
Mientras todos entramos en el tercer mes de la pandemia de COVID-19 y buscamos nuevos proyectos para mantenernos ocupados (léase: cuerdos), ¿podemos interesarnos en aprender los fundamentos del almacenamiento informático? A lo largo de esta primavera, ya hemos repasado algunos aspectos básicos necesarios, como la forma de comprobar la velocidad de los discos y qué demonios es el RAID. En la segunda de esas historias, incluso prometimos un seguimiento que explorara el rendimiento de varias topologías de discos múltiples en ZFS, el sistema de archivos de próxima generación del que has oído hablar por su aparición en todas partes, desde Apple hasta Ubuntu.
Bueno, hoy es el día para explorar, lectores curiosos de ZFS. Sólo hay que saber de antemano que, en las discretas palabras del desarrollador de OpenZFS, Matt Ahrens, «es realmente complicado».
Pero antes de llegar a los números -¡y ya vienen, lo prometo!-para todas las formas en que puede dar forma a ocho discos de ZFS, tenemos que hablar de cómo ZFS almacena sus datos en el disco en primer lugar.
Zpools, vdevs, y dispositivos
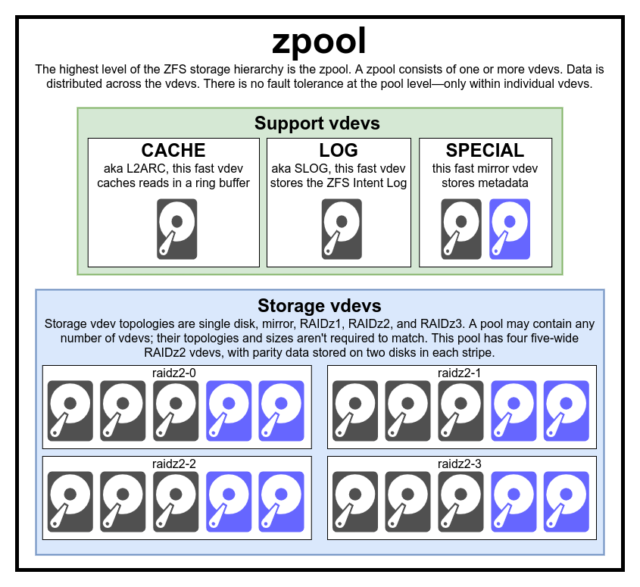

Para entender realmente ZFS, es necesario prestar verdadera atención a su estructura real. ZFS fusiona las capas tradicionales de gestión de volúmenes y de sistemas de archivos, y utiliza un mecanismo transaccional de copia en escritura; ambos significan que el sistema es muy diferente estructuralmente a los sistemas de archivos convencionales y a las matrices RAID. El primer conjunto de bloques principales que hay que entender son zpools, vdevs y devices.
zpool
El zpool es la estructura superior de ZFS. Un zpool contiene uno o más vdevs, cada uno de los cuales contiene a su vez uno o más devices. Los zpools son unidades autónomas: un ordenador físico puede tener dos o más zpools separados en él, pero cada uno es totalmente independiente de los demás. Los zpools no pueden compartir vdevs entre sí.
La redundancia de ZFS está en el nivel vdev, no en el nivel zpool. No hay absolutamente ninguna redundancia en el nivel zpool-si cualquier almacenamiento vdev o SPECIAL vdev se pierde, todo el zpool se pierde con él.
Los zpools modernos pueden sobrevivir a la pérdida de un CACHE o LOG vdev-aunque pueden perder una pequeña cantidad de datos sucios, si pierden un LOG vdev durante un corte de energía o caída del sistema.
Es un error común que ZFS «rayas» escribe a través de la piscina-pero esto es inexacto. Un zpool no es un RAID0 de aspecto gracioso, es un JBOD de aspecto gracioso, con un complejo mecanismo de distribución sujeto a cambios.
Por lo general, las escrituras se distribuyen entre los vdevs disponibles de acuerdo con su espacio libre disponible, de modo que todos los vdevs teóricamente se llenarán al mismo tiempo. En versiones más recientes de ZFS, la utilización de vdev también puede ser tomada en cuenta-si un vdev está significativamente más ocupado que otro (por ejemplo, debido a la carga de lectura), puede ser omitido temporalmente para escribir a pesar de tener la mayor proporción de espacio libre disponible.
El mecanismo de conocimiento de la utilización incorporado en los métodos modernos de distribución de escritura de ZFS puede disminuir la latencia y aumentar el rendimiento durante períodos de carga inusualmente alta, pero no debe confundirse con una carta blanca para mezclar discos lentos de óxido y SSDs rápidos en la misma piscina. Este tipo de pool desajustado funcionará, por lo general, como si estuviera compuesto en su totalidad por el dispositivo más lento presente.
vdev
Cada zpool consta de uno o más vdevs (abreviatura de dispositivo virtual). Cada vdev, a su vez, consta de uno o más devices reales. La mayoría de los vdev se utilizan para el almacenamiento simple, pero también existen varias clases de soporte especial de vdev-incluyendo CACHE, LOG, y SPECIAL. Cada uno de estos tipos de vdev puede ofrecer una de las cinco topologías-un solo dispositivo, RAIDz1, RAIDz2, RAIDz3, o espejo.
RAIDz1, RAIDz2, y RAIDz3 son variedades especiales de lo que los guardianes del almacenamiento llaman «RAID de paridad diagonal». Los números 1, 2 y 3 se refieren a cuántos bloques de paridad se asignan a cada franja de datos. En lugar de tener discos enteros dedicados a la paridad, los vdev RAIDz distribuyen esa paridad de forma semiparalizada entre los discos. Una matriz RAIDz puede perder tantos discos como bloques de paridad tenga; si pierde otro, falla y se lleva el zpool con él.
Los vdev espejo son precisamente lo que parecen: en un vdev espejo, cada bloque se almacena en cada dispositivo del vdev. Aunque las réplicas de dos anchos son las más comunes, un vdev de réplica puede contener cualquier número arbitrario de dispositivos-los de tres vías son comunes en las configuraciones más grandes por el mayor rendimiento de lectura y la resistencia a los fallos. Un vdev espejo puede sobrevivir a cualquier fallo, siempre y cuando al menos un dispositivo en el vdev permanezca sano.
Los vdev de un solo dispositivo también son tal como suenan-y son inherentemente peligrosos. Un vdev de un solo dispositivo no puede sobrevivir a ningún fallo-y si se está utilizando como vdev de almacenamiento o SPECIAL, su fallo se llevará todo el zpool con él. Tenga mucho, mucho cuidado aquí.
CACHE, LOG, y SPECIAL vdevs se puede crear utilizando cualquiera de las topologías anteriores-pero recuerde, la pérdida de un SPECIAL vdev significa la pérdida de la piscina, por lo que la topología redundante se recomienda encarecidamente.
device
Este es probablemente el término relacionado con ZFS más fácil de entender-es, literalmente, sólo un dispositivo de bloque de acceso aleatorio. Recuerde, vdevs están hechos de dispositivos individuales, y el zpool está hecho de vdevs.
Los discos -ya sea de óxido o de estado sólido- son los dispositivos de bloque más comunes utilizados como bloques de construcción vdev. Cualquier cosa con un descriptor en /dev que permita el acceso aleatorio funcionará, sin embargo-así que las matrices RAID de hardware enteras pueden ser (y a veces son) utilizadas como dispositivos individuales.
El simple archivo en bruto es uno de los dispositivos de bloque alternativos más importantes con los que se puede construir un vdev. Los pools de prueba hechos de archivos dispersos son una forma increíblemente conveniente de practicar los comandos de zpool, y ver cuánto espacio está disponible en un pool o vdev de una topología determinada.

Digamos que está pensando en construir un servidor de ocho bahías, y está bastante seguro de que querrá utilizar discos de 10TB (~9300 GiB), pero no está seguro de qué topología se adapta mejor a sus necesidades. En el ejemplo anterior, construimos un pool de prueba con archivos dispersos en segundos, y ahora sabemos que un vdev RAIDz2 formado por ocho discos de 10TB ofrece 50TiB de capacidad utilizable.
Hay una clase especial de deviceel SPARE. Los dispositivos Hotspare, a diferencia de los normales, pertenecen a todo el pool, no a un solo vdev. Si cualquier vdev del pool sufre un fallo de dispositivo y hay un SPARE conectado al pool y disponible, el SPARE se conectará automáticamente al vdev degradado.
Una vez conectado al vdev degradado, el SPARE comienza a recibir copias o reconstrucciones de los datos que deberían estar en el dispositivo perdido. En el RAID tradicional, esto se llamaría «reconstrucción»; en ZFS, se llama «resilvering».
Es importante tener en cuenta que los dispositivos SPARE no sustituyen permanentemente a los dispositivos fallidos. Son sólo marcadores de posición, destinados a minimizar la ventana durante la cual un vdev funciona degradado. Una vez que el administrador ha reemplazado el dispositivo fallido del vdev y el nuevo dispositivo de reemplazo permanente se reinicia, el SPARE se separa del vdev, y vuelve a la tarea de todo el grupo.
Conjuntos de datos, bloques y sectores
El siguiente conjunto de bloques de construcción que tendrá que entender en su viaje ZFS se relaciona no tanto con el hardware, sino con la forma en que los datos en sí se organizan y almacenan. Nos saltamos algunos niveles aquí -como el meta-labio- con el fin de mantener las cosas lo más sencillas posible, sin dejar de entender la estructura general.
Conjuntos de datos
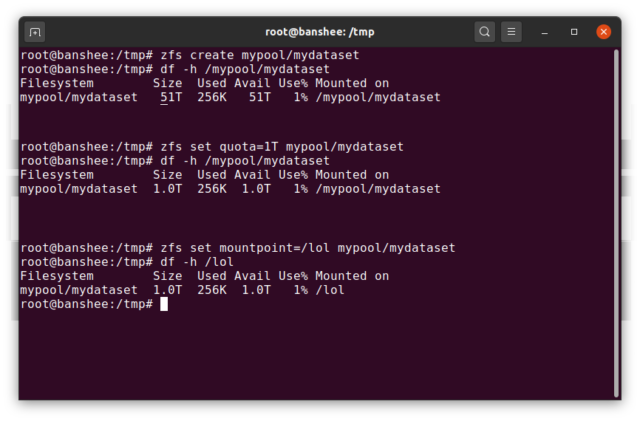

Un ZFS datasetes más o menos análogo a un sistema de archivos estándar, montado -como un sistema de archivos convencional, parece a la inspección casual como si fuera «sólo otra carpeta». Pero también como los sistemas de archivos montados convencionales, cada ZFS dataset tiene su propio conjunto de propiedades subyacentes.
En primer lugar, un dataset puede tener una cuota asignada. Si zfs set quota=100G poolname/datasetname, no podrá poner más de 100GiB de datos en la carpeta montada en el sistema /poolname/datasetname.
¿Nota la presencia -y ausencia- de barras inclinadas en el ejemplo anterior? Cada conjunto de datos tiene su lugar tanto en la jerarquía ZFS como en la jerarquía de montaje del sistema. En la jerarquía ZFS, no hay barras iniciales: se comienza con el nombre del pool y luego la ruta de un conjunto de datos al siguiente; por ejemplo, pool/parent/child para un conjunto de datos llamado child bajo el conjunto de datos padre parent, en un pool llamado creativamente pool.
Por defecto, el punto de montaje de un dataset será equivalente a su nombre jerárquico de ZFS, con una barra inclinada al principio: el grupo llamado pool se monta en /pool, el conjunto de datos parent se monta en /pool/parent, y el conjunto de datos hijo child se monta en /pool/parent/child. El punto de montaje del sistema de un conjunto de datos puede ser alterado, sin embargo.
Si fuéramos a zfs set mountpoint=/lol pool/parent/child, el conjunto de datos pool/parent/child sería realmente montado en el sistema como /lol.
Además de los conjuntos de datos, debemos mencionar zvols. Un zvol es más o menos análogo a un dataset, excepto que en realidad no tiene un sistema de archivos en él – es sólo un dispositivo de bloque. Podrías, por ejemplo, crear un zvol llamado mypool/myzvol, luego formatearlo con el sistema de archivos ext4, luego montar ese sistema de archivos-¡ahora tienes un sistema de archivos ext4, pero respaldado con todas las características de seguridad de ZFS! Esto puede parecer una tontería en un solo ordenador, pero tiene mucho más sentido como extremo posterior de una exportación iSCSI.
Bloques
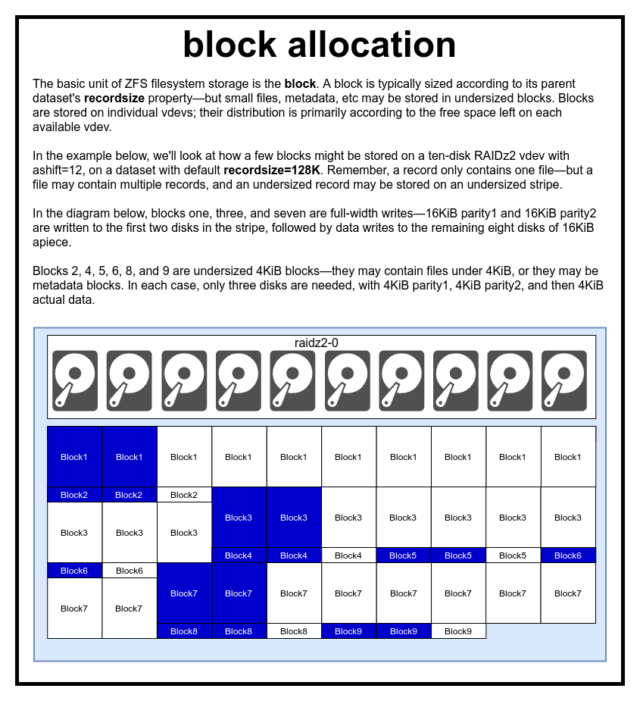

En un pool ZFS, todos los datos -incluidos los metadatos- se almacenan en blocks. El tamaño máximo de un block se define para cada dataset en la propiedad recordsize. El tamaño de los registros es mutable, pero el cambio de recordsize no cambiará el tamaño o la disposición de cualquier blocks que ya se haya escrito en el conjunto de datos, sólo para los nuevos bloques que se escriban.
Si no se define de otro modo, el recordsize actual por defecto es de 128KiB. Esto representa una especie de compromiso incómodo en el que el rendimiento no será ideal para casi nada, pero tampoco será horrible para casi nada. Recordsize puede ser ajustado a cualquier valor desde 4K hasta 1M. (Recordsize se puede establecer incluso más grande con el ajuste adicional y la determinación suficiente, pero que rara vez es una buena idea.)
Cualquier block referencias a los datos de un solo archivo-no se puede meter dos archivos separados en el mismo block. Cada archivo estará compuesto por uno o más blocks, dependiendo del tamaño. Si un archivo es más pequeño que recordsize, se almacenará en un bloque de tamaño inferior; por ejemplo, un block que contenga un archivo de 2KiB sólo ocupará un único sector de 4KiB en el disco.
Si un archivo es lo suficientemente grande como para requerir varios blocks, todos los registros que contengan ese archivo tendrán una longitud de recordsize, incluido el último registro, que puede ser en su mayoría espacio libre.
Zvols no tienen la propiedad recordsize – en su lugar, tienen volblocksize, que es aproximadamente equivalente.
Sectores
El último bloque de construcción a discutir es el humilde sector. Un sector es la unidad física más pequeña en la que se puede escribir o leer su device subyacente. Durante varias décadas, la mayoría de los discos utilizaban sectors de 512 bytes. Más recientemente, la mayoría de los discos utilizan sectors de 4KiB, y algunos -particularmente los SSD- utilizan sectors de 8KiB, o incluso más grandes.
ZFS tiene una propiedad que le permite establecer manualmente el tamaño de sector, llamado ashift. Algo confuso, ashift es en realidad el exponente binario que representa el tamaño del sector-por ejemplo, establecer ashift=9 significa que el tamaño de su sector será 2^9, o 512 bytes.
ZFS consulta al sistema operativo para obtener detalles sobre cada bloque device a medida que se agrega a un nuevo vdev, y en teoría establecerá automáticamente ashift adecuadamente basado en esa información. Desgraciadamente, hay muchos discos que mienten descaradamente sobre cuál es su tamaño sector, para seguir siendo compatibles con Windows XP (que era incapaz de entender los discos con cualquier otro tamaño sector).
Esto significa que se recomienda encarecidamente a un administrador de ZFS que sea consciente del tamaño real sector de su devices, y que establezca manualmente ashift en consecuencia. Si ashift se establece demasiado bajo, se incurre en una pena astronómica de amplificación de lectura/escritura – escribir un «sector» de 512 bytes en un sector real de 4KiB significa tener que escribir el primer «sector», luego leer el sector de 4KiB, modificarlo con el segundo «sector» de 512 bytes, escribirlo de nuevo en un sector de 4KiB *nuevo*, y así sucesivamente, para cada escritura.
En términos del mundo real, esta penalización de amplificación golpea a un SSD Samsung EVO-que debería tener ashift=13, pero miente sobre el tamaño de su sector y por lo tanto se pone por defecto en ashift=9 si no es anulado por un administrador inteligente-lo suficientemente duro como para hacer que parezca más lento que un disco convencional de óxido.
Por el contrario, no hay prácticamente ninguna penalización al establecer ashift demasiado alto. No hay ninguna penalización real de rendimiento, y los aumentos de espacio de holgura son infinitesimales (o cero, con la compresión activada). Recomendamos encarecidamente que incluso los discos que realmente utilizan sectores de 512 bytes se establezcan en ashift=12 o incluso en ashift=13 para estar preparados para el futuro.
La propiedad ashift es por-vdev -no por pool, como se piensa comúnmente y de forma errónea- y es inmutable, una vez establecida. Si accidentalmente se equivoca con ashift al añadir un nuevo vdev a un pool, ha contaminado irrevocablemente ese pool con un vdev de rendimiento drásticamente inferior, y generalmente no tiene otro recurso que destruir el pool y empezar de nuevo. Ni siquiera la eliminación de vdev puede salvarle de una configuración ashift defectuosa.
La semántica de copia en escritura




CoW -copia en escritura- es una base fundamental bajo la mayor parte de lo que hace que ZFS sea impresionante. El concepto básico es simple: si le pides a un sistema de archivos tradicional que modifique un archivo en su lugar, hace precisamente lo que le has pedido. Si le pides a un sistema de archivos de copia en escritura que haga lo mismo, te dice «vale», pero te está mintiendo.
En cambio, el sistema de archivos de copia en escritura escribe una nueva versión del block que has modificado, y luego actualiza los metadatos del archivo para desvincular el antiguo block y vincular el nuevo block que acabas de escribir.
La desvinculación de la antigua block y la vinculación de la nueva se lleva a cabo en una sola operación, por lo que no puede ser interrumpida-si se vuelca la energía después de que suceda, se tiene la nueva versión del archivo, y si se vuelca la energía antes, entonces se tiene la versión antigua. Siempre eres consistente con el sistema de archivos, de cualquier manera.
La copia en escritura en ZFS no es sólo a nivel de sistema de archivos, también es a nivel de gestión de disco. Esto significa que el agujero RAID -una condición en la que una franja sólo se escribe parcialmente antes de que el sistema se bloquee, haciendo que la matriz sea inconsistente y corrupta después de un reinicio- no afecta a ZFS. Las escrituras en la franja son atómicas, el vdev es siempre consistente, y Bob es tu tío.
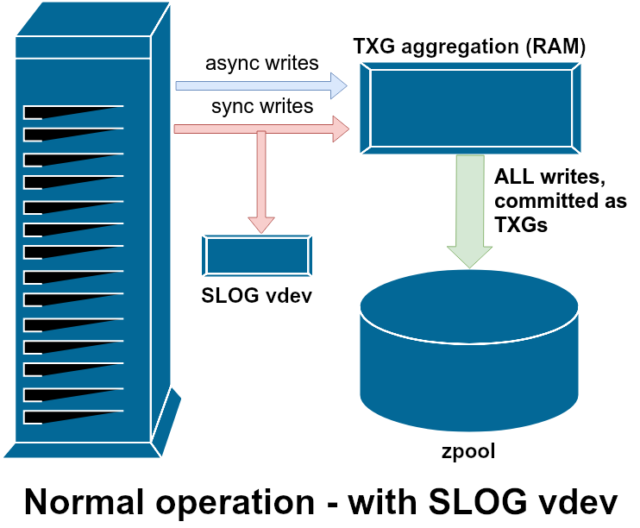
ZIL-el registro de intenciones de ZFS
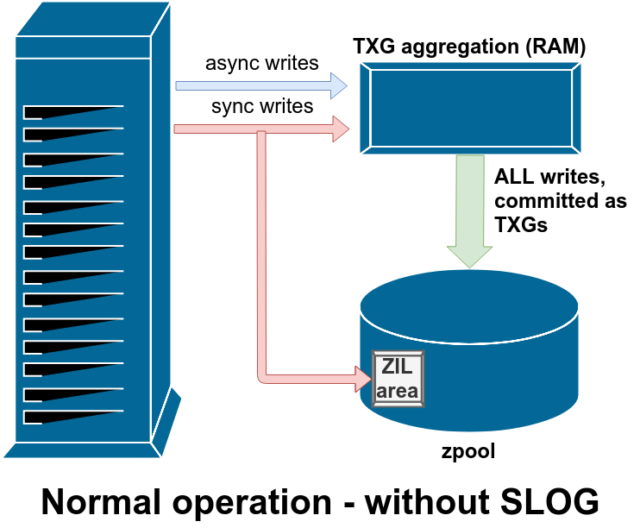


Hay dos categorías principales de operaciones de escritura-sincrónicas (sync) y asincrónicas (async). Para la mayoría de las cargas de trabajo, la gran mayoría de las operaciones de escritura son asíncronas: el sistema de archivos puede agregarlas y consignarlas en lotes, reduciendo la fragmentación y aumentando enormemente el rendimiento.
Las escrituras sincronizadas son un animal completamente diferente: cuando una aplicación solicita una escritura sincronizada, le está diciendo al sistema de archivos «tienes que consignar esto en el almacenamiento no volátil ahora, y hasta que no lo hagas, no puedo hacer nada más». Por lo tanto, las escrituras de sincronización deben comprometerse en el disco inmediatamente, y si eso aumenta la fragmentación o disminuye el rendimiento, que así sea.
ZFS maneja las escrituras de sincronización de forma diferente a los sistemas de archivos normales: en lugar de descargar las escrituras de sincronización en el almacenamiento normal inmediatamente, ZFS las compromete en un área de almacenamiento especial llamada ZFS Intent Log, o ZIL. El truco aquí es que esas escrituras también permanecen en la memoria, siendo agregadas junto con las solicitudes de escritura asíncronas normales, para luego ser descargadas al almacenamiento como TXGs (Grupos de Transacción) perfectamente normales.
En la operación normal, el ZIL se escribe y nunca se lee de nuevo. Cuando las escrituras guardadas en la ZIL se envían al almacenamiento principal desde la RAM en TXGs normales unos momentos después, se desvinculan de la ZIL. La única vez que se lee de la ZIL es cuando se importa el pool.
Si ZFS se cuelga -o el sistema operativo se cuelga, o hay un corte de energía no controlado- mientras hay datos en la ZIL, esos datos se leerán durante la siguiente importación del pool (por ejemplo, cuando se reinicie un sistema que se ha colgado). Lo que sea que esté en el ZIL se leerá, se agregará en TXGs, se comprometerá al almacenamiento principal, y luego se desvinculará del ZIL durante el proceso de importación.
Una de las clases de soporte vdev disponible es LOG-también conocido como SLOG, o dispositivo de registro secundario. Todo lo que hace el SLOG es proporcionar al grupo un vdev separado -y esperemos que mucho más rápido, con una resistencia de escritura muy alta- para almacenar el ZIL, en lugar de mantener el ZIL en el almacenamiento principal vdevs. En todos los aspectos, el ZIL se comporta igual si está en el almacenamiento principal, o en un LOG vdev-pero si el LOG vdev tiene un rendimiento de escritura muy alto, entonces los retornos de escritura de sincronización ocurrirán muy rápidamente.
Añadir un vdev LOG a un pool no puede en absoluto y no mejorará directamente el rendimiento de escritura asíncrona-incluso si usted fuerza todas las escrituras en el ZIL usando zfs set sync=always, todavía se comprometen con el almacenamiento principal en TXGs de la misma manera y al mismo ritmo que tendrían sin el LOG. Las únicas mejoras directas de rendimiento son para la latencia de escritura sincrónica (ya que la mayor velocidad del LOG permite que la llamada sync regrese más rápido).
Sin embargo, en un entorno que ya requiere muchas escrituras sincronizadas, un vdev LOG puede acelerar indirectamente las escrituras asincrónicas y las lecturas sin caché también. Descargar las escrituras ZIL a un vdev LOG separado significa menos contención por IOPS en el almacenamiento primario, aumentando así el rendimiento de todas las lecturas y escrituras hasta cierto punto.
Snapshots
La semántica de copia en escritura es también la base necesaria para las instantáneas atómicas de ZFS y la replicación asíncrona incremental. El sistema de archivos en vivo tiene un árbol de punteros que marca todos los records que contienen datos actuales -cuando se toma una instantánea, simplemente se hace una copia de ese árbol de punteros.
Cuando se sobrescribe un registro en el sistema de archivos en vivo, ZFS escribe primero la nueva versión del block en el espacio no utilizado. Luego desvincula la versión antigua del block del sistema de archivos actual. Pero si algún snapshot hace referencia al antiguo block, éste sigue siendo inmutable. El antiguo block no será recuperado como espacio libre hasta que todos los snapshots que hacen referencia a ese block hayan sido destruidos!
Replicación

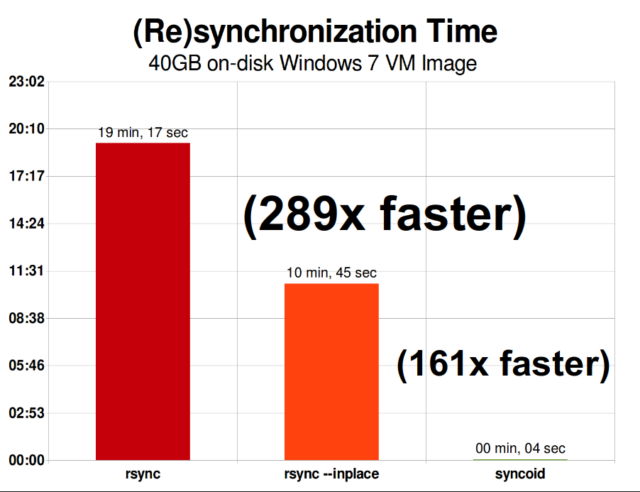
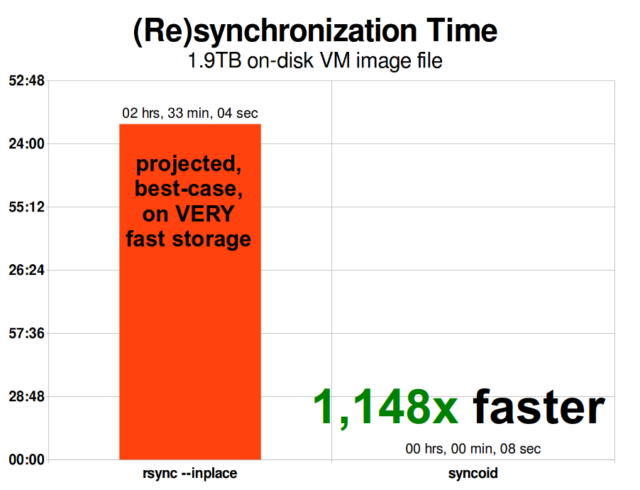 Una vez que entiendas cómo funcionan las instantáneas, estarás en un buen lugar para entender la replicación. Dado que una instantánea es simplemente un árbol de punteros a
Una vez que entiendas cómo funcionan las instantáneas, estarás en un buen lugar para entender la replicación. Dado que una instantánea es simplemente un árbol de punteros arecords, se deduce que si
zfs senduna instantánea, estamos enviando tanto ese árbol como todos los registros asociados. Cuando canalizamos esezfs senda unzfs receiveen el destino, se escribe tanto el contenido real deblock, como el árbol de punteros que hacen referencia alblocks, en el conjunto de datos de destino.
Las cosas se ponen más interesantes en tu segundo zfs send. Ahora que tienes dos sistemas, cada uno con la instantánea poolname/datasetname@1, puedes tomar una nueva instantánea, poolname/datasetname@2. Así que en el pool de origen, tienes datasetname@1 y datasetname@2, y en el pool de destino, hasta ahora sólo tienes la primera instantánea-datasetname@1.
Como tenemos una instantánea común entre el origen y el destino-datasetname@1– podemos construir una zfs send incremental encima de ella. Cuando pedimos al sistema que zfs send -i poolname/datasetname@1 poolname/datasetname@2 compare los dos árboles de punteros. Cualquier puntero que exista sólo en @2 obviamente hace referencia al nuevo blocks-así que necesitaremos el contenido de esos blocks también.
En el sistema remoto, canalizar el send incremental resultante es igualmente fácil. En primer lugar, escribimos todos los nuevos records incluidos en el flujo de send, luego añadimos los punteros a esos blocks. Presto, ¡tenemos @2 en el nuevo sistema!
La replicación incremental asíncrona de ZFS es una enorme mejora sobre las técnicas anteriores, no basadas en instantáneas, como rsync. En ambos casos, sólo es necesario enviar los datos modificados a través del cable, pero rsync debe leer primero todos los datos del disco, en ambos lados, para hacer la suma de comprobación y compararlos. Por el contrario, la replicación de ZFS no necesita leer nada más que los árboles de punteros y cualquier blocks que contenga ese árbol de punteros que no estuviera ya presente en la instantánea común.
Compresión en línea
La semántica de copia en escritura también facilita la oferta de compresión en línea. Con un sistema de archivos tradicional que ofrezca modificaciones en el lugar, la compresión es problemática: tanto la versión antigua como la nueva de los datos modificados deben caber exactamente en el mismo espacio.
Si consideramos un trozo de datos en medio de un archivo que comienza su vida como 1MiB de ceros-0x00000000 ad nauseam-se comprimiría hasta un solo sector de disco muy fácilmente. Pero ¿qué ocurre si sustituimos esos 1MiB de ceros por 1MiB de datos incompresibles, como JPEG o ruido pseudoaleatorio? De repente, ese 1MiB de datos necesita 256 sectores de 4KiB, no sólo uno, y el agujero en medio del archivo sólo tiene un sector de ancho.
ZFS no tiene este problema, ya que los registros modificados siempre se escriben en el espacio no utilizado-el block original sólo ocupa un único 4KiB sector, y el nuevo registro ocupa 256 de ellos, pero eso no es un problema-el trozo recién modificado del «medio» del archivo se habría escrito en el espacio no utilizado tanto si su tamaño hubiera cambiado como si no, así que para ZFS, este «problema» es sólo otro día en la oficina.
La compresión en línea de ZFS está desactivada por defecto, y ofrece algoritmos enchufables, que actualmente incluyen LZ4, gzip (1-9), LZJB y ZLE.
- LZ4 es un algoritmo de flujo que ofrece una compresión y descompresión extremadamente rápidas, y es una victoria de rendimiento para la mayoría de los casos de uso, incluso con CPUs muy anémicas.
- GZIP es el venerable algoritmo que todos los usuarios de Unix conocen y aman. Puede implementarse con niveles de compresión del 1 al 9, con un ratio de compresión y un uso de la CPU crecientes a medida que los niveles se acercan al 9. Gzip puede ser una victoria para los casos de uso de todo el texto (o de otra manera extremadamente comprimible), pero con frecuencia resulta en cuellos de botella de la CPU de otra manera – utilizar con precaución, especialmente en los niveles más altos.
- LZJB es el algoritmo original utilizado por ZFS. Está obsoleto y ya no debería usarse: LZ4 es superior en todas las métricas.
- ZLE es Zero Level Encoding (codificación de nivel cero): deja los datos normales por completo, pero comprime grandes secuencias de ceros. Es útil para conjuntos de datos totalmente incompresibles (por ejemplo, JPEG, MP4 u otros formatos ya comprimidos), ya que ignora los datos incompresibles, pero comprime el espacio libre en los registros finales.
Recomendamos la compresión LZ4 para casi cualquier caso de uso concebible; la penalización de rendimiento cuando se encuentra con datos incompresibles es muy pequeña, y la ganancia de rendimiento para los datos típicos es significativa. Copiar una imagen de VM para una nueva instalación del sistema operativo Windows (sólo el sistema operativo Windows instalado, sin datos en él todavía) fue un 27% más rápido con compression=lz4 que con compression=none en esta prueba de 2015.
ARC-la Caché de Reemplazo Adaptativa
ZFS es el único sistema de archivos moderno que conocemos que utiliza su propio mecanismo de caché de lectura, en lugar de depender de la caché de páginas de su sistema operativo para mantener copias de los bloques leídos recientemente en la RAM para ello.
Aunque el mecanismo de caché separado tiene sus problemas -el ZFS no puede reaccionar a las nuevas peticiones de asignación de memoria tan inmediatamente como el núcleo, y por lo tanto una nueva llamada mallocate() puede fallar, si necesita la RAM actualmente ocupada por el ARC- hay una buena razón, al menos por ahora, para soportarlo.
Todos los sistemas operativos modernos conocidos -incluyendo MacOS, Windows, Linux y BSD- utilizan el algoritmo LRU (Least Recently Used) para su implementación de la caché de páginas. LRU es un algoritmo ingenuo que hace subir un bloque de la caché a la «parte superior» de la cola cada vez que se lee, y desaloja los bloques de la «parte inferior» de la cola según sea necesario para añadir nuevos fallos de caché (bloques que tuvieron que ser leídos desde el disco, en lugar de la caché) en la «parte superior.»
Esto está bien hasta donde llega, pero en sistemas con grandes conjuntos de datos de trabajo, el LRU puede terminar fácilmente «thrashing» -desalojando bloques que se necesitan con mucha frecuencia, para hacer espacio a bloques que nunca serán leídos de la caché de nuevo.
El ARC es un algoritmo mucho menos ingenuo, que puede ser pensado como una caché «ponderada». Cada vez que se lee un bloque de la caché, se vuelve un poco más «pesado» y más difícil de desalojar, e incluso después de un desalojo, el bloque desalojado es rastreado durante un período de tiempo. Un bloque que ha sido desalojado pero que luego debe ser leído de nuevo en la caché también se volverá más «pesado» y más difícil de desalojar.
El resultado final de todo esto es una caché con ratios de aciertos típicamente mucho mayores -la proporción entre aciertos de caché (lecturas servidas desde la caché) y fallos de caché (lecturas servidas desde el disco). Esta es una estadística extremadamente importante: no sólo los aciertos de la caché se sirven órdenes de magnitud más rápidamente, sino que los fallos de la caché también pueden servirse más rápidamente, ya que más aciertos de la caché==menos peticiones concurrentes al disco==menor latencia para los fallos restantes que deben servirse desde el disco.
Conclusión
Ahora que hemos cubierto la semántica básica de ZFS -cómo funciona el copy-on-write, y las relaciones entre pools, vdevs, bloques, sectores y archivos- estamos listos para hablar del rendimiento real, con números reales.
Estad atentos a la próxima entrega de nuestra serie de fundamentos de almacenamiento para ver el rendimiento real visto en los pools que utilizan vdevs en espejo y RAIDz, comparados entre sí y con las topologías RAID tradicionales del núcleo de Linux que hemos explorado antes.
Al principio, sólo vamos a cubrir lo básico-las topologías ZFS en sí mismas-pero después de eso, estaremos listos para hablar sobre la configuración y ajuste más avanzado de ZFS, incluyendo el uso de tipos de vdev de apoyo como L2ARC, SLOG y Special Allocation.