
Når vi alle går ind i den tredje måned af COVID-19-pandemien og leder efter nye projekter, der kan holde os beskæftiget (læs: fornuftige), kan vi så interessere dig for at lære de grundlæggende principper for computerlagring? Stille og roligt i foråret har vi allerede gennemgået nogle nødvendige grundlæggende ting som f.eks. hvordan man tester hastigheden på sine diske, og hvad pokker RAID er. I den anden af disse historier lovede vi endda en opfølgning, hvor vi udforskede ydelsen af forskellige topologier med flere diske i ZFS, det næste generations filsystem, som du har hørt om, fordi det optræder overalt fra Apple til Ubuntu.
Nå, men i dag er det dagen til at udforske, ZFS-nysgerrige læsere. Du skal bare vide på forhånd, at med OpenZFS-udvikler Matt Ahrens’ underspillede ord: “Det er virkelig kompliceret.”
Men før vi kommer til tallene – og de kommer, det lover jeg!-for alle de måder, du kan forme otte diske med ZFS på, er vi nødt til at tale om, hvordan ZFS overhovedet gemmer dine data på disken.
Zpools, vdevs og enheder
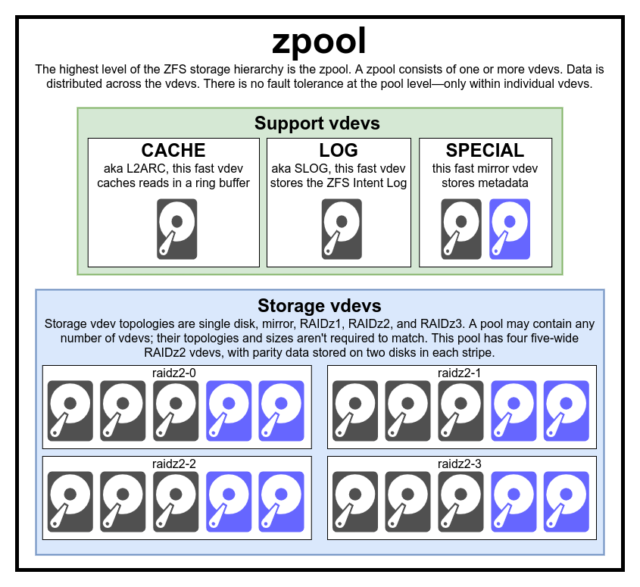

For virkelig at forstå ZFS skal du være rigtig opmærksom på den faktiske struktur. ZFS fusionerer de traditionelle lag for volumenhåndtering og filsystemer, og det bruger en copy-on-write-transaktionsmekanisme – begge dele betyder, at systemet strukturelt set er meget anderledes end konventionelle filsystemer og RAID-arrays. Det første sæt større byggeblokke, som man skal forstå, er zpools, vdevs og devices.
zpool
Den zpool er den øverste ZFS-struktur. En zpool indeholder en eller flere vdevs, som hver især igen indeholder en eller flere devices. Zpools er selvstændige enheder – en fysisk computer kan have to eller flere separate zpools på den, men hver enkelt er helt uafhængig af alle andre. Zpools kan ikke dele vdevs med hinanden.
ZFS-redundans er på vdev-niveauet, ikke på zpool-niveauet. Der er absolut ingen redundans på zpool-niveauet – hvis en lager vdev eller SPECIAL vdev går tabt, går hele zpool tabt sammen med den.
Moderne zpools kan overleve tabet af en CACHE eller LOG vdev – selvom de kan miste en lille mængde beskidte data, hvis de mister en LOG vdev under en strømafbrydelse eller et systemnedbrud.
Det er en udbredt misforståelse, at ZFS “striber” skrivninger på tværs af poolen – men dette er unøjagtigt. En zpool er ikke et sjovt udseende RAID0 – det er en sjovt udseende JBOD, med en kompleks fordelingsmekanisme, der kan ændres.
For det meste fordeles skrivninger over tilgængelige vdevs i overensstemmelse med deres tilgængelige frie plads, så alle vdevs teoretisk set bliver fulde på samme tid. I nyere versioner af ZFS kan der også tages hensyn til vdev-anvendelse – hvis en vdev er betydeligt mere travl end en anden (f.eks. på grund af læsebelastning), kan den midlertidigt springes over til skrivning på trods af, at den har det højeste forhold af ledig plads til rådighed.
Mekanismen til bevidsthed om udnyttelsen, der er indbygget i moderne ZFS-skrivefordelingsmetoder, kan mindske latenstiden og øge gennemstrømningen i perioder med usædvanlig høj belastning – men den bør ikke forveksles med en carte blanche til at blande langsomme rustdiske og hurtige SSD’er vilkårligt i den samme pulje. En sådan uoverensstemmende pool vil generelt stadig fungere, som om den udelukkende bestod af den langsomste tilstedeværende enhed.
vdev
Hver zpool består af en eller flere vdevs(forkortelse for virtuel enhed). Hver vdev består på sin side af en eller flere reelle devices. De fleste vdev’er bruges til almindelig lagring, men der findes også flere specielle understøttelsesklasser af vdev’er – herunder CACHE, LOG og SPECIAL. Hver af disse vdev-typer kan tilbyde en af fem topologier – single-device, RAIDz1, RAIDz2, RAIDz3 eller mirror.
RAIDz1, RAIDz2 og RAIDz3 er særlige varianter af det, som lagringsgråskerne kalder “diagonal paritets-RAID”. 1, 2 og 3 henviser til, hvor mange paritetsblokke der er allokeret til hver datastribe. I stedet for at have hele diske dedikeret til paritet, fordeler RAIDz vdevs denne paritet halvt jævnt over diskene. Et RAIDz-array kan miste lige så mange diske, som det har paritetsblokke; hvis det mister endnu en, fejler det og tager zpool med sig ned.
Mirror vdev’er er præcis, hvad de lyder som – i en mirror vdev er hver blok gemt på hver enhed i vdev’en. Selv om to brede spejlinger er de mest almindelige, kan en mirror vdev indeholde et vilkårligt antal enheder – trevejsspejlinger er almindelige i større opsætninger på grund af den højere læseydelse og fejlmodstandsdygtighed. En mirror vdev kan overleve enhver fejl, så længe mindst én enhed i vdev’en forbliver sund.
Single-devdev’er er også lige hvad de lyder som – og de er i sagens natur farlige. En vdev med en enkelt enhed kan ikke overleve nogen fejl – og hvis den bruges som en lager- eller SPECIAL vdev, vil dens fejl tage hele zpool ned med den. Vær meget, meget forsigtig her.
CACHE, LOG og SPECIAL vdev’er kan oprettes ved hjælp af en hvilken som helst af ovenstående topologier – men husk, at tab af en SPECIAL vdev betyder tab af puljen, så redundant topologi anbefales kraftigt.
device
Dette er nok det letteste ZFS-relaterede begreb at forstå – det er bogstaveligt talt bare en random-access blok-enhed. Husk, vdevs er lavet af individuelle enheder, og zpool er lavet af vdevs.
Diske – enten rust eller solid-state – er de mest almindelige blok-enheder, der bruges som vdev-byggeblokke. Alt med en deskriptor i /dev, der tillader tilfældig adgang, vil dog fungere, så hele hardware-RAID-arrays kan bruges (og bruges nogle gange) som individuelle enheder.
Den simple råfil er en af de vigtigste alternative blok-enheder, som en vdev kan bygges ud fra. Testpools lavet af sparsomme filer er en utrolig praktisk måde at øve sig i zpool-kommandoer og se, hvor meget plads der er tilgængelig på en pool eller vdev med en given topologi.

Lad os sige, at du overvejer at bygge en server med otte bugter og er ret sikker på, at du vil bruge 10 TB (~9300 GiB) diske – men du er ikke sikker på, hvilken topologi der passer bedst til dine behov. I ovenstående eksempel opbygger vi en testpulje ud fra sparsomme filer på få sekunder – og nu ved vi, at en RAIDz2 vdev bestående af otte 10 TB diske giver 50 TiB anvendelig kapacitet.
Der er en særlig klasse af device – SPARE. Hotspare-enheder hører i modsætning til normale enheder til hele puljen, ikke til en enkelt vdev. Hvis en vdev i puljen lider af en enhedsfejl, og en SPARE er knyttet til puljen og er tilgængelig, vil SPARE automatisk knytte sig til den nedbrudte vdev.
Når den er knyttet til den nedbrudte vdev, begynder SPARE at modtage kopier eller rekonstruktioner af de data, der skulle være på den manglende enhed. I traditionelt RAID ville dette blive kaldt “genopbygning” – i ZFS kaldes det “resilvering”.”
Det er vigtigt at bemærke, at SPARE-enheder ikke permanent erstatter fejlbehæftede enheder. De er blot stedholdere, der er beregnet til at minimere det vindue, hvor en vdev kører nedbrudt. Når administratoren har erstattet vdev’ens fejlslagne enhed, og den nye, permanente erstatningsenhed resilveres, løsriver SPARE sig selv fra vdev’en og vender tilbage til tjeneste i hele poolen.
Datasæt, blokke og sektorer
Det næste sæt byggeklodser, du skal forstå på din ZFS-rejse, vedrører ikke så meget hardwaren, men hvordan selve dataene organiseres og lagres. Vi springer nogle få niveauer over her – f.eks. metaslab – for at holde tingene så enkle som muligt, men stadig forstå den overordnede struktur.
Datasæt
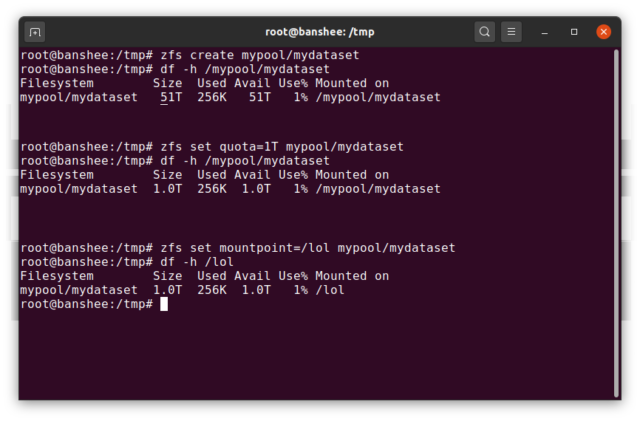

En ZFS dataset svarer nogenlunde til et standard, monteret filsystem – som et konventionelt filsystem ser det ved en tilfældig inspektion ud, som om det er “bare endnu en mappe”. Men ligesom konventionelle monterede filsystemer har hver ZFS dataset også sit eget sæt af underliggende egenskaber.
Først og fremmest kan en dataset have en kvote tildelt den. Hvis du zfs set quota=100G poolname/datasetname, vil du ikke kunne lægge mere end 100 GB data i den systemmonterede mappe /poolname/datasetname.
Bemærker du tilstedeværelsen – og fraværet – af ledende skråstreger i ovenstående eksempel? Hvert datasæt har sin plads i både ZFS-hierarkiet og i systemets monteringshierarki. I ZFS-hierarkiet er der ingen ledende skråstreger – du begynder med poolens navn og derefter stien fra et datasæt til det næste – f.eks. pool/parent/child for et datasæt ved navn child under det overordnede datasæt parent i en pool, der har fået det kreative navn pool.
Som standard vil monteringspunktet for et dataset svare til dets ZFS-hierarkiske navn, med en ledende skråstreg – puljen med navnet pool er monteret på /pool, datasæt parent er monteret på /pool/parent, og underordnede datasæt child er monteret på /pool/parent/child. Systemets mountpoint for et datasæt kan dog ændres.
Hvis vi zfs set mountpoint=/lol pool/parent/child, ville datasættet pool/parent/child faktisk blive monteret på systemet som /lol.
Ud over datasæt bør vi også nævne zvols. En zvol svarer nogenlunde til en dataset, bortset fra at den faktisk ikke har et filsystem i den – det er bare en blokanordning. Du kan f.eks. oprette en zvol med navnet mypool/myzvol, derefter formatere den med ext4-filsystemet og derefter montere dette filsystem – du har nu et ext4-filsystem, men med alle ZFS’ sikkerhedsfunktioner i ryggen! Dette lyder måske fjollet på en enkelt computer – men det giver meget mere mening som backend for en iSCSI-eksport.
Blokke
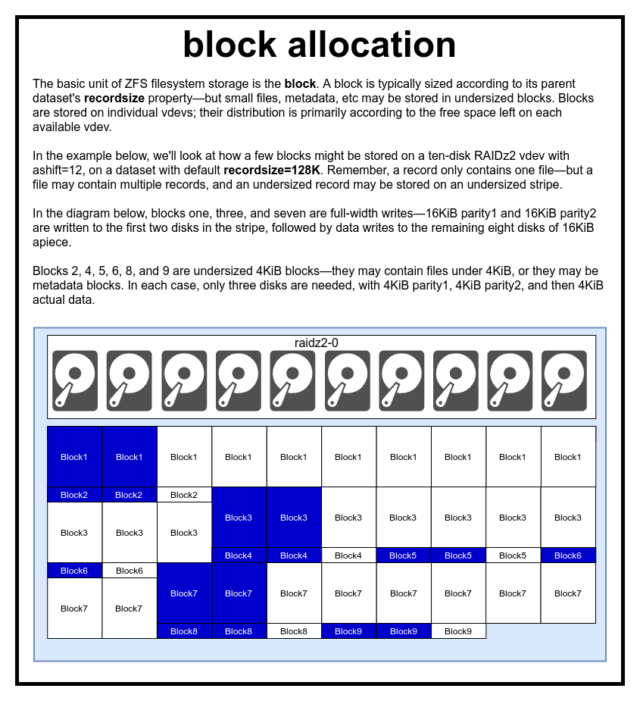

I en ZFS-pool gemmes alle data – inklusive metadata – i blocks. Den maksimale størrelse af en block er defineret for hver dataset i recordsize-egenskaben. Recordsize kan ændres, men en ændring af recordsize ændrer ikke størrelsen eller layoutet af blocks, der allerede er blevet skrevet til datasættet – kun for nye blokke, efterhånden som de skrives.
Hvis ikke andet er defineret, er den aktuelle standard recordsize 128KiB. Dette repræsenterer en slags ubehageligt kompromis, hvor ydeevnen ikke vil være ideel for meget af noget, men heller ikke vil være forfærdelig for meget af noget. Recordsize kan indstilles til en hvilken som helst værdi fra 4K til 1M. (Recordsize kan sættes endnu større med yderligere tuning og tilstrækkelig beslutsomhed, men det er sjældent en god idé.)
En given block refererer kun til data fra én fil – du kan ikke proppe to separate filer ind i den samme block. Hver fil vil bestå af en eller flere blocks, afhængigt af størrelsen. Hvis en fil er mindre end recordsize, vil den blive gemt i en underdimensioneret blok – f.eks. vil en block, der indeholder en 2KiB fil, kun fylde en enkelt 4KiB sector på disken.
Hvis en fil er stor nok til at kræve flere blocks, vil alle poster, der indeholder filen, være recordsize lange – inklusive den sidste post, som for det meste kan bestå af ledig plads.
Zvols har ikke recordsize-egenskaben – i stedet har de volblocksize, hvilket er nogenlunde tilsvarende.
Sektorer
Den sidste byggesten, der skal diskuteres, er den lavværdige sector. En sector er den mindste fysiske enhed, der kan skrives til eller læses fra sin underliggende device. I flere årtier brugte de fleste diske 512 byte sectors. I nyere tid bruger de fleste diske 4KiB sectors, og nogle – især SSD’er – bruger 8KiB sectors eller endnu større.
ZFS har en egenskab, som giver dig mulighed for manuelt at indstille sector-størrelsen, kaldet ashift. Lidt forvirrende nok er ashift faktisk den binære eksponent, der repræsenterer sektorstørrelsen – hvis du f.eks. indstiller ashift=9, betyder det, at din sector-størrelse bliver 2^9 eller 512 bytes.
ZFS forespørger operativsystemet om detaljer om hver blok device, når den tilføjes til en ny vdev, og vil i teorien automatisk indstille ashift korrekt på baggrund af disse oplysninger. Desværre er der mange diske, der lyver gennem tænderne om, hvad deres sector-størrelse er, for at forblive kompatible med Windows XP (som var ude af stand til at forstå diske med en anden sector-størrelse).
Det betyder, at en ZFS-administrator stærkt anbefales at være opmærksom på den faktiske sector-størrelse på sin devices og manuelt indstille ashift i overensstemmelse hermed. Hvis ashift er indstillet for lavt, påføres en astronomisk læse-/skriveforstærkningsstraf – at skrive en 512 byte “sektorer” til en 4KiB reel sector betyder, at man skal skrive den første “sektor”, derefter læse 4KiB sector, ændre den med den anden 512 byte “sektor”, skrive den tilbage til en *ny* 4KiB sector osv. for hver eneste skrivning.
I den virkelige verden rammer denne forstærkningsstraf en Samsung EVO SSD – som burde have ashift=13, men som lyver om sin sektorstørrelse og derfor er standardiseret til ashift=9, hvis den ikke tilsidesættes af en klog administrator – hårdt nok til at få den til at fremstå langsommere end en konventionel rustdisk.
Derimod er der stort set ingen straf ved at indstille ashift for højt. Der er ingen reel ydelsesstraf, og stigningen i slack space er uendelig lille (eller nul, hvis komprimering er aktiveret). Vi anbefaler på det kraftigste, at selv diske, der virkelig bruger 512 byte sektorer, bør indstilles ashift=12 eller endda ashift=13 for at fremtidssikre sig.
Egenskaben ashift er per-vdev-ikke per pool, som man almindeligvis og fejlagtigt tror!-og den er uforanderlig, når den først er indstillet. Hvis du ved et uheld fejlbehandler ashift, når du tilføjer en ny vdev til en pool, har du uigenkaldeligt forurenet denne pool med en drastisk underpræsterende vdev, og du har generelt ingen anden udvej end at ødelægge poolen og starte forfra. Selv fjernelse af vdev kan ikke redde dig fra en fejlslagen ashift-indstilling!
Copy-on-Write-semantik




CoW-Copy on Write-er en grundlæggende underbygning under det meste af det, der gør ZFS fantastisk. Det grundlæggende koncept er simpelt – hvis du beder et traditionelt filsystem om at ændre en fil på stedet, gør det præcis, hvad du bad det om. Hvis du beder et copy-on-write-filsystem om at gøre det samme, siger det “okay” – men det lyver for dig.
I stedet skriver copy-on-write-filsystemet en ny version af den block, du har ændret, og opdaterer derefter filens metadata for at fjerne linket til den gamle block og linke til den nye block, du lige har skrevet.
Den gamle block afbrydes i en enkelt operation, så den kan ikke afbrydes – hvis du afbryder strømmen, efter at det er sket, har du den nye version af filen, og hvis du afbryder strømmen før, har du den gamle version. Du er altid filsystemkonsistent, uanset hvad.
Copy-on-write i ZFS er ikke kun på filsystemniveau, det er også på diskhåndteringsniveau. Det betyder, at RAID-hullet – en tilstand, hvor en stribe kun er delvist skrevet, før systemet går ned, hvilket gør arrayet inkonsekvent og korrupt efter en genstart – ikke påvirker ZFS. Stripe-skrivninger er atomare, vdev’en er altid konsistent, og Bob er din onkel.
ZIL-the ZFS Intent Log
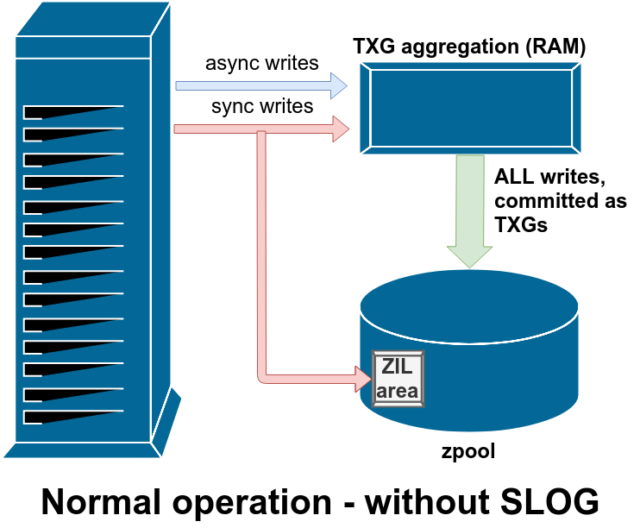


Der er to hovedkategorier af skriveoperationer – synkrone (sync) og asynkrone (async). For de fleste arbejdsbelastninger er langt de fleste skriveoperationer asynkrone – filsystemet får lov til at samle dem og overføre dem i batches, hvilket reducerer fragmentering og øger gennemstrømningen enormt.
Synkron skrivning er et helt andet dyr – når et program anmoder om en synkron skrivning, fortæller det filsystemet “du skal overføre dette til ikke-flygtigt lager nu, og indtil du gør det, kan jeg ikke gøre noget andet”. Sync writes skal derfor overføres til disken med det samme – og hvis det øger fragmenteringen eller mindsker gennemstrømningen, må det være sådan.
ZFS håndterer sync writes anderledes end normale filsystemer – i stedet for at skylle sync writes ud til normal lagring med det samme, overfører ZFS dem til et særligt lagerområde kaldet ZFS Intent Log, eller ZIL. Fidusen her er, at disse skrivninger også forbliver i hukommelsen og bliver samlet sammen med normale asynkrone skriveanmodninger, for senere at blive skyllet ud til lageret som helt normale TXG’er (Transaction Groups).
I normal drift skrives der til ZIL’en og læses aldrig fra den igen. Når skrivninger, der er gemt i ZIL’en, et par øjeblikke senere overføres til hovedlageret fra RAM i normale TXG’er i normale TXG’er, bliver de afbundet fra ZIL’en. Det eneste tidspunkt, hvor ZIL’en nogensinde læses fra, er ved poolimport.
Hvis ZFS går ned – eller operativsystemet går ned, eller der er en ubehandlet strømafbrydelse – mens der er data i ZIL’en, vil disse data blive læst fra under den næste poolimport (f.eks. når et nedbrudt system genstartes). Det, der er i ZIL’en, vil blive læst ind, aggregeret til TXG’er, overført til hovedlageret, og derefter afmeldt fra ZIL’en under importprocessen.
En af de klasser af support vdev, der er tilgængelige, er LOG– også kendt som SLOG, eller Secondary LOG-enhed. Alt, hvad SLOG gør, er at give puljen en separat – og forhåbentlig langt hurtigere og med meget høj skriveudholdenhed – vdev til at gemme ZIL i, i stedet for at beholde ZIL på hovedlageret vdevs. I alle henseender opfører ZIL sig på samme måde, uanset om den befinder sig på hovedlageret eller på en LOG vdev – men hvis LOG vdev’en har meget høj skriveydelse, vil synkroniseringsskrivningsreturneringer ske meget hurtigt.
At tilføje en LOG vdev til en pulje kan absolut ikke og vil ikke direkte forbedre asynkron skriveydelse – selv hvis du tvinger alle skrivninger ind i ZIL’en ved hjælp af zfs set sync=always, bliver de stadig overført til hovedlageret i TXG’er på samme måde og i samme tempo, som de ville have gjort uden LOG. De eneste direkte ydelsesforbedringer er for synkrone skriveforsinkelser (da LOGs større hastighed gør det muligt for sync-opkaldet at vende hurtigere tilbage).
Men i et miljø, der allerede kræver mange synkrone skrivninger, kan en LOG vdev indirekte også fremskynde asynkrone skrivninger og ucachelæste læsninger. Aflastning af ZIL-skrivere til en separat LOG vdev betyder mindre konkurrence om IOPS på primær lagring, hvilket øger ydeevnen for alle læsninger og skrivninger til en vis grad.
Snapshots
Copy-on-write-semantik er også det nødvendige grundlag for ZFS’ atomiske snapshots og inkrementel asynkron replikering. Live-filsystemet har et træ af pointere, der markerer alle de records, der indeholder aktuelle data – når du tager et snapshot, laver du simpelthen en kopi af dette træ af pointere.
Når en post bliver overskrevet i live-filsystemet, skriver ZFS den nye version af block først til ubrugt plads. Derefter ophæver den linket til den gamle version af block fra det aktuelle filsystem. Men hvis en snapshot refererer til den gamle block, forbliver den stadig uforanderlig. Den gamle block vil faktisk ikke blive genindvundet som ledig plads, før alle snapshots, der refererer til den block, er blevet ødelagt!
Replikation

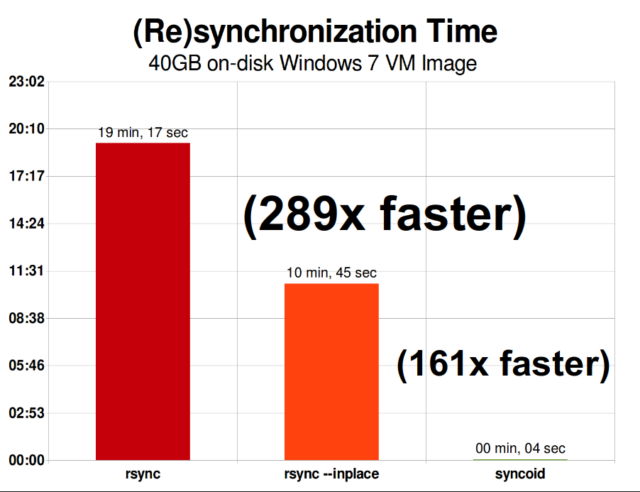
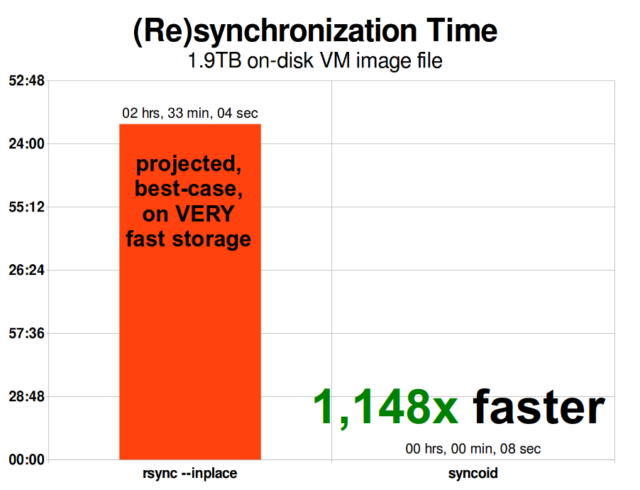 Når du forstår, hvordan snapshots fungerer, er du godt rustet til at forstå replikation. Da et snapshot simpelthen er et træ af pointere til
Når du forstår, hvordan snapshots fungerer, er du godt rustet til at forstå replikation. Da et snapshot simpelthen er et træ af pointere til records, følger det, at hvis vi zfs send et snapshot, sender vi både dette træ og alle de tilknyttede poster. Når vi pipe denne zfs send til en zfs receive på målet, skriver den både det faktiske block-indhold og træet af pointere, der henviser til blocks, ind i måldatasættet.
Det bliver mere interessant på din anden zfs send. Nu hvor du har to systemer, der hver indeholder snapshot poolname/datasetname@1, kan du tage et nyt snapshot, poolname/datasetname@2. Så på kildepuljen har du datasetname@1 og datasetname@2, og på målpuljen har du indtil videre kun det første snapshot – datasetname@1.
Da vi har et fælles snapshot mellem kilde og mål – datasetname@1 – kan vi bygge et inkrementelt zfs send oven på det. Når vi beder systemet om at zfs send -i poolname/datasetname@1 poolname/datasetname@2, sammenligner det de to pointertræer. Alle pointere, der kun findes i @2, refererer naturligvis til nye blocks – så vi har også brug for indholdet af disse blocks.
På fjernsystemet er det tilsvarende nemt at indsætte det resulterende inkrementelle send i rørledningen. Først skriver vi alle de nye records ud, der er inkluderet i send-strømmen, og derefter tilføjer vi pointerne til disse blocks. Presto, vi har @2 på det nye system!
ZFS asynkron inkrementel replikering er en enorm forbedring i forhold til tidligere, ikke-snapshot-baserede teknikker som rsync. I begge tilfælde er det kun de ændrede data, der skal sendes over kablet – men rsync skal først læse alle data fra disken, på begge sider, for at kunne lave en checksum og sammenligne dem. I modsætning hertil behøver ZFS-replikation ikke at læse andet end pointertræerne – og alle blocks det pointertræ indeholder, som ikke allerede var til stede i det fælles snapshot.
Inline-komprimering
Copy-on-write-semantik gør det også lettere at tilbyde inline-komprimering. Med et traditionelt filsystem, der tilbyder ændring på stedet, er komprimering problematisk – både den gamle version og den nye version af de ændrede data skal passe ind på nøjagtig samme plads.
Hvis vi tænker på et stykke data i midten af en fil, der begynder sit liv som 1MiB af nuller-0x00000000 ad nauseam – ville det meget let kunne komprimeres ned til en enkelt disksektor. Men hvad sker der, hvis vi erstatter denne 1MiB nuller med 1MiB ukomprimerbare data, f.eks. JPEG eller pseudo-tilfældig støj? Pludselig har denne 1MiB data brug for 256 4KiB sektorer, ikke kun én – og hullet i midten af filen er kun én sektor bredt.
ZFS har ikke dette problem, da ændrede poster altid skrives til ubrugt plads – den oprindelige block optager kun en enkelt 4KiB sector, og den nye post optager 256 af dem, men det er ikke et problem – den nyligt ændrede klump fra “midten” af filen ville være blevet skrevet til ubrugt plads, uanset om dens størrelse ændrede sig eller ej, så for ZFS er dette “problem” bare en anden dag på kontoret.
ZFS’ inline-komprimering er som standard slået fra, og den tilbyder algoritmer, der kan tilsluttes – på nuværende tidspunkt omfatter den LZ4, gzip (1-9), LZJB og ZLE.
- LZ4 er en stream-algoritme, der tilbyder ekstremt hurtig komprimering og dekomprimering og er en præstationsgevinst i de fleste tilfælde af brug – selv med meget anæmiske CPU’er.
- GZIP er den ærværdige algoritme, som alle Unix-lignende brugere kender og elsker. Den kan implementeres med kompressionsniveauer 1-9, med stigende kompressionsforhold og CPU-forbrug, efterhånden som niveauerne nærmer sig 9. Gzip kan være en gevinst i tilfælde, hvor der kun anvendes tekst (eller på anden måde ekstremt komprimerbar), men resulterer ofte i CPU-flaskehalse på andre måder – brug med forsigtighed, især på højere niveauer.
- LZJB er den oprindelige algoritme, der anvendes af ZFS. Den er forældet og bør ikke længere bruges – LZ4 er overlegen på alle parametre.
- ZLE er Zero Level Encoding – den lader normale data være helt i fred, men komprimerer store sekvenser af nuller. Nyttigt til helt inkomprimerbare datasæt (f.eks. JPEG, MP4 eller andre allerede komprimerede formater), da det ignorerer de inkomprimerbare data, men komprimerer slap plads på de endelige poster.
Vi anbefaler LZ4-komprimering til næsten alle tænkelige brugssituationer; ydelsesbortfaldet, når det støder på inkomprimerbare data, er meget lille, og ydelsesgevinsten for typiske data er betydelig. Kopiering af et VM-aftryk til en ny Windows-operativsysteminstallation (kun det installerede Windows-operativsystem, ingen data på det endnu) gik 27 % hurtigere med compression=lz4 end compression=none i denne test fra 2015.
ARC-the Adaptive Replacement Cache
ZFS er det eneste moderne filsystem, vi kender, som bruger sin egen læsecachemekanisme, i stedet for at stole på operativsystemets sidecache til at opbevare kopier af nyligt læste blokke i RAM for det.
Men selv om den separate cachemekanisme har sine problemer – ZFS kan ikke reagere på nye anmodninger om at allokere hukommelse så øjeblikkeligt som kernen kan, og derfor kan et nyt mallocate()kald mislykkes, hvis det ville have brug for RAM, der i øjeblikket er optaget af ARC’en – er der, i det mindste indtil videre, god grund til at finde sig i det.
Alle kendte moderne styresystemer – herunder MacOS, Windows, Linux og BSD – anvender LRU-algoritmen (Least Recently Used) til implementeringen af sidecachen. LRU er en naiv algoritme, der fører en blok i cachen op til “toppen” af køen, hver gang den læses, og som fjerner blokke fra “bunden” af køen efter behov for at tilføje nye cache-misses (blokke, der skulle læses fra disken i stedet for fra cachen) i “toppen”.”
Dette er fint så langt som det går, men i systemer med store arbejdsdatasæt kan LRU let ende med at “thrashe” – at fjerne meget ofte nødvendige blokke for at gøre plads til blokke, der aldrig vil blive læst fra cache igen.
ARC er en langt mindre naiv algoritme, som kan betragtes som en “vægtet” cache. Hver gang en blok i cachen læses, bliver den en smule “tungere” og sværere at evict – og selv efter en eviction spores den evictede blok i et vist tidsrum. En blok, der er blevet udvist, men som derefter skal læses tilbage i cachen, bliver også “tungere” og vanskeligere at udvise.
Det endelige resultat af alt dette er en cache med typisk langt større hit-ratio – forholdet mellem cache-hits (læsninger serveret fra cachen) og cache-misses (læsninger serveret fra disken). Dette er en ekstremt vigtig statistik – ikke alene serveres cache-hits i sig selv hurtigere, men også cache-misses kan også serveres hurtigere, da flere cache-hits = færre samtidige anmodninger til disken = lavere latenstid for de resterende misses, der skal betjenes fra disken.
Slutning
Nu da vi har gennemgået den grundlæggende semantik i ZFS – hvordan copy-on-write fungerer og forholdet mellem pools, vdevs, blokke, sektorer og filer – er vi klar til at tale om den faktiske ydeevne, med rigtige tal.
Bliv hængende til næste afsnit af vores serie om grundlæggende lagerprincipper for at se den faktiske ydelse, der ses i puljer, der bruger mirror- og RAIDz-vdevs, sammenlignet med både hinanden og de traditionelle Linux-kernel-RAID-topologier, som vi udforskede tidligere.
I første omgang vil vi blot dække det grundlæggende – selve ZFS-topologierne – men derefter vil vi være klar til at tale om mere avanceret opsætning og tuning af ZFS, herunder brugen af support vdev-typer som L2ARC, SLOG og Special Allocation.