
Serhii Maksymenko,
Architecte de solution en sciences des données
La technologie de reconnaissance des visages apparaît sous un jour différent aujourd’hui. Les cas d’utilisation comprennent une large application allant de la détection des crimes à l’identification des maladies génétiques.
Alors que les gouvernements du monde entier ont investi dans des systèmes de reconnaissance faciale, certaines villes américaines comme Oakland, Somerville et Portland, l’ont interdit en raison de préoccupations liées aux droits civils et à la vie privée.
Qu’en est-il – une bombe à retardement ou une percée technologique ? Cet article ouvre ce qu’est la reconnaissance des visages d’un point de vue technologique, et comment l’apprentissage profond augmente ses capacités. Ce n’est qu’en réalisant comment la technologie de reconnaissance des visages fonctionne de l’intérieur qu’il est possible de comprendre ce dont elle est capable.
Mise à jour le 06/09/2020 : Détection et reconnaissance des visages masqués
Comment l’apprentissage profond peut moderniser les logiciels de reconnaissance des visages
Télécharger le PDF
- Comment fonctionne la reconnaissance faciale?
- Comment l’apprentissage profond améliore les logiciels de reconnaissance de visage
- Comment nous avons mis en œuvre l’application de reconnaissance de visage alimentée par l’apprentissage profond
- Autres cas d’utilisation de la reconnaissance basée sur l’apprentissage profond
Comment fonctionne la reconnaissance faciale?
L’algorithme informatique du logiciel de reconnaissance faciale est un peu comme la reconnaissance visuelle humaine. Mais si les gens stockent des données visuelles dans un cerveau et les rappellent automatiquement une fois qu’ils en ont besoin, les ordinateurs devraient demander des données à une base de données et les faire correspondre pour identifier un visage humain.
En bref, un système informatisé équipé d’une caméra, détecte et identifie un visage humain, extrait les caractéristiques faciales comme la distance entre les yeux, une longueur de nez, une forme de front et de pommettes. Ensuite, le système reconnaît le visage et le fait correspondre à des images stockées dans une base de données.
Pour autant, une technologie traditionnelle de reconnaissance faciale n’est pas encore toute parfaite. Elle présente à la fois des forces et des faiblesses :
| Forces
Identification biométrique sans contact Traitement des données jusqu’à une seconde Compatibilité avec la plupart des caméras Facilité d’intégration |
Faiblesses
Twins. et biais raciaux Problèmes de confidentialité des données Attaque de présentation (AP) Peu de précision dans de mauvaises conditions d’éclairage |
Réaliser les faiblesses des systèmes de reconnaissance faciale, les scientifiques des données sont allés plus loin. En appliquant des techniques traditionnelles de vision par ordinateur et des algorithmes d’apprentissage profond, ils ont affiné le système de reconnaissance des visages pour prévenir les attaques et améliorer la précision. C’est ainsi que fonctionne une technologie anti-spoofing de visage.
Comment l’apprentissage profond améliore les logiciels de reconnaissance de visage
L’apprentissage profond est l’une des façons les plus originales d’améliorer la technologie de reconnaissance de visage. L’idée est d’extraire des embeddings de visage à partir d’images comportant des visages. Ces incorporations faciales seront uniques pour différents visages. Et l’entraînement d’un réseau neuronal profond est la façon la plus optimale d’effectuer cette tâche.
Dépendant d’une tâche et des délais, il existe deux méthodes courantes pour utiliser l’apprentissage profond pour les systèmes de reconnaissance des visages :
Utiliser des modèles pré-entraînés tels que dlib, DeepFace, FaceNet, et d’autres. Cette méthode prend moins de temps et d’efforts parce que les modèles pré-entraînés ont déjà un ensemble d’algorithmes à des fins de reconnaissance des visages. Nous pouvons également affiner les modèles pré-entraînés pour éviter les biais et laisser le système de reconnaissance des visages fonctionner correctement.
Développer un réseau neuronal à partir de zéro. Cette méthode est adaptée aux systèmes complexes de reconnaissance des visages ayant des fonctionnalités polyvalentes. Elle demande plus de temps et d’efforts, et nécessite des millions d’images dans le jeu de données d’entraînement, contrairement à un modèle pré-entraîné qui ne nécessite que des milliers d’images dans le cas de l’apprentissage par transfert.

Mais si le système de reconnaissance faciale comprend des caractéristiques uniques, cela peut être un moyen optimal à long terme. Les points clés auxquels il faut prêter attention sont :
- La sélection correcte de l’architecture CNN et de la fonction de perte
- L’optimisation du temps d’inférence
- La puissance d’un matériel
Il est recommandé d’utiliser des réseaux de neurones convolutifs (CNN) lors du développement d’une architecture de réseau, car ils ont prouvé leur efficacité dans les tâches de reconnaissance et de classification d’images. Afin d’obtenir les résultats escomptés, il est préférable d’utiliser une architecture de réseau neuronal généralement acceptée comme base, par exemple, ResNet ou EfficientNet.
Lors de la formation d’un réseau neuronal à des fins de développement de logiciels de reconnaissance des visages, nous devons minimiser les erreurs dans la plupart des cas. Il est ici crucial de considérer les fonctions de perte utilisées pour le calcul de l’erreur entre la sortie réelle et la sortie prédite. Les fonctions les plus couramment utilisées dans les systèmes de reconnaissance faciale sont la perte triplet et AM-Softmax.
- La fonction de perte triplet implique d’avoir trois images de deux personnes différentes. Il y a deux images – ancre et positive – pour une personne, et la troisième – négative – pour une autre personne. Les paramètres du réseau sont appris de manière à rapprocher les mêmes personnes dans l’espace des caractéristiques, et à séparer des personnes différentes.
- La fonction AM-Softmax est l’une des modifications les plus récentes de la fonction softmax standard, qui utilise une régularisation particulière basée sur une marge additive. Elle permet d’obtenir une meilleure séparabilité des classes et donc d’améliorer la précision des systèmes de reconnaissance faciale.
Il existe également plusieurs approches pour améliorer un réseau neuronal. Dans les systèmes de reconnaissance faciale, les plus intéressantes sont la distillation des connaissances, l’apprentissage par transfert, la quantification et les convolutions séparables en profondeur.
- La distillation des connaissances implique deux réseaux de taille différente lorsqu’un grand réseau enseigne sa propre variation plus petite. La valeur clé est qu’après l’apprentissage, le plus petit réseau fonctionne plus rapidement que le grand, en donnant le même résultat.
- L’approche de l’apprentissage par transfert permet d’améliorer la précision en entraînant le réseau entier ou seulement certaines couches sur un ensemble de données spécifique. Par exemple, si le système de reconnaissance des visages a des problèmes de biais raciaux, nous pouvons prendre un ensemble particulier d’images, disons des photos de Chinois, et former le réseau de manière à atteindre une plus grande précision.
- L’approche de quantification améliore un réseau neuronal pour atteindre une plus grande vitesse de traitement. En approximant un réseau neuronal qui utilise des nombres à virgule flottante par un réseau neuronal de nombres à faible largeur de bit, nous pouvons réduire la taille de la mémoire et le nombre de calculs.
- Les convolutions séparables en profondeur sont une classe de couches, qui permettent de construire des CNN avec un ensemble de paramètres beaucoup plus petit par rapport aux CNN standard. Tout en ayant un petit nombre de calculs, cette caractéristique peut améliorer le système de reconnaissance faciale de manière à le rendre adapté aux applications de vision mobile.
L’élément clé des technologies d’apprentissage profond est la demande de matériel de haute puissance. Lorsque l’on utilise des réseaux neuronaux profonds pour le développement de logiciels de reconnaissance faciale, l’objectif est non seulement d’améliorer la précision de la reconnaissance, mais aussi de réduire le temps de réponse. C’est pourquoi le GPU, par exemple, est plus adapté aux systèmes de reconnaissance de visage alimentés par l’apprentissage profond, que le CPU.
Comment nous avons mis en œuvre l’application de reconnaissance de visage alimentée par l’apprentissage profond
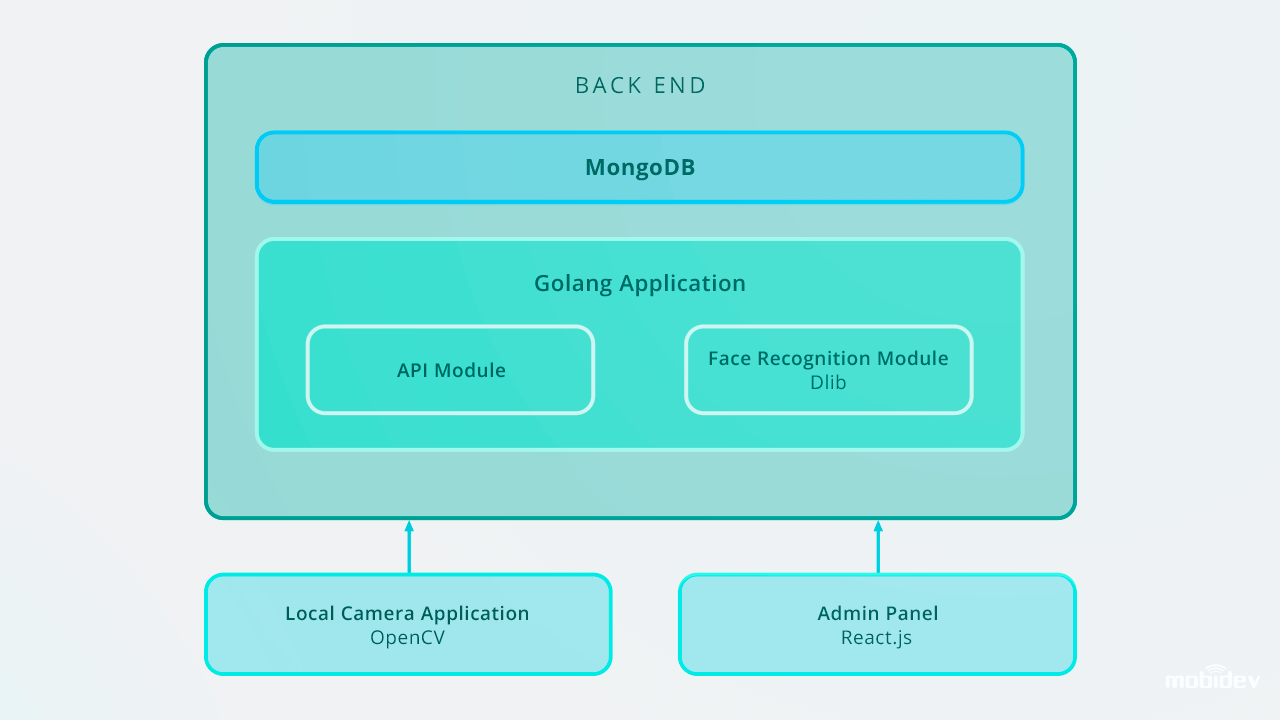
Lorsque nous avons développé le Big Brother (une application de caméra de démonstration) à MobiDev, nous avions pour objectif de créer un logiciel de vérification biométrique avec un flux vidéo en temps réel. Étant une app de console locale pour Ubuntu et Raspbian, Big Brother est écrit en Golang, et configuré avec l’ID de la caméra locale et le type de lecteur de caméra via le fichier de configuration JSON. Cette vidéo décrit comment Big Brother fonctionne en pratique :
De l’intérieur, le cycle de travail de l’app Big Brother comprend :
1. Détection des visages
L’appli détecte les visages dans un flux vidéo. Une fois le visage capturé, l’image est recadrée et envoyée au back-end via une requête de données de formulaire HTTP. L’API back-end enregistre l’image dans un système de fichiers local et enregistre un enregistrement dans le journal de détection avec un personID.
Le back-end utilise Golang et MongoDB Collections pour stocker les données des employés. Toutes les demandes d’API sont basées sur l’API RESTful.

2. Reconnaissance instantanée des visages
Le back-end a un travailleur de fond qui trouve de nouveaux enregistrements non classés et utilise Dlib pour calculer le vecteur descripteur à 128 dimensions des caractéristiques du visage. Chaque fois qu’un vecteur est calculé, il est comparé à plusieurs images de visage de référence en calculant la distance euclidienne à chaque vecteur de caractéristiques de chaque Personne dans la base de données, en trouvant une correspondance.
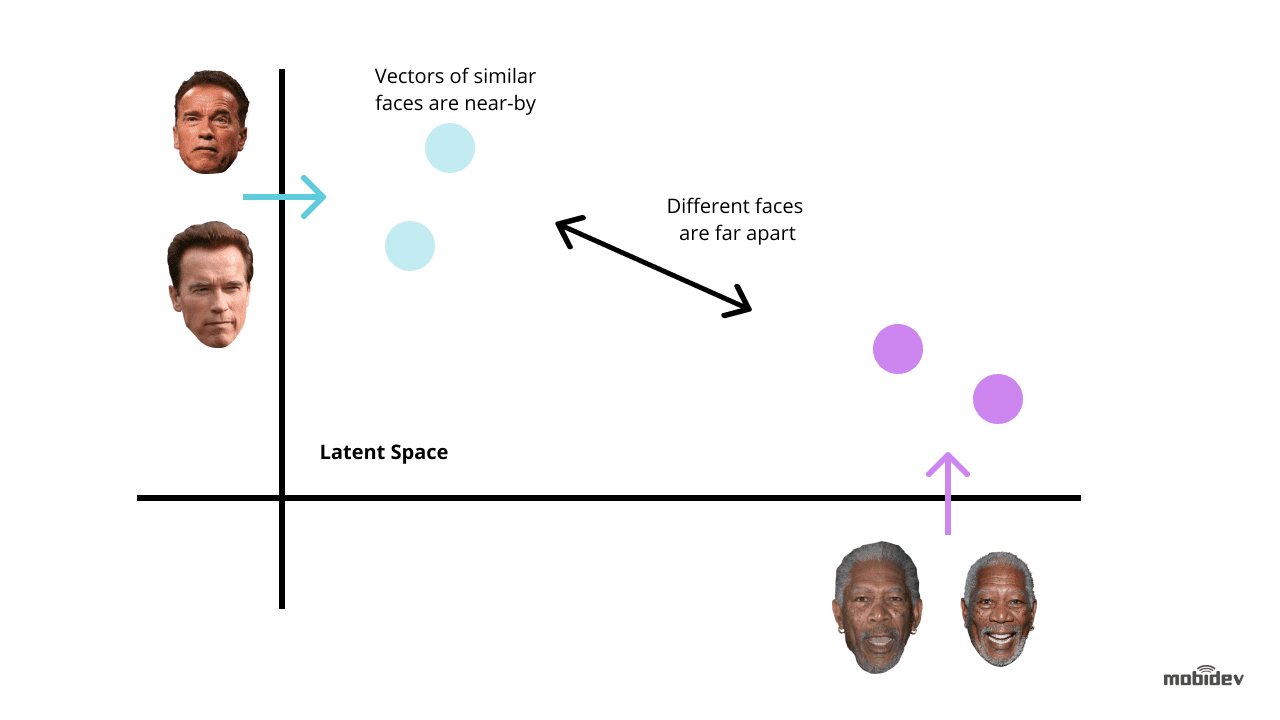
Si la distance euclidienne à la personne détectée est inférieure à 0,6, le travailleur définit un personID au journal de détection et le marque comme classé. Si la distance dépasse 0,6, il crée un nouvel ID de personne au journal.
3. Actions de suivi : alerte, accorder l’accès et autres
Les images d’une personne non identifiée sont envoyées au gestionnaire correspondant avec des notifications via des chatbots dans les messagers. Dans l’application Big Brother, nous avons utilisé Microsoft Bot Framework et Errbot basé sur Python, ce qui nous a permis de mettre en œuvre le chatbot d’alerte en cinq jours.

Par la suite, ces enregistrements peuvent être gérés via le panneau d’administration, qui stocke les photos avec les identifiants dans la base de données. Le logiciel de reconnaissance faciale fonctionne en temps réel et effectue les tâches de reconnaissance faciale instantanément. En utilisant Golang et MongoDB Collections pour le stockage des données des employés, nous avons saisi la base de données des IDs, comprenant 200 entrées.
Voici comment est conçue l’application de reconnaissance faciale Big Brother :
Dans le cas d’une mise à l’échelle à 10 000 entrées, nous recommanderions d’améliorer le système de reconnaissance faciale afin de conserver une vitesse de reconnaissance élevée sur le back-end. L’un des moyens optimaux est d’utiliser la parallélisation. En mettant en place un équilibreur de charge et en construisant plusieurs travailleurs web, nous pouvons assurer le bon travail d’une partie back-end et la vitesse optimale d’un système entier.
Autres cas d’utilisation de la reconnaissance basée sur l’apprentissage profond
La reconnaissance des visages n’est pas la seule tâche pour laquelle le développement de logiciels basés sur l’apprentissage profond peut améliorer les performances. D’autres exemples incluent:
Détection et reconnaissance de visages masqués
Depuis que le COVID-19 a fait que les gens dans de nombreux pays portent des masques faciaux, la technologie de reconnaissance faciale est devenue plus avancée. En utilisant l’algorithme d’apprentissage profond basé sur les réseaux neuronaux convolutifs, les caméras peuvent désormais reconnaître les visages couverts de masques. Les ingénieurs en science des données utilisent des algorithmes tels que les modèles de reconnaissance multi-granularité et périoculaire basés sur les yeux du visage pour améliorer les capacités du système de reconnaissance faciale. En identifiant des caractéristiques du visage telles que le front, le contour du visage, les détails oculaires et périoculaires, les sourcils, les yeux et les pommettes, ces modèles permettent de reconnaître les visages masqués avec une précision pouvant atteindre 95 %.
Un bon exemple d’un tel système est la technologie de reconnaissance des visages créée par l’une des entreprises chinoises. Le système se compose de deux algorithmes : la reconnaissance des visages basée sur l’apprentissage profond, et la mesure de la température par imagerie thermique infrarouge. Lorsque des personnes portant un masque facial se tiennent devant la caméra, le système extrait les caractéristiques du visage et les compare aux images existantes dans la base de données. Dans le même temps, le mécanisme de mesure de la température par infrarouge mesure la température, détectant ainsi les personnes présentant des températures anormales.
Détection des défauts
Au cours des deux dernières années, les fabricants ont utilisé l’inspection visuelle basée sur l’IA pour la détection des défauts. Le développement d’algorithmes d’apprentissage profond permet à ce système de définir automatiquement les plus petites rayures et fissures, en évitant les facteurs humains.
Détection d’anomalies corporelles
L’entreprise israélienne Aidoc a développé une solution alimentée par l’apprentissage profond pour la radiologie. En analysant les images médicales, ce système détecte les anomalies dans un thorax, une colonne vertébrale, une tête et un abdomen.
Identification des locuteurs
La technologie d’identification des locuteurs créée par la société Phonexia identifie également les locuteurs en utilisant l’approche d’apprentissage métrique. Le système reconnaît les locuteurs par la voix, en produisant des modèles mathématiques de la parole humaine appelés empreintes vocales. Ces empreintes vocales sont stockées dans des bases de données, et lorsqu’une personne parle, la technologie du locuteur identifie l’empreinte vocale unique.
La reconnaissance des émotions
La reconnaissance des émotions humaines est une tâche réalisable aujourd’hui. En suivant les mouvements d’un visage via une caméra, la technologie de reconnaissance des émotions catégorise les émotions humaines. L’algorithme d’apprentissage profond identifie les points de repère d’un visage humain, détecte une expression faciale neutre et mesure les déviations des expressions faciales reconnaissant des expressions plus positives ou négatives.
Reconnaissance des actions
Visual Une entreprise, qui est un fournisseur de Nest Cams, a alimenté son produit avec l’IA. En utilisant des techniques d’apprentissage profond, ils ont affiné les Nest Cams pour reconnaître non seulement différents objets comme les personnes, les animaux domestiques, les voitures, etc, mais aussi identifier les actions. L’ensemble des actions à reconnaître est personnalisable et sélectionné par l’utilisateur. Par exemple, une caméra peut reconnaître un chat qui gratte la porte, ou un enfant qui joue avec la cuisinière.
Si l’on résume, les réseaux neuronaux profonds sont un outil puissant pour l’humanité. Et seul un humain décide de l’avenir technologique à venir.
Comment l’apprentissage profond peut moderniser les logiciels de reconnaissance faciale
Télécharger le PDF
.