
Serhii Maksymenko,
Arquitecto de soluciones de ciencias de la información
La tecnología de reconocimiento facial aparece bajo una luz diferente hoy en día. Los casos de uso incluyen una amplia aplicación, desde la detección de delitos hasta la identificación de enfermedades genéticas.
Mientras que los gobiernos de todo el mundo han invertido en sistemas de reconocimiento facial, algunas ciudades estadounidenses, como Oakland, Somerville y Portland, lo han prohibido por motivos de derechos civiles y privacidad.
¿Qué es, una bomba de relojería o un avance tecnológico? Este artículo abre lo que es el reconocimiento facial desde una perspectiva tecnológica, y cómo el aprendizaje profundo aumenta sus capacidades. Solo comprendiendo cómo funciona la tecnología de reconocimiento facial desde dentro, es posible entender de qué es capaz.
Actualización 06/09/2020: Detección y reconocimiento de rostros enmascarados
Cómo el aprendizaje profundo puede modernizar el software de reconocimiento facial
Descargar PDF
¿Cómo funciona el reconocimiento facial?
El algoritmo informático del software de reconocimiento facial se parece un poco al reconocimiento visual humano. Pero si las personas almacenan datos visuales en el cerebro y recuerdan automáticamente los datos visuales una vez que los necesitan, los ordenadores deberían solicitar datos de una base de datos y hacerlos coincidir para identificar un rostro humano.
En pocas palabras, un sistema informático equipado con una cámara, detecta e identifica un rostro humano, extrae los rasgos faciales como la distancia entre los ojos, la longitud de la nariz, la forma de la frente y los pómulos. A continuación, el sistema reconoce el rostro y lo compara con las imágenes almacenadas en una base de datos.
Sin embargo, la tecnología tradicional de reconocimiento facial no es del todo perfecta. Tiene tanto puntos fuertes como débiles:
| Fortaleza
Identificación biométrica sin contacto Procesamiento de datos de hasta un segundo Compatibilidad con la mayoría de las cámaras La facilidad de integración |
Debilidades
y el sesgo racial Problemas de privacidad de los datos Ataques de presentación (PA) Poca precisión en condiciones de poca luz |
Realización de las debilidades de los sistemas de reconocimiento facial, los científicos de datos fueron más allá. Aplicando técnicas tradicionales de visión por ordenador y algoritmos de aprendizaje profundo, afinaron el sistema de reconocimiento facial para evitar ataques y mejorar la precisión. Así funciona una tecnología antispoofing de rostros.
Cómo el aprendizaje profundo mejora el software de reconocimiento facial
El aprendizaje profundo es una de las formas más novedosas de mejorar la tecnología de reconocimiento facial. La idea es extraer incrustaciones faciales de imágenes con rostros. Dichas incrustaciones faciales serán únicas para diferentes rostros. Y el entrenamiento de una red neuronal profunda es la forma más óptima de realizar esta tarea.
Dependiendo de una tarea y de los plazos, hay dos métodos comunes para utilizar el aprendizaje profundo para los sistemas de reconocimiento facial:
Utilizar modelos preentrenados como dlib, DeepFace, FaceNet y otros. Este método requiere menos tiempo y esfuerzo porque los modelos preentrenados ya tienen un conjunto de algoritmos para fines de reconocimiento facial. También podemos afinar los modelos preentrenados para evitar sesgos y dejar que el sistema de reconocimiento facial funcione correctamente.
Desarrollar una red neuronal desde cero. Este método es adecuado para sistemas complejos de reconocimiento de rostros que tengan una funcionalidad polivalente. Lleva más tiempo y esfuerzo, y requiere millones de imágenes en el conjunto de datos de entrenamiento, a diferencia de un modelo preentrenado que sólo requiere miles de imágenes en el caso del aprendizaje por transferencia.

Pero si el sistema de reconocimiento facial incluye características únicas, puede ser una forma óptima a largo plazo. Los puntos clave a los que hay que prestar atención son:
- La correcta selección de la arquitectura CNN y de la función de pérdida
- Optimización del tiempo de inferencia
- La potencia de un hardware
Se recomienda utilizar redes neuronales convolucionales (CNN) a la hora de desarrollar una arquitectura de red, ya que han demostrado su eficacia en tareas de reconocimiento y clasificación de imágenes. Para obtener los resultados esperados, es mejor utilizar una arquitectura de red neuronal generalmente aceptada como base, por ejemplo, ResNet o EfficientNet.
Cuando se entrena una red neuronal con fines de desarrollo de software de reconocimiento facial, debemos minimizar los errores en la mayoría de los casos. Aquí es crucial considerar las funciones de pérdida utilizadas para el cálculo del error entre la salida real y la predicha. Las funciones más utilizadas en los sistemas de reconocimiento facial son la pérdida de triplete y la AM-Softmax.
- La función de pérdida de triplete implica tener tres imágenes de dos personas diferentes. Hay dos imágenes – ancla y positiva – para una persona, y la tercera – negativa – para otra persona. Los parámetros de la red se aprenden para acercar a las mismas personas en el espacio de características y separar a personas diferentes.
- La función AM-Softmax es una de las modificaciones más recientes de la función softmax estándar, que utiliza una regularización particular basada en un margen aditivo. Permite lograr una mejor separabilidad de las clases y, por lo tanto, mejora la precisión del sistema de reconocimiento facial.
También hay varios enfoques para mejorar una red neuronal. En los sistemas de reconocimiento facial, los más interesantes son la destilación de conocimiento, el aprendizaje de transferencia, la cuantización y las convoluciones separadas en profundidad.
- La destilación de conocimiento implica dos redes de diferente tamaño cuando una red grande enseña su propia variación más pequeña. El valor clave es que, tras el entrenamiento, la red más pequeña funciona más rápido que la grande, dando el mismo resultado.
- El enfoque de aprendizaje por transferencia permite mejorar la precisión mediante el entrenamiento de toda la red o sólo de ciertas capas en un conjunto de datos específico. Por ejemplo, si el sistema de reconocimiento de rostros tiene problemas de sesgo racial, podemos tomar un conjunto concreto de imágenes, por ejemplo, fotos de chinos, y entrenar la red para alcanzar una mayor precisión.
- El enfoque de cuantificación mejora una red neuronal para alcanzar una mayor velocidad de procesamiento. Al aproximar una red neuronal que utiliza números de punto flotante por una red neuronal de números de baja anchura de bits, podemos reducir el tamaño de la memoria y el número de cálculos.
- Las convoluciones separables en profundidad son una clase de capas que permiten construir CNN con un conjunto de parámetros mucho menor en comparación con las CNN estándar. Al tener un número reducido de cómputos, esta característica puede mejorar el sistema de reconocimiento facial para hacerlo apto para aplicaciones de visión móvil.
El elemento clave de las tecnologías de aprendizaje profundo es la demanda de hardware de alta potencia. Cuando se utilizan redes neuronales profundas para el desarrollo de software de reconocimiento facial, el objetivo no es solo mejorar la precisión del reconocimiento, sino también reducir el tiempo de respuesta. Por eso, la GPU, por ejemplo, es más adecuada para los sistemas de reconocimiento facial impulsados por el aprendizaje profundo, que la CPU.
Cómo implementamos la aplicación de reconocimiento facial impulsada por el aprendizaje profundo
Cuando desarrollamos Big Brother (una aplicación de cámara de demostración) en MobiDev, nuestro objetivo era crear un software de verificación biométrica con transmisión de vídeo en tiempo real. Siendo una aplicación de consola local para Ubuntu y Raspbian, Big Brother está escrito en Golang, y configurado con el ID de la cámara local y el tipo de lector de cámara a través del archivo de configuración JSON. Este vídeo describe cómo funciona Big Brother en la práctica:
Desde dentro, el ciclo de trabajo de la app Big Brother comprende:
1. Detección de rostros
La aplicación detecta rostros en un flujo de vídeo. Una vez capturada la cara, la imagen se recorta y se envía al back-end a través de una solicitud de datos de formulario HTTP. La API del back-end guarda la imagen en un sistema de archivos local y guarda un registro en el Log de Detección con un personID.
El back-end utiliza Golang y MongoDB Collections para almacenar los datos de los empleados. Todas las solicitudes de la API se basan en la API RESTful.

2. Reconocimiento facial instantáneo
El back end tiene un trabajador en segundo plano que encuentra nuevos registros sin clasificar y utiliza Dlib para calcular el vector descriptor de 128 dimensiones de las características de la cara. Cada vez que se calcula un vector, se compara con múltiples imágenes faciales de referencia calculando la distancia euclidiana a cada vector de características de cada persona de la base de datos, encontrando una coincidencia.
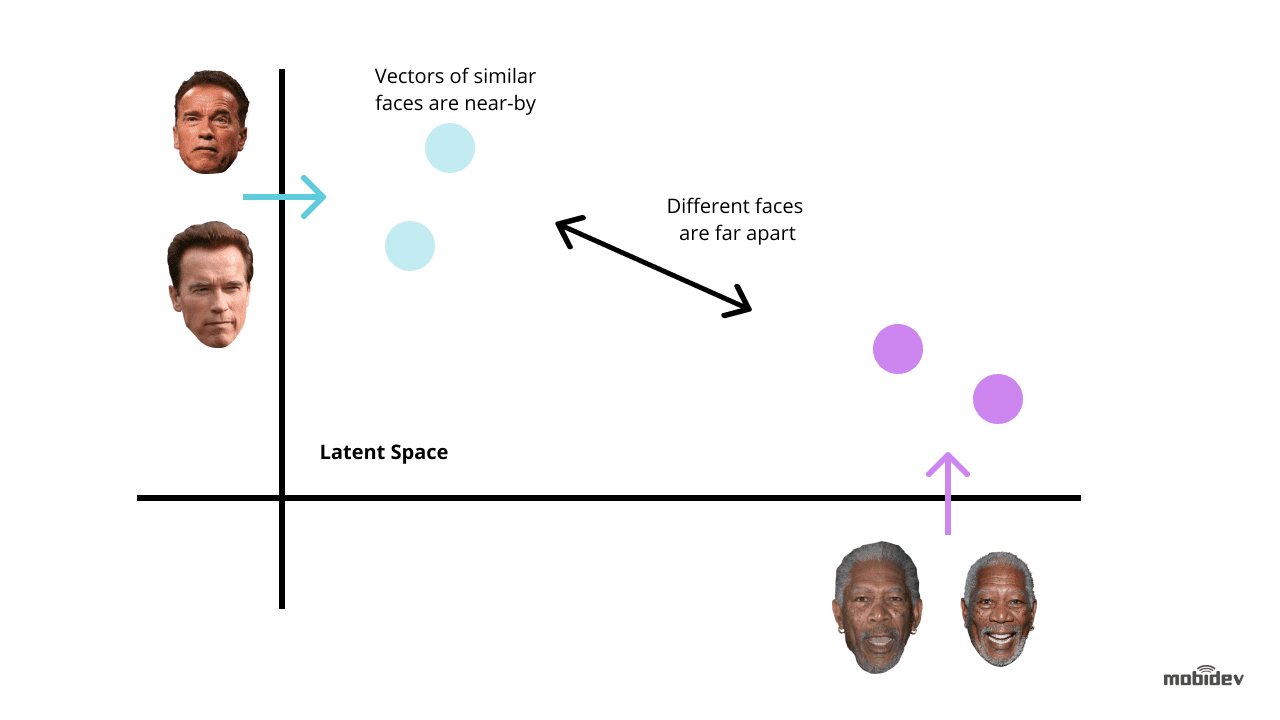
Si la distancia euclidiana a la persona detectada es inferior a 0,6, el trabajador establece un personID en el registro de detección y lo marca como clasificado. Si la distancia es superior a 0,6, crea un nuevo personID al registro.
3. Acciones de seguimiento: alertar, conceder acceso y otras
Las imágenes de una persona no identificada se envían al gestor correspondiente con notificaciones a través de chatbots en messengers. En la aplicación de Gran Hermano, hemos utilizado Microsoft Bot Framework y Errbot basado en Python, lo que nos ha permitido implementar el chatbot de alerta en cinco días.

Después, estos registros se pueden gestionar a través del panel de administración, que almacena las fotos con las identificaciones en la base de datos. El software de reconocimiento facial funciona en tiempo real y realiza las tareas de reconocimiento facial al instante. Utilizando Golang y MongoDB Collections para el almacenamiento de datos de los empleados, entramos en la base de datos de IDs, incluyendo 200 entradas.
Así es como está diseñada la aplicación de reconocimiento facial del Gran Hermano:
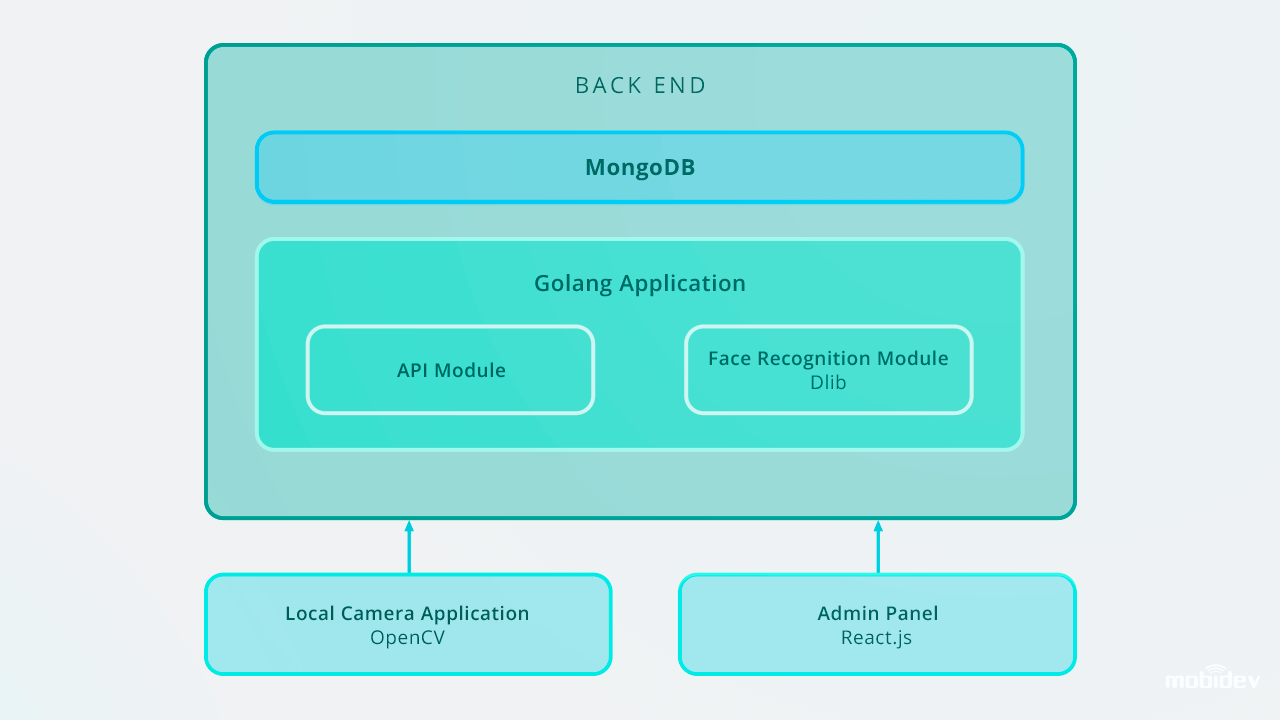
En el caso de escalar hasta 10.000 entradas, recomendaríamos mejorar el sistema de reconocimiento facial para mantener una alta velocidad de reconocimiento en el back end. Una de las formas óptimas es utilizar la paralelización. Configurando un equilibrador de carga y construyendo varios web workers, podemos asegurar el trabajo adecuado de una parte del back end y la velocidad óptima de todo un sistema.
Otros casos de uso del reconocimiento basado en deep learning
El reconocimiento facial no es la única tarea en la que el desarrollo de software basado en deep learning puede mejorar el rendimiento. Otros ejemplos incluyen:
Detección y reconocimiento de rostros enmascarados
Desde que el COVID-19 hizo que la gente de muchos países usara máscaras faciales, la tecnología de reconocimiento facial se volvió más avanzada. Utilizando el algoritmo de aprendizaje profundo basado en redes neuronales convolucionales, las cámaras pueden ahora reconocer rostros cubiertos con máscaras. Los ingenieros de la ciencia de los datos utilizan algoritmos como los modelos de reconocimiento periocular y de multigranularidad basados en la cara para mejorar las capacidades del sistema de reconocimiento facial. Mediante la identificación de rasgos faciales como la frente, el contorno de la cara, los detalles oculares y perioculares, las cejas, los ojos y los pómulos, estos modelos permiten reconocer rostros enmascarados con una precisión de hasta el 95%.
Un buen ejemplo de este sistema es la tecnología de reconocimiento facial creada por una de las empresas chinas. El sistema consta de dos algoritmos: el reconocimiento facial basado en el aprendizaje profundo y la medición de la temperatura por imágenes térmicas infrarrojas. Cuando las personas con máscaras faciales se ponen delante de la cámara, el sistema extrae los rasgos faciales y los compara con las imágenes existentes en la base de datos. Al mismo tiempo, el mecanismo de medición de temperatura por infrarrojos mide la temperatura, detectando así a las personas con temperaturas anormales.
Detección de defectos
En el último par de años, los fabricantes han estado utilizando la inspección visual basada en IA para la detección de defectos. El desarrollo de algoritmos de aprendizaje profundo permite a este sistema definir los más pequeños arañazos y grietas de forma automática, evitando el factor humano.
Detección de anomalías corporales
La empresa israelí Aidoc desarrolló una solución potenciada por el aprendizaje profundo para radiología. Mediante el análisis de imágenes médicas, este sistema detecta anomalías en el tórax, la columna vertebral, la cabeza y el abdomen.
Identificación de hablantes
La tecnología de identificación de hablantes creada por la empresa Phonexia también identifica a los hablantes utilizando el enfoque de aprendizaje métrico. El sistema reconoce a los hablantes por su voz, produciendo modelos matemáticos del habla humana denominados voiceprints. Esas huellas de voz se almacenan en bases de datos y, cuando una persona habla, la tecnología de identificación de hablantes identifica la huella de voz única.
Reconocimiento de emociones
El reconocimiento de emociones humanas es una tarea factible hoy en día. Mediante el seguimiento de los movimientos de un rostro a través de la cámara, la tecnología de reconocimiento de emociones categoriza las emociones humanas. El algoritmo de aprendizaje profundo identifica los puntos de referencia de un rostro humano, detecta una expresión facial neutra y mide las desviaciones de las expresiones faciales reconociendo las más positivas o negativas.
Reconocimiento de acciones
La empresa Visual One, que es proveedora de Nest Cams, potenció su producto con IA. Utilizando técnicas de aprendizaje profundo, perfeccionaron las Nest Cams para reconocer no solo diferentes objetos como personas, mascotas, coches, etc., sino también para identificar acciones. El conjunto de acciones a reconocer es personalizable y seleccionado por el usuario. Por ejemplo, una cámara puede reconocer a un gato que rasca la puerta, o a un niño que juega con la estufa.
Si resumimos, las redes neuronales profundas son una poderosa herramienta para la humanidad. Y sólo un humano decide qué futuro tecnológico se avecina.
Cómo el aprendizaje profundo puede modernizar el software de reconocimiento facial
Descargar PDF