
Während wir alle in den dritten Monat der COVID-19-Pandemie eintreten und nach neuen Projekten suchen, um uns zu beschäftigen (sprich: gesund zu bleiben), können wir Sie dafür interessieren, die Grundlagen der Computerspeicherung zu lernen? In diesem Frühjahr haben wir bereits in aller Stille einige notwendige Grundlagen behandelt, z. B. wie Sie die Geschwindigkeit Ihrer Festplatten testen können und was zum Teufel RAID ist. In der zweiten dieser Geschichten haben wir sogar eine Fortsetzung versprochen, in der wir die Leistung verschiedener Topologien mit mehreren Festplatten in ZFS untersuchen, dem Dateisystem der nächsten Generation, von dem Sie schon gehört haben, weil es überall von Apple bis Ubuntu auftaucht.
Heute ist der Tag, an dem Sie ZFS erkunden können, neugierige Leser. Um es gleich vorweg zu nehmen, in den untertriebenen Worten des OpenZFS-Entwicklers Matt Ahrens: „Es ist wirklich kompliziert.“
Aber bevor wir zu den Zahlen kommen – und die kommen, versprochen!-für alle Möglichkeiten, wie Sie ZFS auf acht Festplatten gestalten können, müssen wir darüber sprechen, wie ZFS Ihre Daten überhaupt auf der Festplatte speichert.
Zpools, vdevs und Geräte
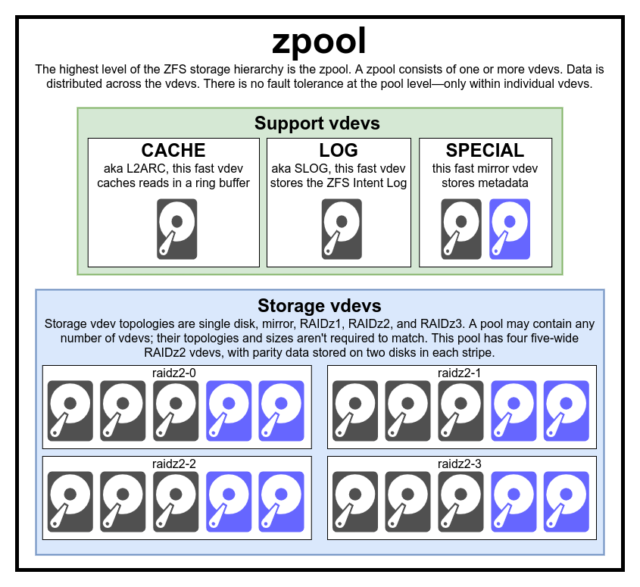

Um ZFS wirklich zu verstehen, müssen Sie sich mit seiner tatsächlichen Struktur befassen. ZFS verschmilzt die traditionellen Ebenen der Datenträgerverwaltung und des Dateisystems und verwendet einen Copy-on-Write-Transaktionsmechanismus – beides bedeutet, dass sich das System strukturell stark von herkömmlichen Dateisystemen und RAID-Arrays unterscheidet. Die erste Gruppe von Hauptbausteinen, die man verstehen muss, sind zpools, vdevs und devices.
zpool
Das zpool ist die oberste ZFS-Struktur. Ein zpool enthält einen oder mehrere vdevs, von denen jeder wiederum einen oder mehrere devices enthält. Zpools sind in sich geschlossene Einheiten – auf einem physischen Computer können zwei oder mehr separate Zpools vorhanden sein, aber jeder ist völlig unabhängig von den anderen. Zpools können vdevs nicht miteinander teilen.
ZFS-Redundanz findet auf der vdev-Ebene statt, nicht auf der zpool-Ebene. Es gibt absolut keine Redundanz auf Zpool-Ebene – wenn ein vdev– oder SPECIAL-Speicherdev verloren geht, geht das gesamte zpool mit ihm verloren.
Moderne zpools können den Verlust eines CACHE oder LOG vdev überleben – obwohl sie möglicherweise eine kleine Menge an schmutzigen Daten verlieren, wenn sie ein LOG vdev während eines Stromausfalls oder Systemabsturzes verlieren.
Es ist ein weit verbreiteter Irrglaube, dass ZFS Schreibvorgänge über den Pool „streift“ – aber das ist nicht korrekt. Ein ZFS-Pool ist kein komisch aussehendes RAID0, sondern ein komisch aussehendes JBOD mit einem komplexen Verteilungsmechanismus, der sich ändern kann.
Die meisten Schreibvorgänge werden auf die verfügbaren Vdevs entsprechend ihrem verfügbaren freien Speicherplatz verteilt, so dass theoretisch alle Vdevs zur gleichen Zeit voll werden. In neueren Versionen von ZFS kann auch die Auslastung der Vdevs berücksichtigt werden – wenn ein Vdev deutlich stärker ausgelastet ist als ein anderes (z.B. aufgrund von Leselast), kann es vorübergehend für Schreibvorgänge übersprungen werden, obwohl es den höchsten Anteil an verfügbarem freien Speicherplatz hat.
Der in moderne ZFS-Schreibverteilungsmethoden eingebaute Auslastungswahrnehmungsmechanismus kann die Latenz verringern und den Durchsatz in Zeiten ungewöhnlich hoher Last erhöhen – er sollte jedoch nicht als Freibrief dafür verstanden werden, langsame Rust-Disks und schnelle SSDs willkürlich im selben Pool zu mischen. Ein solcher unangepasster Pool wird im Allgemeinen immer noch so funktionieren, als bestünde er ausschließlich aus dem langsamsten vorhandenen Gerät.
vdev
Jedes zpool besteht aus einem oder mehreren vdevs(kurz für virtual device). Jedes vdev besteht seinerseits aus einem oder mehreren realen devices. Die meisten vdevs werden für einfachen Speicher verwendet, aber es gibt auch einige spezielle Support-Klassen von vdevs, darunter CACHE, LOG und SPECIAL. Jeder dieser vdev-Typen kann eine von fünf Topologien anbieten – Single-Device, RAIDz1, RAIDz2, RAIDz3 oder Mirror.
RAIDz1, RAIDz2 und RAIDz3 sind spezielle Varianten von dem, was Speicherkenner „diagonales Paritäts-RAID“ nennen. Die 1, 2 und 3 beziehen sich darauf, wie viele Paritätsblöcke jedem Datenstreifen zugewiesen werden. Anstatt ganze Festplatten für die Parität zu verwenden, verteilen RAIDz vdevs die Parität halbwegs gleichmäßig auf die Festplatten. Ein RAIDz-Array kann so viele Festplatten verlieren, wie es Paritätsblöcke hat; wenn es eine weitere verliert, fällt es aus und nimmt die zpool mit sich.
Spiegel-Vdevs sind genau das, wonach sie klingen – in einem Spiegel-Vdev ist jeder Block auf jedem Gerät im Vdev gespeichert. Obwohl zwei breite Spiegelungen am gebräuchlichsten sind, kann ein Mirror-Vdev eine beliebige Anzahl von Geräten enthalten – Drei-Wege-Geräte sind in größeren Setups wegen der höheren Leseleistung und Fehlerresistenz üblich. Ein Mirror vdev kann jeden Ausfall überstehen, solange mindestens ein Gerät im vdev intakt bleibt.
Einzelgeräte vdevs sind auch genau das, wonach sie klingen – und sie sind von Natur aus gefährlich. Ein Single-Device-Vdev kann keinen Ausfall überleben – und wenn es als Speicher- oder SPECIAL Vdev verwendet wird, wird sein Ausfall das gesamte zpool mit sich reißen. Seien Sie hier sehr, sehr vorsichtig.
CACHE, LOG und SPECIAL vdevs können mit jeder der oben genannten Topologien erstellt werden – aber denken Sie daran, dass der Verlust eines SPECIAL vdevs den Verlust des Pools bedeutet, daher wird eine redundante Topologie dringend empfohlen.
device
Dies ist wahrscheinlich der am einfachsten zu verstehende Begriff im Zusammenhang mit ZFS – es ist buchstäblich nur ein Random-Access-Block-Device. Erinnere dich, vdevs besteht aus einzelnen Geräten, und zpool besteht aus vdevs.
Platten – entweder Rost oder Solid-State – sind die häufigsten Blockgeräte, die als vdev-Bausteine verwendet werden. Alles mit einem Deskriptor in /dev, der einen zufälligen Zugriff erlaubt, funktioniert jedoch auch – so können (und werden manchmal) ganze Hardware-RAID-Arrays als einzelne Geräte verwendet werden.
Die einfache Rohdatei ist eines der wichtigsten alternativen Blockgeräte, aus denen eine vdev aufgebaut werden kann. Testpools aus Sparse-Dateien sind eine unglaublich bequeme Möglichkeit, zpool-Befehle zu üben und zu sehen, wie viel Platz auf einem Pool oder vdev einer bestimmten Topologie verfügbar ist.

Angenommen, Sie möchten einen Server mit acht Einschüben bauen und sind sich ziemlich sicher, dass Sie 10 TB (~9300 GiB) Festplatten verwenden möchten, sind sich aber nicht sicher, welche Topologie Ihren Anforderungen am besten entspricht. Im obigen Beispiel haben wir in Sekundenschnelle einen Testpool aus Sparse-Dateien erstellt – und jetzt wissen wir, dass ein RAIDz2 vdev aus acht 10 TB-Platten 50 TB nutzbare Kapazität bietet.
Es gibt eine besondere Klasse von device-die SPARE. Hotspare-Geräte gehören, anders als normale Geräte, zum gesamten Pool, nicht zu einem einzelnen vdev. Wenn ein vdev im Pool einen Geräteausfall erleidet und ein SPARE an den Pool angeschlossen und verfügbar ist, verbindet sich das SPARE automatisch mit dem ausgefallenen vdev.
Sobald es mit dem ausgefallenen vdev verbunden ist, beginnt das SPARE, Kopien oder Rekonstruktionen der Daten zu empfangen, die sich auf dem fehlenden Gerät befinden sollten. In einem traditionellen RAID würde man dies als „Wiederaufbau“ bezeichnen – in ZFS nennt man es „Resilvering“.
Es ist wichtig zu wissen, dass SPARE-Geräte ausgefallene Geräte nicht dauerhaft ersetzen. Sie sind nur Platzhalter, um das Zeitfenster zu minimieren, in dem ein vdev ausgefallen ist. Sobald der Administrator das ausgefallene Gerät des vdevs ersetzt hat und das neue, permanente Ersatzgerät wieder läuft, löst sich das SPARE vom vdev und kehrt zum poolweiten Dienst zurück.
Datensätze, Blöcke und Sektoren
Die nächsten Bausteine, die du auf deiner ZFS-Reise verstehen musst, beziehen sich nicht so sehr auf die Hardware, sondern darauf, wie die Daten selbst organisiert und gespeichert sind. Wir überspringen hier ein paar Ebenen – wie z.B. das Metasystem – um die Dinge so einfach wie möglich zu halten und trotzdem die Gesamtstruktur zu verstehen.
Datensätze
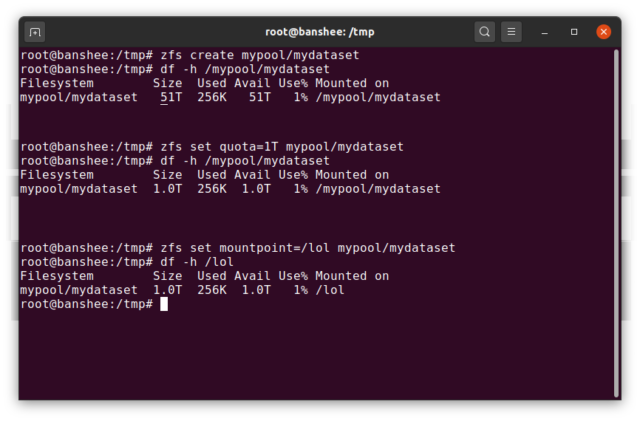

Ein ZFS dataset ist in etwa analog zu einem standardmäßigen, eingehängten Dateisystem – wie ein herkömmliches Dateisystem erscheint es bei oberflächlicher Betrachtung, als ob es „nur ein weiterer Ordner“ wäre. Aber auch wie konventionelle gemountete Dateisysteme hat jedes ZFS dataset seinen eigenen Satz an zugrundeliegenden Eigenschaften.
Zuallererst kann einem dataset eine Quote zugewiesen sein. Wenn Sie zfs set quota=100G poolname/datasetname, werden Sie nicht in der Lage sein, mehr als 100GiB an Daten in den vom System gemounteten Ordner /poolname/datasetname zu legen.
Beachten Sie das Vorhandensein – und das Fehlen – von führenden Schrägstrichen in dem obigen Beispiel? Jeder Datensatz hat seinen Platz sowohl in der ZFS-Hierarchie als auch in der Hierarchie der Systemeinhängung. In der ZFS-Hierarchie gibt es keinen führenden Schrägstrich – Sie beginnen mit dem Namen des Pools und dann mit dem Pfad von einem Datensatz zum nächsten – z. B. pool/parent/child für einen Datensatz namens child unter dem übergeordneten Datensatz parent in einem Pool mit dem kreativen Namen pool.
Standardmäßig entspricht der Einhängepunkt eines dataset seinem hierarchischen ZFS-Namen mit einem führenden Schrägstrich – der Pool mit dem Namen pool wird unter /pool eingehängt, der Datensatz parent wird unter /pool/parent eingehängt und der untergeordnete Datensatz child wird unter /pool/parent/child eingehängt. Der System-Einhängepunkt eines Datensatzes kann jedoch geändert werden.
Wenn wir zfs set mountpoint=/lol pool/parent/child einhängen würden, würde der Datensatz pool/parent/child tatsächlich als /lol im System eingehängt werden.
Zusätzlich zu den Datensätzen sollten wir zvols erwähnen. Ein zvol entspricht in etwa einem dataset, nur dass es kein Dateisystem enthält, sondern nur ein Blockgerät ist. Sie könnten zum Beispiel ein zvol mit dem Namen mypool/myzvol erstellen, es mit dem ext4-Dateisystem formatieren und dann dieses Dateisystem mounten – jetzt haben Sie ein ext4-Dateisystem, aber mit all den Sicherheitsfunktionen von ZFS! Das mag auf einem einzelnen Computer albern klingen, macht aber als Backend für einen iSCSI-Export viel mehr Sinn.
Blöcke
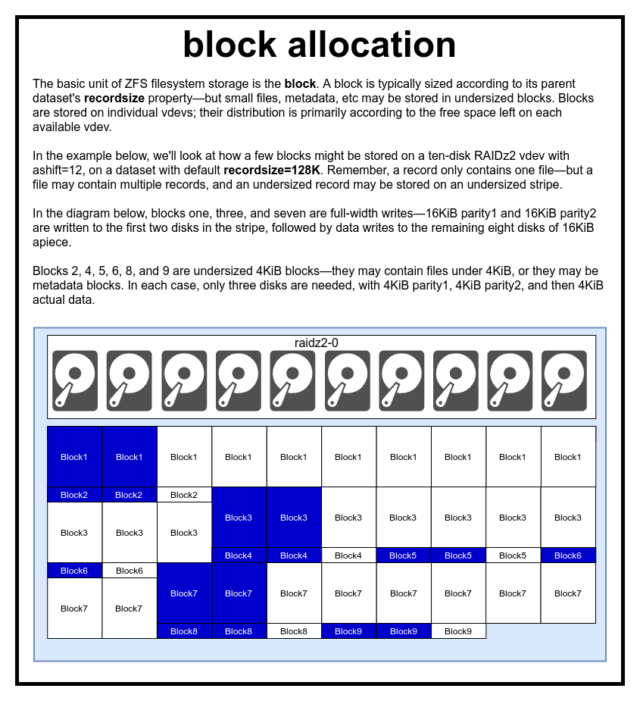

In einem ZFS-Pool werden alle Daten – einschließlich der Metadaten – in blocks gespeichert. Die maximale Größe eines block wird für jedes dataset in der Eigenschaft recordsize definiert. Recordsize ist veränderbar, aber das Ändern von recordsize ändert nicht die Größe oder das Layout von blocks, die bereits in den Datensatz geschrieben wurden – nur für neue Blöcke, wenn sie geschrieben werden.
Wenn nicht anders definiert, ist der aktuelle Standard recordsize 128KiB. Dies stellt eine Art unbehaglichen Kompromiss dar, bei dem die Leistung für viele Dinge nicht ideal ist, aber auch für viele Dinge nicht schrecklich ist. Recordsize kann auf jeden Wert zwischen 4K und 1M gesetzt werden. (Recordsize kann mit zusätzlicher Abstimmung und ausreichender Entschlossenheit sogar noch größer eingestellt werden, aber das ist selten eine gute Idee.)
Ein bestimmtes block verweist auf Daten aus nur einer Datei – man kann nicht zwei separate Dateien in dasselbe block packen. Jede Datei besteht aus einer oder mehreren blocks, je nach Größe. Wenn eine Datei kleiner als recordsize ist, wird sie in einem unterdimensionierten Block gespeichert – zum Beispiel belegt ein block mit einer 2KiB großen Datei nur einen einzigen 4KiB sector auf der Festplatte.
Wenn eine Datei groß genug ist, um mehrere blocks zu benötigen, werden alle Datensätze, die diese Datei enthalten, recordsize lang sein – einschließlich des letzten Datensatzes, der größtenteils Schlupfspeicher sein kann.
Zvols haben nicht die recordsize-Eigenschaft, sondern volblocksize, was in etwa gleichwertig ist.
Sektoren
Der letzte zu besprechende Baustein ist der niedrige sector. Ein sector ist die kleinste physikalische Einheit, die auf die zugrundeliegende device geschrieben oder von ihr gelesen werden kann. Mehrere Jahrzehnte lang verwendeten die meisten Festplatten 512 Byte sectors. In jüngerer Zeit verwenden die meisten Festplatten 4KiB sectors, und einige – insbesondere SSDs – verwenden 8KiB sectors oder sogar mehr.
ZFS hat eine Eigenschaft, mit der Sie die sector-Größe manuell einstellen können, die ashift genannt wird. Etwas verwirrend ist, dass ashift eigentlich der binäre Exponent ist, der die Sektorgröße repräsentiert – zum Beispiel bedeutet die Einstellung ashift=9, dass die sector-Größe 2^9 oder 512 Bytes beträgt.
ZFS fragt das Betriebssystem nach Details über jeden Block device ab, wenn er zu einem neuen vdev hinzugefügt wird, und setzt theoretisch ashift automatisch richtig auf der Grundlage dieser Informationen. Leider gibt es viele Festplatten, die bei der Angabe ihrer sector-Größe nach Strich und Faden lügen, um mit Windows XP kompatibel zu bleiben (das nicht in der Lage war, Festplatten mit einer anderen sector-Größe zu verstehen).
Das bedeutet, dass es für einen ZFS-Administrator sehr ratsam ist, die tatsächliche sector-Größe seiner oder ihrer devices zu kennen und ashift entsprechend manuell einzustellen. Wenn ashift zu niedrig eingestellt ist, kommt es zu einer astronomischen Lese-/Schreibverstärkung – das Schreiben eines 512-Byte-„Sektors“ auf ein reales 4KiB sector bedeutet, dass der erste „Sektor“ geschrieben, dann das 4KiB sector gelesen, mit dem zweiten 512-Byte-„Sektor“ modifiziert und wieder auf ein *neues* 4KiB sector geschrieben werden muss, und so weiter, für jeden einzelnen Schreibvorgang.
In der realen Welt trifft diese Verstärkungsstrafe eine Samsung EVO SSD – die ashift=13 haben sollte, aber über ihre Sektorgröße lügt und daher auf ashift=9 voreingestellt ist, wenn sie nicht von einem versierten Administrator überschrieben wird – hart genug, um sie langsamer als eine herkömmliche Rostplatte erscheinen zu lassen.
Im Gegensatz dazu gibt es praktisch keine Strafe für eine zu hohe Einstellung von ashift. Es gibt keine wirklichen Leistungseinbußen, und die Vergrößerung des Schlupfspeichers ist verschwindend gering (oder null, wenn die Komprimierung aktiviert ist). Wir empfehlen dringend, selbst Festplatten, die wirklich 512-Byte-Sektoren verwenden, auf ashift=12 oder sogar ashift=13 zu setzen, um für die Zukunft gerüstet zu sein.
Die ashift-Eigenschaft ist pro-vdev – nicht pro Pool, wie fälschlicherweise angenommen wird – und ist unveränderlich, wenn sie einmal gesetzt wurde. Wenn man ashift versehentlich falsch setzt, wenn man ein neues vdev zu einem Pool hinzufügt, hat man diesen Pool unwiderruflich mit einem drastisch unterdurchschnittlichen vdev kontaminiert und hat im Allgemeinen keine andere Möglichkeit, als den Pool zu zerstören und neu zu beginnen. Selbst das Entfernen von vdev kann dich nicht vor einer verpatzten ashift-Einstellung retten!
Copy-on-Write-Semantik




CoW-Copy on Write-ist eine fundamentale Grundlage, die das meiste von dem, was ZFS so großartig macht, untermauert. Das Grundkonzept ist einfach: Wenn Sie ein traditionelles Dateisystem bitten, eine Datei an Ort und Stelle zu ändern, tut es genau das, was Sie von ihm verlangen. Wenn Sie ein Copy-on-Write-Dateisystem bitten, dasselbe zu tun, sagt es „okay“ – aber es lügt Sie an.
Stattdessen schreibt das Copy-on-Write-Dateisystem eine neue Version des block, das Sie geändert haben, und aktualisiert dann die Metadaten der Datei, um die Verknüpfung des alten block aufzuheben und das neue block zu verknüpfen, das Sie gerade geschrieben haben.
Das Entkoppeln der alten block und das Einbinden der neuen Datei erfolgt in einem einzigen Vorgang, so dass er nicht unterbrochen werden kann – wenn Sie den Strom danach abschalten, haben Sie die neue Version der Datei, und wenn Sie den Strom vorher abschalten, haben Sie die alte Version. Man ist immer dateisystemkonsistent, so oder so.
Copy-on-write in ZFS ist nicht nur auf der Dateisystemebene, sondern auch auf der Plattenverwaltungsebene. Das bedeutet, dass das RAID-Loch – ein Zustand, bei dem ein Stripe nur teilweise geschrieben wird, bevor das System abstürzt, wodurch das Array inkonsistent und nach einem Neustart beschädigt wird – keine Auswirkungen auf ZFS hat. Stripe-Schreibvorgänge sind atomar, das vdev ist immer konsistent, und Bob ist dein Onkel.
ZIL-das ZFS Intent Log
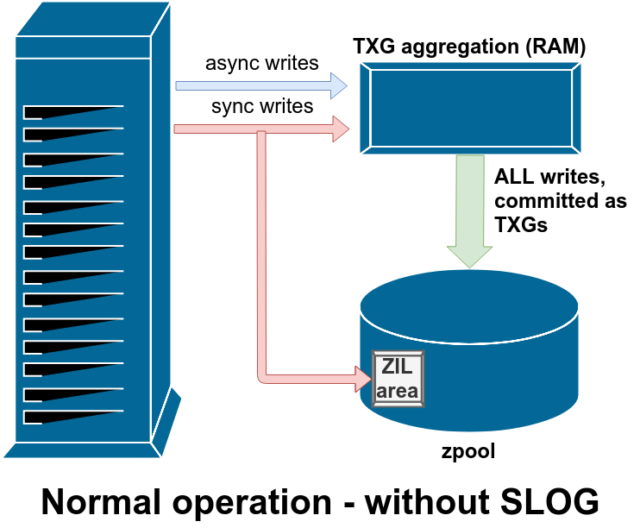

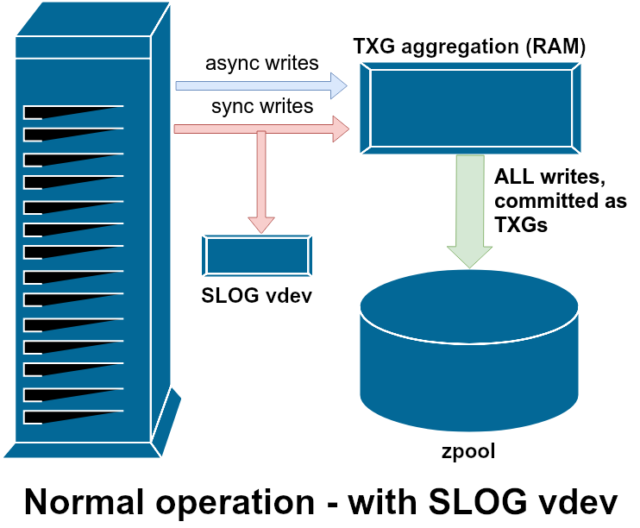

Es gibt zwei Hauptkategorien von Schreibvorgängen – synchrone (sync) und asynchrone (async). Bei den meisten Arbeitslasten sind die meisten Schreibvorgänge asynchron – das Dateisystem kann sie zusammenfassen und in Stapeln übertragen, wodurch die Fragmentierung verringert und der Durchsatz enorm gesteigert wird.
Synchrone Schreibvorgänge sind etwas völlig anderes – wenn eine Anwendung einen synchronen Schreibvorgang anfordert, teilt sie dem Dateisystem mit: „Du musst dies jetzt in einen nichtflüchtigen Speicher übertragen, und bis du das getan hast, kann ich nichts anderes tun.“ Sync-Schreibvorgänge müssen daher sofort auf die Festplatte übertragen werden – und wenn dadurch die Fragmentierung zunimmt oder der Durchsatz sinkt, dann ist das eben so.
ZFS behandelt Sync-Schreibvorgänge anders als normale Dateisysteme – anstatt Sync-Schreibvorgänge sofort in den normalen Speicher zu übertragen, überträgt ZFS sie in einen speziellen Speicherbereich namens ZFS Intent Log oder ZIL. Der Trick dabei ist, dass diese Schreibvorgänge ebenfalls im Speicher verbleiben und zusammen mit normalen asynchronen Schreibanforderungen zusammengefasst werden, um später als ganz normale TXGs (Transaktionsgruppen) in den Speicher gespült zu werden.
Im normalen Betrieb wird in das ZIL geschrieben und nie wieder daraus gelesen. Wenn in der ZIL gespeicherte Schreibvorgänge einige Augenblicke später in normalen TXGs aus dem RAM in den Hauptspeicher übertragen werden, werden sie von der ZIL getrennt. Das einzige Mal, dass aus der ZIL gelesen wird, ist beim Pool-Import.
Wenn ZFS abstürzt – oder das Betriebssystem abstürzt oder es einen unbehandelten Stromausfall gibt – während sich Daten in der ZIL befinden, werden diese Daten beim nächsten Pool-Import gelesen (z.B. wenn ein abgestürztes System neu gestartet wird). Was auch immer sich im ZIL befindet, wird eingelesen, in TXGs zusammengefasst, in den Hauptspeicher übertragen und dann während des Importvorgangs aus dem ZIL entfernt.
Eine der verfügbaren Unterstützungsklassen vdev ist LOG – auch bekannt als SLOG oder Secondary LOG device. SLOG stellt dem Pool lediglich ein separates – und hoffentlich viel schnelleres – vdev zur Verfügung, in dem die ZIL gespeichert werden, anstatt sie auf dem Hauptspeicher vdevs zu belassen. In jeder Hinsicht verhält sich das ZIL gleich, ob es sich auf dem Hauptspeicher oder auf einem LOG vdev befindet – aber wenn das LOG vdev eine sehr hohe Schreibleistung hat, dann werden die Sync-Schreibrückgaben sehr schnell erfolgen.
Das Hinzufügen eines LOG-Vdevs zu einem Pool kann und wird die asynchrone Schreibleistung nicht direkt verbessern – selbst wenn Sie alle Schreibvorgänge mit zfs set sync=always in den ZIL erzwingen, werden sie immer noch auf die gleiche Weise und mit der gleichen Geschwindigkeit in den Hauptspeicher in TXGs übertragen, wie es ohne LOG der Fall wäre. Die einzigen direkten Leistungsverbesserungen betreffen die Latenzzeit für synchrone Schreibvorgänge (da die höhere Geschwindigkeit des LOG es ermöglicht, dass der sync-Aufruf schneller zurückkehrt).
In einer Umgebung, in der bereits viele synchrone Schreibvorgänge erforderlich sind, kann ein LOG vdev jedoch indirekt auch asynchrone Schreibvorgänge und nicht zwischengespeicherte Lesevorgänge beschleunigen. Das Auslagern von ZIL-Schreibvorgängen auf ein separates LOG vdev bedeutet weniger Konkurrenz um IOPS auf dem Primärspeicher, wodurch die Leistung für alle Lese- und Schreibvorgänge bis zu einem gewissen Grad gesteigert wird.
Snapshots
Die Copy-on-Write-Semantik ist auch die notwendige Grundlage für die atomaren Snapshots von ZFS und die inkrementelle asynchrone Replikation. Das Live-Dateisystem hat einen Baum von Zeigern, die alle records markieren, die aktuelle Daten enthalten – wenn Sie einen Schnappschuss machen, erstellen Sie einfach eine Kopie dieses Baums von Zeigern.
Wenn ein Datensatz im Live-Dateisystem überschrieben wird, schreibt ZFS die neue Version des block zuerst in den unbenutzten Speicher. Dann wird die alte Version des block aus dem aktuellen Dateisystem entlinkt. Wenn jedoch ein snapshot auf das alte block verweist, bleibt es unveränderlich. Das alte block wird erst dann als freier Speicherplatz zurückgewonnen, wenn alle snapshots, die auf dieses block verweisen, zerstört wurden!
Replikation

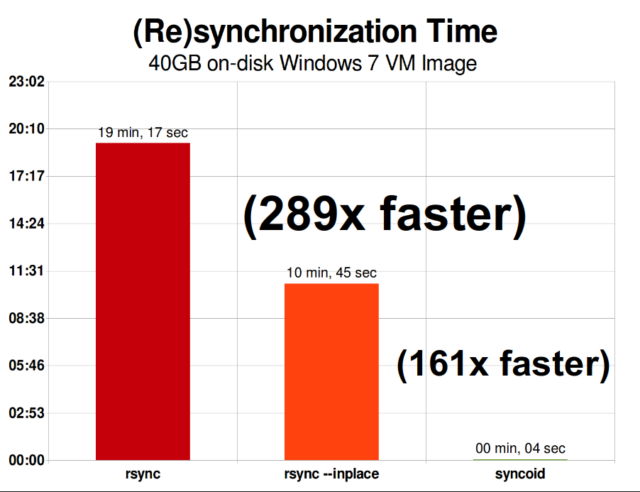
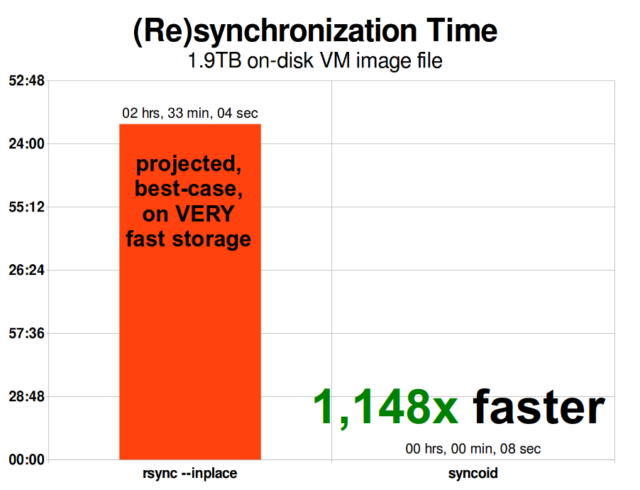 Wenn man einmal verstanden hat, wie Schnappschüsse funktionieren, ist man auch in der Lage, die Replikation zu verstehen. Da ein Snapshot einfach ein Baum von Zeigern auf
Wenn man einmal verstanden hat, wie Schnappschüsse funktionieren, ist man auch in der Lage, die Replikation zu verstehen. Da ein Snapshot einfach ein Baum von Zeigern auf
recordsist, folgt daraus, dass wir, wenn wirzfs sendeinen Snapshot senden, sowohl diesen Baum als auch alle zugehörigen Datensätze senden. Wenn wir dieseszfs sendüber die Pipeline zu einemzfs receiveauf dem Zielsystem leiten, werden sowohl der eigentlicheblock-Inhalt als auch der Baum von Zeigern, die auf dasblocksverweisen, in den Zieldatensatz geschrieben.
Die Dinge werden bei deinem zweiten zfs send interessanter. Da Sie nun zwei Systeme haben, die jeweils den Snapshot poolname/datasetname@1 enthalten, können Sie einen neuen Snapshot poolname/datasetname@2 erstellen. Auf dem Quellpool haben Sie also datasetname@1 und datasetname@2, und auf dem Zielpool haben Sie bisher nur den ersten Snapshot – datasetname@1.
Da wir einen gemeinsamen Snapshot für Quelle und Ziel haben – datasetname@1 – können wir darauf einen inkrementellen zfs send aufbauen. Wenn wir das System auffordern, zfs send -i poolname/datasetname@1 poolname/datasetname@2, vergleicht es die beiden Zeigerbäume. Alle Zeiger, die nur in @2 existieren, verweisen offensichtlich auf das neue blocks – wir brauchen also auch den Inhalt dieser blocks.
Auf dem entfernten System ist das Einfügen des resultierenden inkrementellen send ähnlich einfach. Zuerst schreiben wir alle neuen records aus, die im send-Stream enthalten sind, dann fügen wir die Zeiger auf diese blocks ein. Und schon haben wir @2 auf dem neuen System!
ZFS asynchrone inkrementelle Replikation ist eine enorme Verbesserung gegenüber früheren, nicht auf Snapshots basierenden Techniken wie rsync. In beiden Fällen müssen nur die geänderten Daten über die Leitung gesendet werden – aber rsync muss zuerst alle Daten von der Platte lesen, auf beiden Seiten, um sie zu prüfen und zu vergleichen. Im Gegensatz dazu muss die ZFS-Replikation nur die Zeigerbäume lesen – und alle blocks, die dieser Zeigerbaum enthält und die nicht bereits im gemeinsamen Snapshot vorhanden waren.
Inline-Kompression
Die Semantik des Kopierens beim Schreiben macht es auch einfacher, Inline-Kompression anzubieten. Bei einem traditionellen Dateisystem, das Änderungen an Ort und Stelle vornimmt, ist die Komprimierung problematisch – sowohl die alte als auch die neue Version der geänderten Daten müssen in genau denselben Speicherplatz passen.
Betrachten wir ein Datenpaket in der Mitte einer Datei, das zu Beginn aus 1MiB Nullen besteht –0x00000000 bis zum Gehtnichtmehr -, so ließe es sich sehr leicht auf einen einzigen Plattensektor komprimieren. Aber was passiert, wenn wir diese 1MiB Nullen durch 1MiB nicht komprimierbare Daten, wie JPEG oder Pseudo-Zufallsrauschen, ersetzen? Plötzlich benötigen diese 1MiB Daten 256 4KiB Sektoren, nicht nur einen, und das Loch in der Mitte der Datei ist nur einen Sektor breit.
ZFS hat dieses Problem nicht, da geänderte Datensätze immer in unbenutzten Speicherplatz geschrieben werden – der ursprüngliche block belegt nur einen einzigen 4KiB sector, und der neue Datensatz belegt 256 davon, aber das ist kein Problem – der neu geänderte Brocken aus der „Mitte“ der Datei wäre in unbenutzten Speicherplatz geschrieben worden, egal ob sich seine Größe geändert hätte oder nicht, also ist dieses „Problem“ für ZFS nur ein weiterer Arbeitstag.
Die Inline-Komprimierung von ZFS ist standardmäßig ausgeschaltet, und es bietet steckbare Algorithmen – derzeit einschließlich LZ4, gzip (1-9), LZJB und ZLE.
- LZ4 ist ein Stream-Algorithmus, der eine extrem schnelle Komprimierung und Dekomprimierung bietet und für die meisten Anwendungsfälle ein Leistungsgewinn ist – sogar bei sehr anämischen CPUs.
- GZIP ist der ehrwürdige Algorithmus, den alle Unix-ähnlichen Benutzer kennen und lieben. Er kann mit den Komprimierungsstufen 1-9 implementiert werden, wobei die Komprimierungsrate und der CPU-Verbrauch mit zunehmender Stufe 9 steigen. Gzip kann bei reinen Textdateien (oder anderweitig extrem komprimierbaren Dateien) ein Gewinn sein, führt aber ansonsten häufig zu CPU-Engpässen – mit Vorsicht zu verwenden, insbesondere bei höheren Stufen.
- LZJB ist der ursprüngliche Algorithmus, der von ZFS verwendet wird. Er ist veraltet und sollte nicht mehr verwendet werden – LZ4 ist in jeder Hinsicht überlegen.
- ZLE ist Zero Level Encoding – es lässt normale Daten völlig in Ruhe, komprimiert aber große Sequenzen von Nullen. Nützlich für völlig inkompressible Datensätze (z. B. JPEG, MP4 oder andere bereits komprimierte Formate), da die inkompressiblen Daten ignoriert werden, aber der Schlupfspeicher in den endgültigen Datensätzen komprimiert wird.
Wir empfehlen die LZ4-Komprimierung für fast jeden denkbaren Anwendungsfall; der Leistungsverlust bei inkompressiblen Daten ist sehr gering, und der Leistungsgewinn bei typischen Daten ist erheblich. Das Kopieren eines VM-Images für eine neue Windows-Betriebssysteminstallation (nur das installierte Windows-Betriebssystem, noch keine Daten darauf) ging in diesem Test aus dem Jahr 2015 mit compression=lz4 um 27 % schneller als mit compression=none.
ARC-der Adaptive Replacement Cache
ZFS ist das einzige moderne Dateisystem, das wir kennen, das einen eigenen Lese-Cache-Mechanismus verwendet, anstatt sich auf den Seiten-Cache des Betriebssystems zu verlassen, um Kopien von kürzlich gelesenen Blöcken im RAM zu halten.
Auch wenn der separate Cache-Mechanismus seine Probleme hat – ZFS kann nicht so unmittelbar wie der Kernel auf neue Anfragen zur Speicherallokation reagieren, und daher kann ein neuer mallocate() Aufruf fehlschlagen, wenn er RAM benötigt, das gerade vom ARC belegt ist – gibt es gute Gründe, zumindest im Moment, sich damit abzufinden.
Jedes bekannte moderne Betriebssystem – einschließlich MacOS, Windows, Linux und BSD – verwendet den LRU-Algorithmus (Least Recently Used) für seine Seitencache-Implementierung. LRU ist ein naiver Algorithmus, der einen Cache-Block bei jedem Lesevorgang an die Spitze der Warteschlange befördert und Blöcke vom unteren Ende der Warteschlange entfernt, um neue Cache-Misses (Blöcke, die von der Festplatte und nicht aus dem Cache gelesen werden mussten) an der Spitze hinzuzufügen.“
Das ist soweit in Ordnung, aber in Systemen mit großen Arbeitsdatensätzen kann LRU leicht in „Thrashing“ enden, d.h. es werden sehr häufig benötigte Blöcke verdrängt, um Platz für Blöcke zu schaffen, die nie wieder aus dem Cache gelesen werden.
Der ARC ist ein viel weniger naiver Algorithmus, den man sich als „gewichteten“ Cache vorstellen kann. Jedes Mal, wenn ein Cache-Block gelesen wird, wird er ein wenig „schwerer“ und schwieriger zu verdrängen – und selbst nach einer Verdrängung wird der verdrängte Block noch eine Zeit lang verfolgt. Ein Block, der verdrängt wurde, dann aber wieder in den Cache eingelesen werden muss, wird ebenfalls „schwerer“ und ist schwieriger zu verdrängen.
Das Endergebnis all dieser Maßnahmen ist ein Cache mit typischerweise weitaus höheren Trefferquoten – dem Verhältnis zwischen Cache-Treffern (aus dem Cache gelieferte Lesevorgänge) und Cache-Fehlversuchen (von der Festplatte gelieferte Lesevorgänge). Dies ist eine äußerst wichtige Statistik – nicht nur die Cache-Treffer selbst werden um Größenordnungen schneller bedient, sondern auch die Cache-Misses können schneller bedient werden, da mehr Cache-Treffer==weniger gleichzeitige Anfragen an die Festplatte==geringere Latenzzeit für die verbleibenden Misses, die von der Festplatte bedient werden müssen.
Abschluss
Nachdem wir nun die grundlegende Semantik von ZFS behandelt haben, wie Copy-on-Write funktioniert und die Beziehungen zwischen Pools, Vdevs, Blöcken, Sektoren und Dateien, sind wir bereit, über die tatsächliche Leistung zu sprechen, mit echten Zahlen.
Bleiben Sie dran für den nächsten Teil unserer Serie über Speichergrundlagen, um die tatsächliche Leistung von Pools mit Mirror- und RAIDz-Vdevs im Vergleich zueinander und zu den traditionellen Linux-Kernel-RAID-Topologien zu sehen, die wir zuvor untersucht haben.
Zunächst werden wir nur die Grundlagen abdecken – die ZFS-Topologien selbst – aber danach werden wir bereit sein, über fortgeschrittenere ZFS-Einrichtung und -Einstellung zu sprechen, einschließlich der Verwendung von unterstützenden vdev-Typen wie L2ARC, SLOG und Special Allocation.