost recordsize – místo toho mají volblocksize, což je zhruba ekvivalentní.
Sektory
Posledním stavebním prvkem, o kterém je třeba diskutovat, je nízký sector. sector je nejmenší fyzická jednotka, kterou lze zapsat nebo přečíst z jejího podkladového device. Po několik desetiletí se na většině disků používaly 512bajtové sectors. V poslední době většina disků používá 4KiB sectors a některé – zejména SSD – používají 8KiB sectors nebo dokonce větší.
ZFS má vlastnost, která umožňuje ručně nastavit velikost sector, nazvanou ashift. Poněkud matoucí je, že ashift je ve skutečnosti binární exponent, který představuje velikost sektoru – například nastavení ashift=9 znamená, že velikost sector bude 2^9, tedy 512 bajtů.
ZFS se dotazuje operačního systému na podrobnosti o každém bloku device při jeho přidávání do nového vdev a teoreticky na základě těchto informací automaticky správně nastaví ashift. Bohužel existuje mnoho disků, které skrze zuby lžou o tom, jaká je jejich velikost sector, aby zůstaly kompatibilní se systémem Windows XP (který nebyl schopen pochopit disky s jinou velikostí sector).
To znamená, že správci systému ZFS se důrazně doporučuje, aby si byl vědom skutečné velikosti sector svého devices a podle toho ručně nastavil ashift. Pokud je ashift nastaven příliš nízko, dochází k astronomickému zesílení čtení/zápisu – zápis 512bajtových „sektorů“ do 4KiB skutečného sector znamená, že je nutné zapsat první „sektor“, pak přečíst 4KiB sector, upravit jej druhým 512bajtovým „sektorem“, zapsat jej zpět do *nového* 4KiB sector a tak dále při každém jednotlivém zápisu.
V reálném světě tento postih za zesílení zasáhne SSD disk Samsung EVO – který by měl mít ashift=13, ale lže o své velikosti sektoru, a proto je výchozí hodnota ashift=9, pokud ji bystrý správce nepřepsal – natolik tvrdě, že se zdá být pomalejší než běžný rezavý disk.
Naproti tomu nastavení příliš vysoké hodnoty ashift není prakticky nijak postihováno. Neexistuje žádný skutečný výkonnostní postih a nárůst volného místa je nekonečně malý (nebo nulový, při zapnuté kompresi). Důrazně doporučujeme, aby i disky, které skutečně používají 512bajtové sektory, byly nastaveny na ashift=12 nebo dokonce ashift=13 z důvodu zabezpečení do budoucna.
Vlastnost ashift je pro-vdev – nikoli pro pool, jak se běžně a mylně soudí!- a je po nastavení neměnná. Pokud při přidávání nového vdev do poolu omylem pokazíte ashift, nenávratně jste tento pool kontaminovali drasticky nevýkonným vdev a obecně nemáte jinou možnost, než pool zničit a začít znovu. Ani odstranění vdev vás nezachrání před chybným nastavením ashift!
Sémantika kopírování při zápisu




CoW – kopírování při zápisu – je základním podkladem většiny toho, co dělá ZFS úžasným. Základní koncept je jednoduchý – pokud požádáte tradiční souborový systém, aby upravil soubor na místě, udělá přesně to, o co jste ho požádali. Pokud požádáte souborový systém copy-on-write, aby udělal totéž, řekne „v pořádku“ – ale lže vám.
Místo toho souborový systém copy-on-write vypíše novou verzi block, kterou jste upravili, a pak aktualizuje metadata souboru, aby zrušil odkaz na starý block a propojil nový block, který jste právě napsali.
Odpojení starého block a připojení nového se provede během jediné operace, takže ji nelze přerušit – pokud zahodíte napájení až poté, co se tak stane, máte novou verzi souboru, a pokud zahodíte napájení předtím, máte starou verzi. Tak jako tak jste vždy konzistentní se souborovým systémem.
Kopírování při zápisu v systému ZFS není jen na úrovni souborového systému, ale také na úrovni správy disků. To znamená, že díra RAID – stav, kdy se před pádem systému zapíše jen část proužku, takže pole je po restartu nekonzistentní a poškozené – se systému ZFS netýká. Zápisy do proužků jsou atomické, vdev je vždy konzistentní a Bob je váš strýček.
ZIL-the ZFS Intent Log
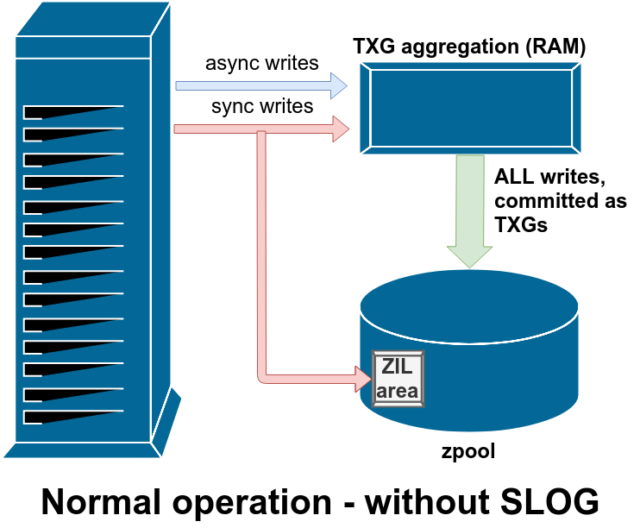

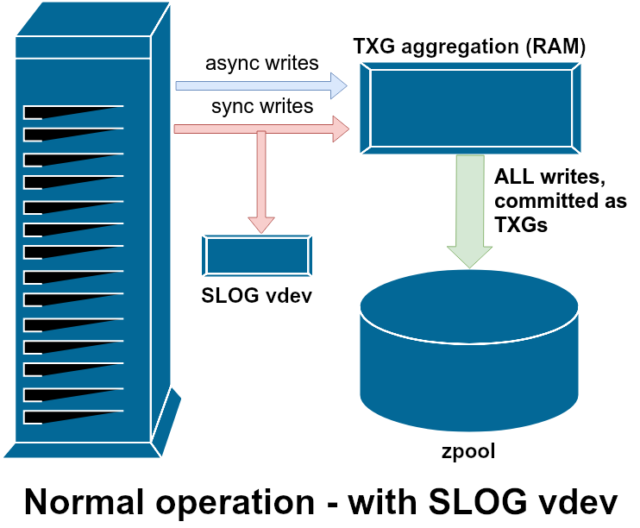

Existují dvě hlavní kategorie operací zápisu – synchronní (sync) a asynchronní (async). Pro většinu pracovních zátěží je naprostá většina operací zápisu asynchronní – souborový systém je může agregovat a zapisovat v dávkách, což snižuje fragmentaci a ohromně zvyšuje propustnost.
Synchronní zápisy jsou úplně jiné zvíře – když aplikace požaduje synchronní zápis, říká souborovému systému „musíš to teď zapsat do nevolatilního úložiště, a dokud to neuděláš, nemůžu dělat nic jiného“. Synchronizační zápisy proto musí být na disk odevzdány okamžitě – a pokud to zvýší fragmentaci nebo sníží propustnost, budiž.
ZFS zpracovává synchronizační zápisy jinak než běžné souborové systémy – místo aby synchronizační zápisy okamžitě vyplavil do normálního úložiště, ZFS je odevzdává do speciální oblasti úložiště zvané ZFS Intent Log neboli ZIL. Vtip je v tom, že tyto zápisy také zůstávají v paměti a jsou agregovány spolu s normálními asynchronními požadavky na zápis, aby byly později vyplaveny do úložiště jako zcela normální TXG (Transaction Groups).
Při běžném provozu se do ZIL zapisuje a už se z něj nikdy nečte. Když jsou zápisy uložené do ZIL o několik okamžiků později odevzdány do hlavního úložiště z paměti RAM v normálních TXG, jsou ze ZIL odpojeny. Jediný případ, kdy se ze ZIL čte, je při importu fondu.
Pokud dojde k pádu systému ZFS – nebo k pádu operačního systému, nebo k neošetřenému výpadku napájení – v době, kdy jsou v ZIL data, budou tato data přečtena při dalším importu fondu (např. při restartu havarovaného systému). Cokoli je v ZIL, bude načteno, agregováno do TXG, zapsáno do hlavního úložiště a poté odpojeno od ZIL během procesu importu.
Jednou z dostupných tříd podpory vdev je LOG – známá také jako SLOG neboli sekundární LOG zařízení. Jediné, co SLOG dělá, je, že poskytuje fondu samostatné – a doufejme, že mnohem rychlejší, s velmi vysokou odolností proti zápisu – vdev, do kterého se ukládají ZIL, místo aby se ZIL uchovávaly v hlavním úložišti vdevs. Ve všech ohledech se ZIL chová stejně, ať už je na hlavním úložišti, nebo na LOG vdev – ale pokud má LOG vdev velmi vysokou výdrž zápisu, pak bude synchronizace návratů zápisu probíhat velmi rychle.
Přidání LOG vdev do poolu absolutně nemůže přímo zlepšit výkon asynchronního zápisu a ani ho nezlepší – i když vynutíte všechny zápisy do ZIL pomocí zfs set sync=always, stále se odevzdávají do hlavního úložiště v TXG stejným způsobem a stejným tempem, jako by se odevzdávaly bez LOG. Jediné přímé zlepšení výkonu se týká latence synchronního zápisu (protože větší rychlost LOG umožňuje rychlejší návrat volání sync).
V prostředí, které již vyžaduje hodně synchronních zápisů, však může LOG vdev nepřímo urychlit i asynchronní zápisy a čtení bez keše. Přenesení zápisů ZIL na samostatné LOG vdev znamená menší nároky na IOPS na primárním úložišti, čímž se do určité míry zvýší výkon pro všechna čtení a zápisy.
Snímky
Sémantika kopírování při zápisu je také nezbytným základem pro atomické snímky ZFS a inkrementální asynchronní replikaci. Živý souborový systém má strom ukazatelů označujících všechna records, která obsahují aktuální data – když pořídíte snímek, jednoduše vytvoříte kopii tohoto stromu ukazatelů.
Pokud je záznam v živém souborovém systému přepsán, ZFS nejprve zapíše novou verzi block do nepoužívaného prostoru. Poté zruší propojení staré verze block s aktuálním souborovým systémem. Pokud však nějaký snapshot odkazuje na starý block, zůstává stále neměnný. Starý block nebude ve skutečnosti obnoven jako volné místo, dokud nebudou zničeny všechny snapshots odkazující na tento block!“
Replikace

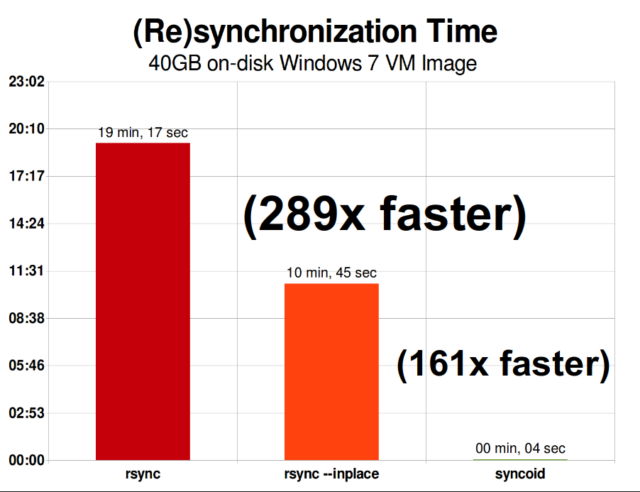
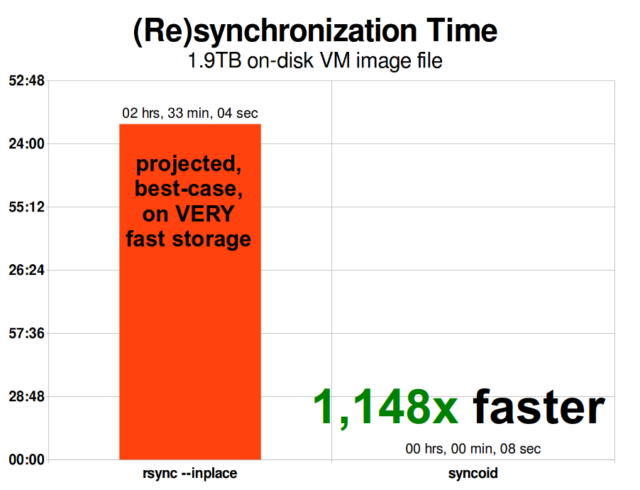 Jakmile pochopíte, jak snímky fungují, jste na dobré cestě pochopit replikaci. Protože snapshot je jednoduše strom ukazatelů na
Jakmile pochopíte, jak snímky fungují, jste na dobré cestě pochopit replikaci. Protože snapshot je jednoduše strom ukazatelů narecords, vyplývá z toho, že pokudzfs sendposíláme snapshot, posíláme jak tento strom, tak všechny související záznamy. Když tento
zfs sendpřeneseme dozfs receivena cíli, zapíše se do cílového datasetu jak skutečný obsahblock, tak strom ukazatelů odkazujících nablocks.
Ve druhém zfs send začnou být věci zajímavější. Nyní, když máte dva systémy, z nichž každý obsahuje snímek poolname/datasetname@1, můžete vytvořit nový snímek poolname/datasetname@2. Takže ve zdrojovém fondu máte datasetname@1 a datasetname@2 a v cílovém fondu máte zatím jen první snapshot – datasetname@1.
Protože máme společný snapshot mezi zdrojovým a cílovým fondem – datasetname@1 – můžeme nad ním vytvořit inkrementální zfs send. Když požádáme systém o zfs send -i poolname/datasetname@1 poolname/datasetname@2, porovná oba stromy ukazatelů. Všechny ukazatele, které existují pouze v @2, zřejmě odkazují na nový blocks – budeme tedy potřebovat i obsah těchto blocks.
Ve vzdáleném systému je vložení výsledného inkrementálního send do potrubí podobně snadné. Nejprve vypíšeme všechny nové records obsažené v proudu send a poté přidáme ukazatele na tyto blocks. Presto, máme @2 v novém systému!“
Asynchronní inkrementální replikace systému ZFS je obrovským zlepšením oproti dřívějším technikám, které nebyly založeny na snímcích, jako například rsync. V obou případech je třeba po drátě poslat pouze změněná data – ale rsync musí nejprve přečíst všechna data z disku, a to na obou stranách, aby bylo možné provést kontrolní součet a porovnání. Naproti tomu replikace ZFS nepotřebuje číst nic jiného než stromy ukazatelů – a všechny blocks, které tento strom ukazatelů obsahuje a které již nebyly přítomny ve společném snímku.
Inline komprese
Sémantika kopírování při zápisu také usnadňuje nabídku inline komprese. U tradičního souborového systému nabízejícího modifikaci na místě je komprese problematická – stará i nová verze modifikovaných dat se musí vejít do přesně stejného prostoru.
Pokud vezmeme v úvahu kus dat uprostřed souboru, který začíná svůj život jako 1MiB nul-0x00000000 ad nauseam – velmi snadno by se zkomprimoval na jeden sektor disku. Co se však stane, pokud tento 1MiB nul nahradíme 1MiB nekomprimovatelných dat, jako je JPEG nebo pseudonáhodný šum? Najednou tento 1MiB dat potřebuje 256 4KiB sektorů, ne jen jeden – a díra uprostřed souboru je široká jen jeden sektor.
ZFS tento problém nemá, protože modifikované záznamy se vždy zapisují do nevyužitého prostoru – původní block zabírá pouze jeden 4KiB sector a nový záznam jich zabírá 256, ale to není problém – nově modifikovaný kus ze „středu“ souboru by byl zapsán do nevyužitého prostoru, ať už by se jeho velikost změnila nebo ne, takže pro ZFS je tento „problém“ jen dalším dnem v kanceláři.
Souborový systém ZFS má ve výchozím nastavení vypnutou inline kompresi a nabízí připojitelné algoritmy – v současné době včetně LZ4, gzip (1-9), LZJB a ZLE.
- LZ4 je proudový algoritmus, který nabízí extrémně rychlou kompresi a dekompresi a je výkonnostní výhrou pro většinu případů použití – dokonce i pro velmi chudokrevné procesory.
- GZIP je úctyhodný algoritmus, který znají a milují všichni uživatelé systémů podobných Unixu. Lze jej implementovat s úrovněmi komprese 1-9, přičemž s úrovní 9 roste kompresní poměr a využití procesoru. Gzip může být vítězstvím pro čistě textové (nebo jinak extrémně komprimovatelné) případy použití, ale jinak často vede k úzkému hrdlu procesoru – používejte opatrně, zejména při vyšších úrovních.
- LZJB je původní algoritmus používaný systémem ZFS. Je zastaralý a neměl by se již používat – LZ4 je lepší ve všech parametrech.
- ZLE je Zero Level Encoding (kódování na nulové úrovni) – ponechává normální data zcela na pokoji, ale komprimuje velké sekvence nul. Hodí se pro zcela nekomprimovatelné datové sady (např. JPEG, MP4 nebo jiné již komprimované formáty), protože ignoruje nekomprimovatelná data, ale komprimuje volné místo na konečných záznamech.
Kompresi LZ4 doporučujeme téměř pro všechny myslitelné případy použití; výkonnostní postih při setkání s nekomprimovatelnými daty je velmi malý a nárůst výkonu pro typická data je významný. Kopírování obrazu virtuálního počítače pro novou instalaci operačního systému Windows (pouze nainstalovaný operační systém Windows, žádná data na něm zatím nejsou) proběhlo v tomto testu z roku 2015 o 27 % rychleji s compression=lz4 než s compression=none.
ARC – Adaptive Replacement Cache
ZFS je jediný moderní souborový systém, o kterém víme, že používá vlastní mechanismus mezipaměti pro čtení, místo aby se spoléhal na mezipaměť stránek operačního systému, která pro něj uchovává kopie nedávno přečtených bloků v paměti RAM.
Ačkoli má samostatný mechanismus mezipaměti své problémy – systém ZFS nemůže reagovat na nové požadavky na alokaci paměti tak okamžitě jako jádro, a proto může nové mallocate()volání selhat, pokud by potřebovalo paměť RAM, kterou právě zabírá ARC – existuje dobrý důvod, proč se s ním alespoň prozatím smířit.
Všechny známé moderní operační systémy – včetně MacOS, Windows, Linuxu a BSD – používají pro implementaci mezipaměti stránek algoritmus LRU (Least Recently Used). LRU je naivní algoritmus, který při každém čtení posouvá blok mezipaměti na „vrchol“ fronty a podle potřeby vyřazuje bloky ze „spodku“ fronty, aby se na „vrchol“ přidaly nové chybějící bloky mezipaměti (bloky, které musely být přečteny z disku, nikoli z mezipaměti).“
To je zatím v pořádku, ale v systémech s velkými pracovními soubory dat může LRU snadno skončit „thrashingem“ – evikováním velmi často potřebných bloků, aby se uvolnilo místo pro bloky, které se už nikdy nebudou číst z cache.
Arc je mnohem méně naivní algoritmus, který si lze představit jako „váženou“ cache. Pokaždé, když je blok v mezipaměti přečten, stává se o něco „těžším“ a obtížněji evikovatelným – a i po evikci je evikovaný blok po určitou dobu sledován. Blok, který byl evikován, ale poté musí být znovu načten do mezipaměti, se také stane „těžším“ a obtížněji evikovatelným.
Konečným výsledkem toho všeho je mezipaměť s obvykle mnohem větším poměrem zásahů – poměrem mezi zásahy do mezipaměti (čtení obsluhovaná z mezipaměti) a ztrátami mezipaměti (čtení obsluhovaná z disku). To je nesmírně důležitá statistika – nejenže jsou samotné hity cache obslouženy řádově rychleji, ale také misses cache mohou být obslouženy rychleji, protože více hitů cache = méně souběžných požadavků na disk = nižší latence pro ty zbývající misses, které musí být obslouženy z disku.
Závěr
Teď, když jsme probrali základní sémantiku systému ZFS – jak funguje kopírování při zápisu a vztahy mezi pooly, vdev, bloky, sektory a soubory – jsme připraveni mluvit o skutečném výkonu s reálnými čísly.
Zůstaňte naladěni na další díl našeho seriálu o základech úložiště, ve kterém se podíváme na skutečný výkon zaznamenaný v poolech využívajících zrcadlení a vdev RAIDz, a to ve srovnání jak mezi sebou, tak s tradičními topologiemi RAID linuxového jádra, které jsme zkoumali dříve.
Nejprve se budeme věnovat pouze základům – samotným topologiím ZFS – ale poté budeme připraveni probrat pokročilejší nastavení a ladění ZFS, včetně použití podpůrných typů vdev, jako jsou L2ARC, SLOG a Special Allocation.
.