
Serhii Maksymenko,
Data Science Solution Architect
Gesichtserkennungstechnologie erscheint heute in einem anderen Licht. Die Anwendungsfälle sind breit gefächert und reichen von der Verbrechenserkennung bis zur Identifizierung genetischer Krankheiten.
Während Regierungen auf der ganzen Welt in Gesichtserkennungssysteme investieren, haben einige US-Städte wie Oakland, Somerville und Portland sie aufgrund von Bedenken hinsichtlich der Bürgerrechte und des Datenschutzes verboten.
Was ist es – eine Zeitbombe oder ein technologischer Durchbruch? In diesem Artikel wird erläutert, was die Gesichtserkennung aus technologischer Sicht ist und wie Deep Learning ihre Möglichkeiten erweitert. Nur wenn man weiß, wie die Gesichtserkennungstechnologie von innen heraus funktioniert, kann man verstehen, wozu sie fähig ist.
Aktualisiert am 06.09.2020: Maskierte Gesichtsdetektion und -erkennung
Wie Deep Learning Gesichtserkennungssoftware modernisieren kann
Download PDF
Wie funktioniert die Gesichtserkennung?
Der Computeralgorithmus der Gesichtserkennungssoftware ähnelt der menschlichen visuellen Erkennung. Aber wenn Menschen visuelle Daten im Gehirn speichern und bei Bedarf automatisch abrufen, sollten Computer Daten aus einer Datenbank abrufen und abgleichen, um ein menschliches Gesicht zu identifizieren.
Kurz gesagt, ein Computersystem, das mit einer Kamera ausgestattet ist, erkennt und identifiziert ein menschliches Gesicht, extrahiert Gesichtsmerkmale wie den Abstand zwischen den Augen, die Länge der Nase, die Form der Stirn und der Wangenknochen. Dann erkennt das System das Gesicht und gleicht es mit Bildern ab, die in einer Datenbank gespeichert sind.
Die herkömmliche Gesichtserkennungstechnologie ist jedoch noch nicht ganz perfekt. Sie hat sowohl Stärken als auch Schwächen:
| Stärken
Berührungslose biometrische Identifizierung Bis zu einer Sekunde Datenverarbeitung Kompatibilität mit den meisten Kameras Einfache Integration |
Schwächen
Zwillinge und Rassenvorurteile Datenschutzprobleme Präsentationsangriffe (PA) geringe Genauigkeit bei schlechten Lichtverhältnissen |
Die Schwächen von Gesichtserkennungssystemen, gingen Datenwissenschaftler noch weiter. Durch die Anwendung traditioneller Computer-Vision-Techniken und Deep-Learning-Algorithmen haben sie das Gesichtserkennungssystem feinabgestimmt, um Angriffe zu verhindern und die Genauigkeit zu erhöhen. So funktioniert eine Technologie zum Schutz vor Spoofing.
Wie Deep Learning die Gesichtserkennungssoftware verbessert
Deep Learning ist eine der neuartigsten Methoden zur Verbesserung der Gesichtserkennungstechnologie. Die Idee besteht darin, Gesichtseinbettungen aus Bildern mit Gesichtern zu extrahieren. Solche Gesichtseinbettungen sind für verschiedene Gesichter einzigartig. Und das Training eines tiefen neuronalen Netzes ist der optimale Weg, um diese Aufgabe zu erfüllen.
Abhängig von der Aufgabe und dem Zeitrahmen gibt es zwei gängige Methoden, um Deep Learning für Gesichtserkennungssysteme zu nutzen:
Verwendung von vortrainierten Modellen wie dlib, DeepFace, FaceNet und anderen. Diese Methode ist weniger zeit- und arbeitsaufwändig, da die vortrainierten Modelle bereits eine Reihe von Algorithmen für die Gesichtserkennung enthalten. Außerdem können wir die vortrainierten Modelle feinabstimmen, um Verzerrungen zu vermeiden und das Gesichtserkennungssystem richtig arbeiten zu lassen.
Entwickeln Sie ein neuronales Netzwerk von Grund auf. Diese Methode ist für komplexe Gesichtserkennungssysteme mit Mehrzweckfunktionen geeignet. Sie ist zeitaufwändiger und erfordert Millionen von Bildern im Trainingsdatensatz, im Gegensatz zu einem vortrainierten Modell, das im Falle des Transferlernens nur Tausende von Bildern benötigt.

Wenn das Gesichtserkennungssystem jedoch einzigartige Merkmale enthält, kann dies auf lange Sicht ein optimaler Weg sein. Die wichtigsten Punkte, auf die man achten sollte, sind:
- Die richtige Auswahl der CNN-Architektur und der Verlustfunktion
- Optimierung der Inferenzzeit
- Die Leistung der Hardware
Es wird empfohlen, bei der Entwicklung einer Netzwerkarchitektur Faltungsneuronale Netze (CNN) zu verwenden, da sie sich bei Bilderkennungs- und Klassifizierungsaufgaben als effektiv erwiesen haben. Um die erwarteten Ergebnisse zu erzielen, ist es besser, eine allgemein anerkannte neuronale Netzwerkarchitektur als Grundlage zu verwenden, z. B. ResNet oder EfficientNet.
Beim Training eines neuronalen Netzes für die Entwicklung von Gesichtserkennungssoftware sollten wir in den meisten Fällen die Fehler minimieren. Hier ist es entscheidend, die Verlustfunktionen zu berücksichtigen, die für die Berechnung des Fehlers zwischen der tatsächlichen und der vorhergesagten Ausgabe verwendet werden. Die in Gesichtserkennungssystemen am häufigsten verwendeten Funktionen sind Triplett-Verlust und AM-Softmax.
- Die Triplett-Verlustfunktion setzt voraus, dass drei Bilder von zwei verschiedenen Personen vorliegen. Es gibt zwei Bilder – Anker und positiv – für eine Person, und das dritte – negativ – für eine andere Person. Die Netzwerkparameter werden so erlernt, dass sie dieselben Personen im Merkmalsraum einander annähern und verschiedene Personen voneinander trennen.
- Die AM-Softmax-Funktion ist eine der jüngsten Modifikationen der Standard-Softmax-Funktion, die eine besondere Regularisierung auf der Grundlage einer additiven Marge verwendet. Sie ermöglicht eine bessere Trennbarkeit der Klassen und verbessert somit die Genauigkeit des Gesichtserkennungssystems.
Es gibt auch verschiedene Ansätze zur Verbesserung eines neuronalen Netzes. Bei Gesichtserkennungssystemen sind die interessantesten die Wissensdestillation, das Transferlernen, die Quantisierung und die tiefenseparierbaren Faltungen.
- Bei der Wissensdestillation werden zwei unterschiedlich große Netze eingesetzt, wobei ein großes Netz seine eigene kleinere Variante lernt. Der Schlüsselwert besteht darin, dass das kleinere Netz nach dem Training schneller arbeitet als das große und das gleiche Ergebnis liefert.
- Der Ansatz des Transfer-Lernens ermöglicht die Verbesserung der Genauigkeit durch Training des gesamten Netzes oder nur bestimmter Schichten auf einem bestimmten Datensatz. Wenn das Gesichtserkennungssystem beispielsweise Probleme mit der Rassenunterscheidung hat, können wir einen bestimmten Satz von Bildern nehmen, z. B. Bilder von Chinesen, und das Netzwerk so trainieren, dass es eine höhere Genauigkeit erreicht.
- Quantisierungsansatz verbessert ein neuronales Netzwerk, um eine höhere Verarbeitungsgeschwindigkeit zu erreichen. Durch die Annäherung eines neuronalen Netzes, das Fließkommazahlen verwendet, an ein neuronales Netz mit Zahlen niedriger Bitbreite können wir die Speichergröße und die Anzahl der Berechnungen verringern.
- Tiefenweise trennbare Faltungen sind eine Klasse von Schichten, die den Aufbau von CNN mit einem viel kleineren Satz von Parametern im Vergleich zu Standard-CNNs ermöglichen. Bei einer geringen Anzahl von Berechnungen kann dieses Merkmal das Gesichtserkennungssystem so verbessern, dass es für mobile Bildverarbeitungsanwendungen geeignet ist.
Das Schlüsselelement der Deep-Learning-Technologien ist der Bedarf an leistungsfähiger Hardware. Bei der Verwendung von tiefen neuronalen Netzen für die Entwicklung von Gesichtserkennungssoftware besteht das Ziel nicht nur darin, die Erkennungsgenauigkeit zu verbessern, sondern auch die Reaktionszeit zu verkürzen. Aus diesem Grund ist beispielsweise ein Grafikprozessor für Deep-Learning-basierte Gesichtserkennungssysteme besser geeignet als eine CPU.
Wie wir eine Deep-Learning-basierte Gesichtserkennungs-App implementiert haben
Bei der Entwicklung von Big Brother (einer Demo-Kamera-App) bei MobiDev hatten wir das Ziel, eine biometrische Verifikationssoftware mit Echtzeit-Videostreaming zu entwickeln. Als lokale Konsolen-App für Ubuntu und Raspbian ist Big Brother in Golang geschrieben und wird über die JSON-Konfigurationsdatei mit der lokalen Kamera-ID und dem Typ des Kamerareaders konfiguriert. Dieses Video beschreibt, wie Big Brother in der Praxis funktioniert:
Der Arbeitszyklus der Big Brother-App umfasst:
1. Gesichtserkennung
Die App erkennt Gesichter in einem Videostream. Sobald das Gesicht erfasst ist, wird das Bild beschnitten und über eine HTTP-Formularanforderung an das Backend gesendet. Die Backend-API speichert das Bild in einem lokalen Dateisystem und speichert einen Datensatz mit einer Personenkennung im Erkennungsprotokoll.
Das Backend nutzt Golang und MongoDB-Sammlungen zum Speichern von Mitarbeiterdaten. Alle API-Anfragen basieren auf RESTful API.

2. Sofortige Gesichtserkennung
Das Backend verfügt über einen Hintergrundworker, der neue unklassifizierte Datensätze findet und Dlib verwendet, um den 128-dimensionalen Deskriptorvektor der Gesichtsmerkmale zu berechnen. Jedes Mal, wenn ein Vektor berechnet wird, wird er mit mehreren Referenzgesichtsbildern verglichen, indem der euklidische Abstand zu jedem Merkmalsvektor jeder Person in der Datenbank berechnet wird, um eine Übereinstimmung zu finden.
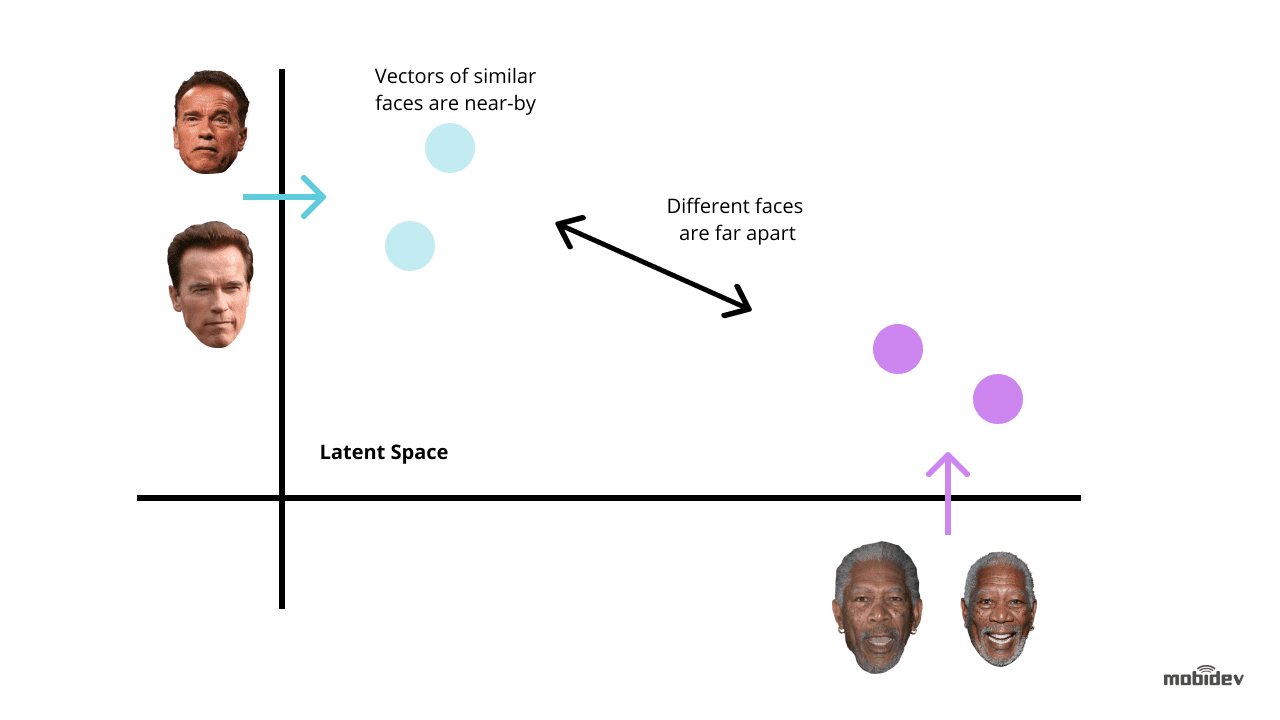
Wenn der euklidische Abstand zu der erkannten Person weniger als 0,6 beträgt, setzt der Worker eine PersonID in das Erkennungsprotokoll und markiert sie als klassifiziert. Wenn der Abstand größer als 0,6 ist, wird eine neue Personen-ID im Protokoll erstellt.
3. Folgeaktionen: Benachrichtigung, Zugang gewähren und andere
Bilder einer nicht identifizierten Person werden mit Benachrichtigungen über Chatbots in Messengern an den entsprechenden Manager gesendet. In der Big-Brother-App haben wir das Microsoft Bot Framework und den Python-basierten Errbot verwendet, wodurch wir den Alarm-Chatbot innerhalb von fünf Tagen implementieren konnten.

Diese Datensätze können anschließend über das Admin-Panel verwaltet werden, das Fotos mit IDs in der Datenbank speichert. Die Gesichtserkennungssoftware arbeitet in Echtzeit und führt Gesichtserkennungsaufgaben sofort aus. Durch die Verwendung von Golang und MongoDB Collections für die Speicherung von Mitarbeiterdaten haben wir die IDs-Datenbank mit 200 Einträgen eingegeben.
So ist die Gesichtserkennungs-App von Big Brother aufgebaut:
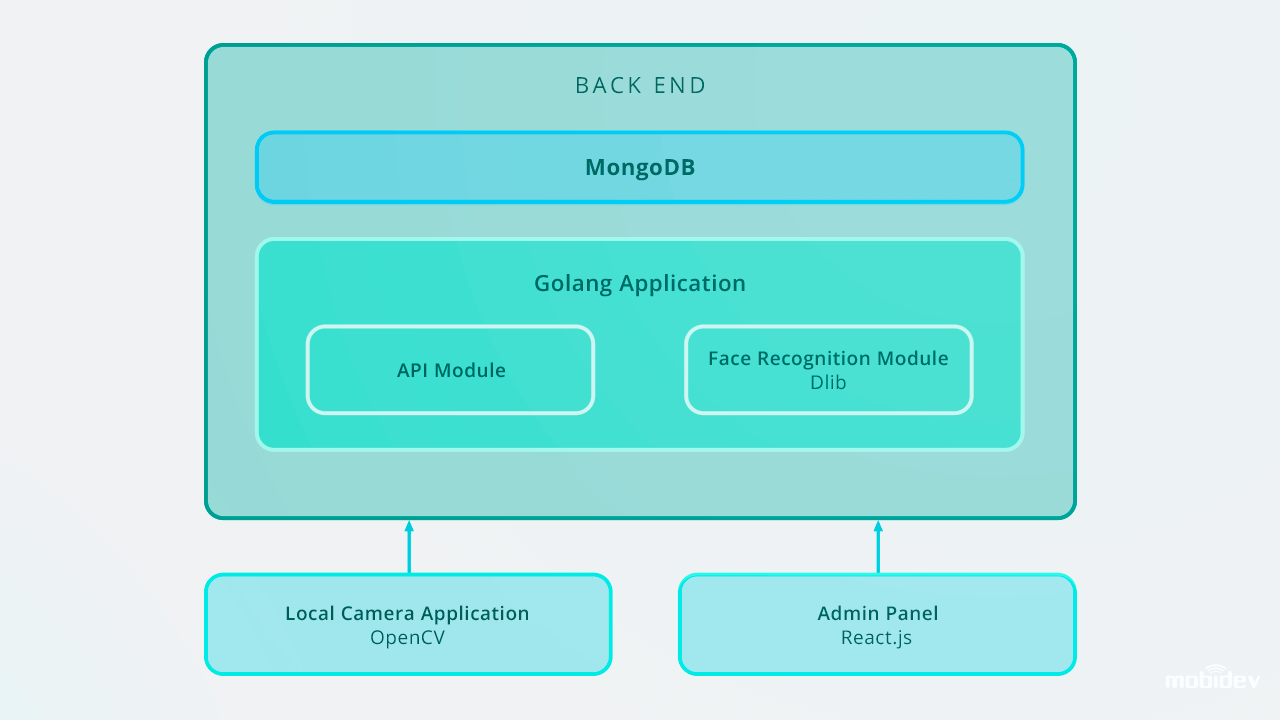
Bei einer Skalierung auf 10.000 Einträge würden wir empfehlen, das Gesichtserkennungssystem zu verbessern, um eine hohe Erkennungsgeschwindigkeit im Backend zu gewährleisten. Eine der besten Möglichkeiten ist die Parallelisierung. Durch die Einrichtung eines Load Balancers und den Aufbau mehrerer Web Worker können wir die ordnungsgemäße Arbeit eines Back-End-Teils und die optimale Geschwindigkeit des gesamten Systems sicherstellen.
Weitere Anwendungsfälle für Deep Learning-basierte Erkennung
Gesichtserkennung ist nicht die einzige Aufgabe, bei der Deep Learning-basierte Softwareentwicklung die Leistung verbessern kann. Weitere Beispiele sind:
Maskierte Gesichtserkennung
Seitdem COVID-19 die Menschen in vielen Ländern dazu gebracht hat, Gesichtsmasken zu tragen, hat sich die Gesichtserkennungstechnologie weiterentwickelt. Durch den Einsatz von Deep-Learning-Algorithmen auf der Grundlage von neuronalen Faltungsnetzen können Kameras jetzt auch Gesichter erkennen, die mit Masken bedeckt sind. Data-Science-Ingenieure nutzen Algorithmen wie Multi-Granularitäts- und periokulare Erkennungsmodelle, um die Fähigkeiten des Gesichtserkennungssystems zu verbessern. Durch die Identifizierung von Gesichtsmerkmalen wie Stirn, Gesichtskontur, Augen- und periokulare Details, Augenbrauen, Augen und Wangenknochen ermöglichen diese Modelle die Erkennung von maskierten Gesichtern mit einer Genauigkeit von bis zu 95 %.
Ein gutes Beispiel für ein solches System ist die von einem chinesischen Unternehmen entwickelte Gesichtserkennungstechnologie. Das System besteht aus zwei Algorithmen: einer auf tiefem Lernen basierenden Gesichtserkennung und einer Infrarot-Wärmebild-Temperaturmessung. Wenn sich Personen mit Gesichtsmasken vor die Kamera stellen, extrahiert das System Gesichtsmerkmale und vergleicht sie mit vorhandenen Bildern in der Datenbank. Gleichzeitig misst der Infrarot-Temperaturmessmechanismus die Temperatur und erkennt so Personen mit abnormalen Temperaturen.
Mängelerkennung
In den letzten Jahren haben Hersteller KI-basierte visuelle Inspektionen zur Mängelerkennung eingesetzt. Die Entwicklung von Deep-Learning-Algorithmen ermöglicht es diesem System, selbst kleinste Kratzer und Risse automatisch zu erkennen, ohne dass der Mensch eingreifen muss.
Erkennung von Körperanomalien
Das israelische Unternehmen Aidoc hat eine auf Deep Learning basierende Lösung für die Radiologie entwickelt. Durch die Analyse medizinischer Bilder erkennt dieses System Anomalien in Brustkorb, Halswirbelsäule, Kopf und Bauch.
Sprecheridentifizierung
Die von der Firma Phonexia entwickelte Technologie zur Sprecheridentifizierung identifiziert Sprecher ebenfalls mit Hilfe des metrischen Lernansatzes. Das System erkennt Sprecher anhand ihrer Stimme und erstellt mathematische Modelle der menschlichen Sprache, die sogenannten Voiceprints. Diese Stimmprofile werden in Datenbanken gespeichert, und wenn eine Person spricht, identifiziert die Sprechertechnologie das eindeutige Stimmprofil.
Erkennung von Emotionen
Die Erkennung von menschlichen Emotionen ist heute eine machbare Aufgabe. Die Emotionserkennungstechnologie kategorisiert menschliche Emotionen, indem sie die Bewegungen eines Gesichts per Kamera verfolgt. Der Deep-Learning-Algorithmus identifiziert Orientierungspunkte eines menschlichen Gesichts, erkennt einen neutralen Gesichtsausdruck und misst Abweichungen von Gesichtsausdrücken, um positivere oder negativere Ausdrücke zu erkennen.
Aktionserkennung
Das Unternehmen Visual One, ein Anbieter von Nest Cams, hat sein Produkt mit KI ausgestattet. Durch den Einsatz von Deep-Learning-Techniken haben sie die Nest Cams so optimiert, dass sie nicht nur verschiedene Objekte wie Menschen, Haustiere, Autos usw. erkennen, sondern auch Aktionen identifizieren können. Die zu erkennenden Aktionen sind anpassbar und können vom Benutzer ausgewählt werden. So kann eine Kamera beispielsweise eine Katze erkennen, die an der Tür kratzt, oder ein Kind, das mit dem Herd spielt.
Zusammenfassend kann man sagen, dass tiefe neuronale Netze ein mächtiges Werkzeug für die Menschheit sind. Und nur der Mensch entscheidet, wie die technologische Zukunft aussieht.
Wie Deep Learning die Gesichtserkennungssoftware modernisieren kann
Download PDF