
Alors que nous entrons tous dans le troisième mois de la pandémie COVID-19 et que nous cherchons de nouveaux projets pour nous maintenir engagés (lire : sains d’esprit), pouvons-nous vous intéresser à l’apprentissage des principes fondamentaux du stockage informatique ? Discrètement ce printemps, nous avons déjà abordé certaines bases nécessaires, comme la façon de tester la vitesse de vos disques et ce qu’est le RAID. Dans la deuxième de ces histoires, nous avons même promis un suivi explorant les performances de diverses topologies à disques multiples dans ZFS, le système de fichiers de nouvelle génération dont vous avez entendu parler en raison de ses apparitions partout, d’Apple à Ubuntu.
Eh bien, c’est aujourd’hui le jour d’explorer, lecteurs curieux de ZFS. Sachez simplement d’emblée que, selon les mots discrets du développeur d’OpenZFS Matt Ahrens, « c’est vraiment compliqué. »
Mais avant d’en venir aux chiffres – et ils arrivent, promis !-pour toutes les façons dont vous pouvez façonner huit disques de ZFS, nous devons parler de la façon dont ZFS stocke vos données sur le disque en premier lieu.
Zpools, vdevs, et périphériques
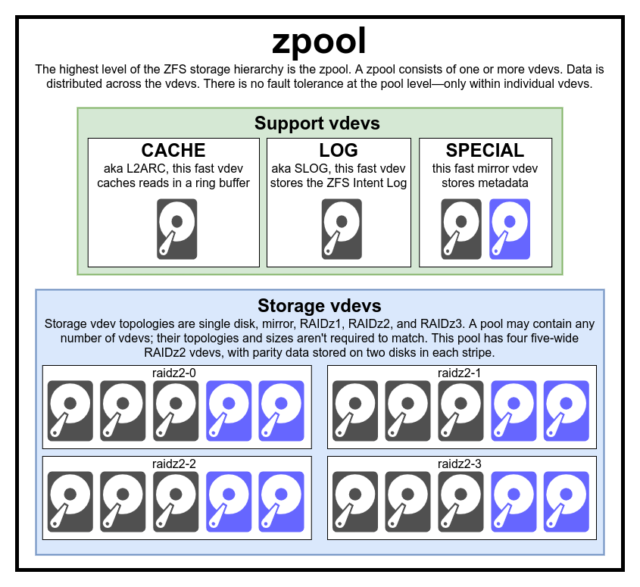

Pour vraiment comprendre ZFS, vous devez accorder une réelle attention à sa structure réelle. ZFS fusionne les couches traditionnelles de gestion de volume et de système de fichiers, et il utilise un mécanisme transactionnel de copie sur écriture – ces deux éléments signifient que le système est structurellement très différent des systèmes de fichiers et des matrices RAID classiques. Le premier ensemble de blocs de construction majeurs à comprendre sont zpools, vdevs, et devices.
zpool
Le zpool est la structure ZFS la plus élevée. Un zpool contient un ou plusieurs vdevs, chacun d’entre eux contenant à son tour un ou plusieurs devices. Les zpools sont des unités autonomes – un ordinateur physique peut avoir deux ou plusieurs zpools séparés sur lui, mais chacun est entièrement indépendant des autres. Les zpools ne peuvent pas partager vdevs les uns avec les autres.
La redondance ZFS se situe au niveau vdev, et non au niveau zpool. Il n’y a absolument aucune redondance au niveau du zpool – si un vdev de stockage vdev ou SPECIAL est perdu, l’ensemble du zpool est perdu avec lui.
Les zpools modernes peuvent survivre à la perte d’un vdev CACHE ou LOG – bien qu’ils puissent perdre une petite quantité de données sales, s’ils perdent un vdev LOG lors d’une panne de courant ou d’un crash système.
C’est une idée fausse commune que ZFS « stripe » les écritures à travers le pool – mais c’est inexact. Un zpool n’est pas un RAID0 à l’apparence amusante-c’est un JBOD à l’apparence amusante, avec un mécanisme de distribution complexe sujet à changement.
Pour la plupart, les écritures sont distribuées sur les vdev disponibles en fonction de leur espace libre disponible, de sorte que tous les vdev deviendront théoriquement pleins en même temps. Dans les versions plus récentes de ZFS, l’utilisation des vdev peut également être prise en compte-si un vdev est significativement plus occupé qu’un autre (ex : en raison de la charge de lecture), il peut être ignoré temporairement pour l’écriture malgré le plus grand ratio d’espace libre disponible.
Le mécanisme de prise en compte de l’utilisation intégré dans les méthodes modernes de distribution d’écriture de ZFS peut diminuer la latence et augmenter le débit pendant les périodes de charge exceptionnellement élevée-mais il ne doit pas être confondu avec une carte blanche pour mélanger bon gré mal gré des disques rust lents et des SSD rapides dans le même pool. Un tel pool mal assorti sera toujours généralement performant comme s’il était entièrement composé du périphérique le plus lent présent.
vdev
Chaque zpool consiste en un ou plusieurs vdevs(abréviation de périphérique virtuel). Chaque vdev, à son tour, est constitué d’un ou plusieurs devices réels. La plupart des vdev sont utilisés pour le stockage ordinaire, mais plusieurs classes de support spécial de vdev existent également, notamment CACHE, LOG et SPECIAL. Chacun de ces types de vdev peut offrir l’une des cinq topologies suivantes : dispositif unique, RAIDz1, RAIDz2, RAIDz3 ou miroir.
RAIDz1, RAIDz2 et RAIDz3 sont des variétés spéciales de ce que les amateurs de stockage appellent « RAID à parité diagonale ». Les 1, 2 et 3 font référence au nombre de blocs de parité alloués à chaque bande de données. Plutôt que d’avoir des disques entiers dédiés à la parité, les vdev RAIDz distribuent cette parité de manière semi-égale sur les disques. Un réseau RAIDz peut perdre autant de disques qu’il a de blocs de parité ; s’il en perd un autre, il échoue et entraîne le zpool dans sa chute.
Les vdev en miroir sont précisément ce à quoi ils ressemblent – dans un vdev en miroir, chaque bloc est stocké sur chaque périphérique du vdev. Bien que les miroirs à deux largeurs soient les plus courants, un vdev miroir peut contenir n’importe quel nombre arbitraire de périphériques – les trois voies sont courantes dans les grandes configurations pour les performances de lecture et la résistance aux pannes plus élevées. Un vdev miroir peut survivre à n’importe quelle défaillance, tant qu’au moins un périphérique dans le vdev reste sain.
Les vdev à un seul périphérique sont aussi exactement ce qu’ils ressemblent – et ils sont intrinsèquement dangereux. Un vdev à un seul dispositif ne peut survivre à aucune défaillance – et s’il est utilisé comme un stockage ou un vdev SPECIAL, sa défaillance entraînera l’ensemble du zpool vers le bas. Soyez très, très prudent ici.
CACHE, LOG, et SPECIAL vdevs peuvent être créés en utilisant n’importe laquelle des topologies ci-dessus-mais rappelez-vous, la perte d’un SPECIAL vdev signifie la perte du pool, donc une topologie redondante est fortement encouragée.
device
C’est probablement le terme lié à ZFS le plus facile à comprendre – c’est littéralement juste un périphérique de bloc à accès aléatoire. Rappelez-vous, les vdevs sont constitués de périphériques individuels, et le zpool est constitué de vdevs.
Les disques – qu’ils soient rouillés ou solides – sont les périphériques de bloc les plus courants utilisés comme blocs de construction vdev. Tout ce qui a un descripteur dans /dev qui permet un accès aléatoire fonctionnera, cependant – ainsi, des matrices RAID matérielles entières peuvent être (et sont parfois) utilisées comme des périphériques individuels.
Le simple fichier brut est l’un des périphériques de bloc alternatifs les plus importants à partir duquel un vdev peut être construit. Les pools de test faits de fichiers épars sont un moyen incroyablement pratique de pratiquer les commandes zpool, et de voir combien d’espace est disponible sur un pool ou un vdev d’une topologie donnée.

Disons que vous envisagez de construire un serveur à huit baies, et que vous êtes à peu près sûr de vouloir utiliser des disques de 10 To (~9300 GiB), mais que vous n’êtes pas sûr de la topologie la mieux adaptée à vos besoins. Dans l’exemple ci-dessus, nous construisons un pool de test à partir de fichiers épars en quelques secondes-et maintenant nous savons qu’un vdev RAIDz2 composé de huit disques de 10TB offre 50TiB de capacité utilisable.
Il existe une classe spéciale de devicela SPARE. Les périphériques Hotspare, contrairement aux périphériques normaux, appartiennent à l’ensemble du pool, pas à un seul vdev. Si un vdev du pool subit une panne de périphérique, et qu’un SPARE est attaché au pool et disponible, le SPARE s’attachera automatiquement au vdev dégradé.
Une fois attaché au vdev dégradé, le SPARE commence à recevoir des copies ou des reconstructions des données qui devraient se trouver sur le périphérique manquant. Dans un RAID traditionnel, cela s’appellerait » reconstruction » – dans ZFS, cela s’appelle » resilvering « .
Il est important de noter que les périphériques SPARE ne remplacent pas de façon permanente les périphériques défaillants. Ils sont juste des placeholders, destinés à minimiser la fenêtre pendant laquelle un vdev fonctionne de manière dégradée. Une fois que l’administrateur a remplacé le périphérique défaillant du vdev et que le nouveau périphérique de remplacement permanent se résilibre, le SPARE se détache du vdev et retourne au service de l’ensemble du pool.
Datasets, blocks, and sectors
Le prochain ensemble de blocs de construction que vous devrez comprendre dans votre voyage ZFS ne concerne pas tant le matériel, mais la façon dont les données elles-mêmes sont organisées et stockées. Nous sautons quelques niveaux ici – tels que le métaslab – dans l’intérêt de garder les choses aussi simples que possible, tout en comprenant la structure globale.
Datasets
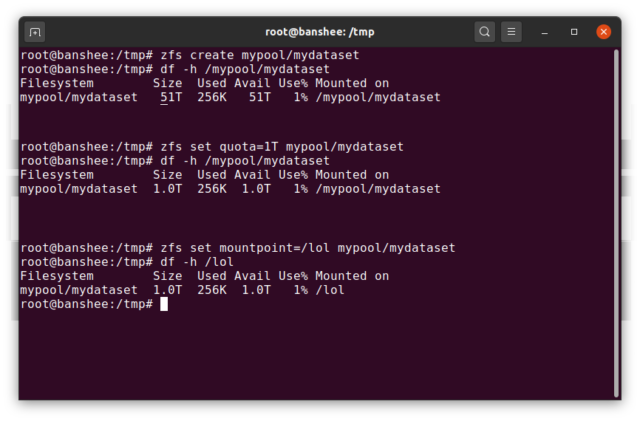

Un ZFS dataset est grossièrement analogue à un système de fichiers standard, monté – comme un système de fichiers conventionnel, il apparaît à l’inspection occasionnelle comme si c’était « juste un autre dossier ». Mais également comme les systèmes de fichiers montés conventionnels, chaque datasetZFS a son propre ensemble de propriétés sous-jacentes.
Premièrement et avant tout, un dataset peut avoir un quota qui lui est attribué. Si vous zfs set quota=100G poolname/datasetname, vous ne pourrez pas mettre plus de 100GiB de données dans le dossier /poolname/datasetname monté sur le système.
Vous avez remarqué la présence – et l’absence – de barres obliques dans l’exemple ci-dessus ? Chaque ensemble de données a sa place à la fois dans la hiérarchie ZFS et dans la hiérarchie de montage du système. Dans la hiérarchie ZFS, il n’y a pas de barre oblique de tête – vous commencez par le nom du pool, puis le chemin d’un ensemble de données au suivant – par exemple pool/parent/child pour un ensemble de données nommé child sous l’ensemble de données parent parent, dans un pool nommé de manière créative pool.
Par défaut, le point de montage d’un dataset sera équivalent à son nom hiérarchique ZFS, avec une barre oblique de tête-le pool nommé pool est monté à /pool, le jeu de données parent est monté à /pool/parent, et le jeu de données enfant child est monté à /pool/parent/child. Le point de montage système d’un ensemble de données peut cependant être modifié.
Si nous devions zfs set mountpoint=/lol pool/parent/child, l’ensemble de données pool/parent/child serait en fait monté sur le système en tant que /lol.
En plus des ensembles de données, il faut mentionner zvols. Un zvol est à peu près analogue à un dataset, sauf qu’il n’a pas réellement un système de fichiers en lui-c’est juste un périphérique de bloc. Vous pourriez, par exemple, créer un zvol nommé mypool/myzvol, puis le formater avec le système de fichiers ext4, puis monter ce système de fichiers – vous avez maintenant un système de fichiers ext4, mais soutenu par toutes les fonctionnalités de sécurité de ZFS ! Cela peut sembler idiot sur un seul ordinateur – mais cela a beaucoup plus de sens en tant que back end pour une exportation iSCSI.
Blocks
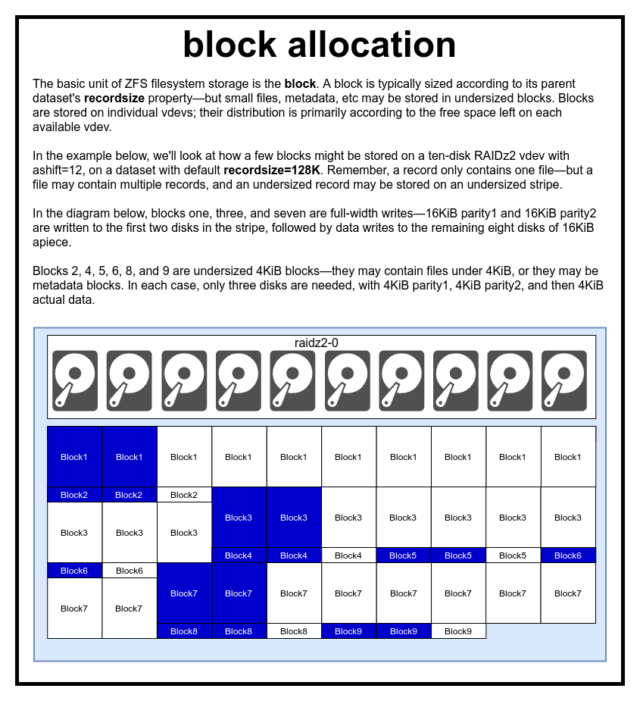

Dans un pool ZFS, toutes les données – y compris les métadonnées – sont stockées dans blocks. La taille maximale d’un block est définie pour chaque dataset dans la propriété recordsize. Recordsize est mutable, mais la modification de recordsize ne changera pas la taille ou la disposition des blocks qui ont déjà été écrites dans le jeu de données – seulement pour les nouveaux blocs au fur et à mesure qu’ils sont écrits.
Sauf définition contraire, la recordsizepar défaut actuelle est de 128KiB. Cela représente une sorte de compromis malaisé dans lequel les performances ne seront pas idéales pour beaucoup de choses, mais ne seront pas non plus affreuses pour beaucoup de choses. Recordsize peut être défini à n’importe quelle valeur de 4K à 1M. (Recordsize peut être défini encore plus grand avec un réglage supplémentaire et une détermination suffisante, mais c’est rarement une bonne idée.)
Tout block donné fait référence aux données d’un seul fichier – vous ne pouvez pas entasser deux fichiers distincts dans le même block. Chaque fichier sera composé d’un ou plusieurs blocks, en fonction de sa taille. Si un fichier est plus petit que recordsize, il sera stocké dans un bloc sous-dimensionné-par exemple, un block contenant un fichier de 2KiB n’occupera qu’un seul sector de 4KiB sur le disque.
Si un fichier est assez grand pour nécessiter plusieurs blocks, tous les enregistrements contenant ce fichier auront une longueur recordsize-y compris le dernier enregistrement, qui peut être principalement de l’espace libre.Les
Zvols n’ont pas la propriété recordsize – au lieu de cela, ils ont volblocksize, ce qui est à peu près équivalent.
Secteurs
Le dernier bloc de construction à discuter est le modeste sector. Un sector est la plus petite unité physique qui peut être écrite ou lue à partir de son device sous-jacent. Pendant plusieurs décennies, la plupart des disques utilisaient des sectors de 512 octets. Plus récemment, la plupart des disques utilisent des sectors de 4KiB, et certains – en particulier les SSD – utilisent des sectors de 8KiB, voire plus.
ZFS possède une propriété qui vous permet de définir manuellement la taille des sector, appelée ashift. De manière quelque peu déroutante, ashift est en fait l’exposant binaire qui représente la taille du secteur – par exemple, définir ashift=9 signifie que votre taille sector sera de 2^9, ou 512 octets.
ZFS interroge le système d’exploitation pour obtenir des détails sur chaque bloc device lorsqu’il est ajouté à un nouveau vdev, et en théorie, il définira automatiquement ashift correctement en fonction de ces informations. Malheureusement, il existe de nombreux disques qui mentent comme des arracheurs de dents sur la taille de leur sector, afin de rester compatible avec Windows XP (qui était incapable de comprendre les disques avec toute autre taille sector).
Ce qui signifie qu’il est fortement conseillé à un administrateur ZFS d’être conscient de la taille sector réelle de son devices, et de définir manuellement ashift en conséquence. Si ashift est défini trop bas, une pénalité astronomique d’amplification de lecture/écriture est encourue – écrire un « secteur » de 512 octets sur un sector réel de 4KiB signifie devoir écrire le premier « secteur », puis lire le sector de 4KiB, le modifier avec le deuxième « secteur » de 512 octets, le réécrire sur un sector de *nouveau* 4KiB, et ainsi de suite, pour chaque écriture unique.
En termes de monde réel, cette pénalité d’amplification frappe un SSD Samsung EVO – qui devrait avoir ashift=13, mais qui ment sur sa taille de secteur et donc par défaut ashift=9 s’il n’est pas surchargé par un administrateur avisé – assez durement pour le faire paraître plus lent qu’un disque rouillé conventionnel.
En revanche, il n’y a pratiquement aucune pénalité à définir ashift trop haut. Il n’y a pas de réelle pénalité de performance, et les augmentations d’espace mou sont infinitésimales (ou nulles, avec la compression activée). Nous recommandons fortement que même les disques qui utilisent vraiment des secteurs de 512 octets soient définis ashift=12 ou même ashift=13 pour une protection future.
La propriété ashift est par-vdev – et non par pool, comme on le pense couramment et à tort !- et est immuable, une fois définie. Si vous flouez accidentellement ashift lors de l’ajout d’un nouveau vdev à un pool, vous avez irrévocablement contaminé ce pool avec un vdev drastiquement sous-performant, et n’avez généralement pas d’autre recours que de détruire le pool et de recommencer. Même la suppression d’un vdev ne peut pas vous sauver d’un paramètre ashift foiré !
Sémantique de la copie sur l’écriture




CoW-Copie sur l’écriture- est un sous-jacent fondamental sous la plupart de ce qui rend ZFS génial. Le concept de base est simple : si vous demandez à un système de fichiers traditionnel de modifier un fichier sur place, il fait précisément ce que vous lui avez demandé. Si vous demandez à un système de fichiers de copie sur écriture de faire la même chose, il dit « ok »-mais il vous ment.
Au lieu de cela, le système de fichiers de copie sur écriture écrit une nouvelle version du block que vous avez modifié, puis met à jour les métadonnées du fichier pour délier l’ancien block, et lier le nouveau block que vous venez d’écrire.
Délier l’ancien block et lier le nouveau est accompli en une seule opération, de sorte qu’il ne peut pas être interrompu – si vous déchargez le pouvoir après qu’il se produit, vous avez la nouvelle version du fichier, et si vous déchargez le pouvoir avant, alors vous avez l’ancienne version. Vous êtes toujours cohérent avec le système de fichiers, de toute façon.
La copie sur écriture dans ZFS n’est pas seulement au niveau du système de fichiers, elle est aussi au niveau de la gestion du disque. Cela signifie que le trou RAID – une condition dans laquelle une bande n’est que partiellement écrite avant que le système ne se plante, rendant la matrice incohérente et corrompue après un redémarrage – n’affecte pas ZFS. Les écritures de bandes sont atomiques, le vdev est toujours cohérent, et Bob est votre oncle.
ZIL-the ZFS Intent Log
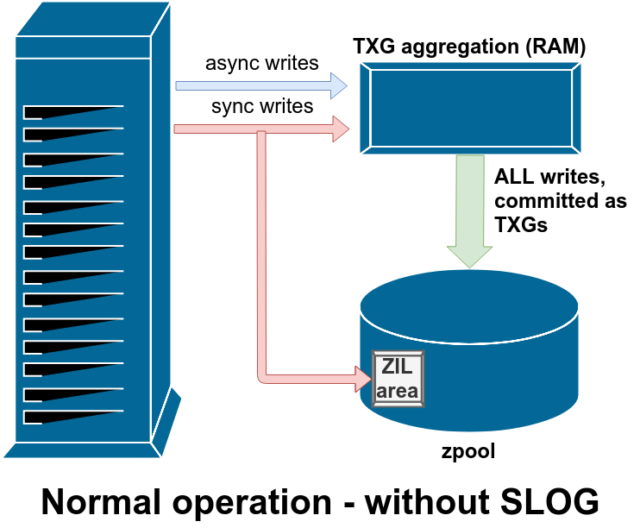

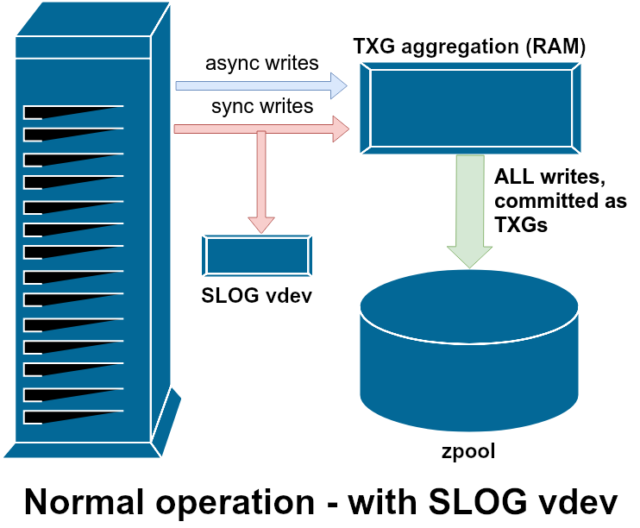

Il existe deux grandes catégories d’opérations d’écriture : synchrone (sync) et asynchrone (async). Pour la plupart des charges de travail, la grande majorité des opérations d’écriture sont asynchrones – le système de fichiers est autorisé à les agréger et à les commettre par lots, ce qui réduit la fragmentation et augmente énormément le débit.
Les écritures synchrones sont un animal entièrement différent – lorsqu’une application demande une écriture synchronisée, elle dit au système de fichiers « vous devez commettre ceci sur le stockage non volatile maintenant, et jusqu’à ce que vous le fassiez, je ne peux rien faire d’autre. » Les écritures de synchronisation doivent donc être engagées sur le disque immédiatement – et si cela augmente la fragmentation ou diminue le débit, qu’il en soit ainsi.
ZFS gère les écritures de synchronisation différemment des systèmes de fichiers normaux – au lieu de vider immédiatement les écritures de synchronisation sur le stockage normal, ZFS les engage dans une zone de stockage spéciale appelée ZFS Intent Log, ou ZIL. L’astuce ici est que ces écritures restent également en mémoire, étant agrégées avec les demandes d’écriture asynchrones normales, pour être plus tard évacuées vers le stockage comme des TXGs (groupes de transactions) parfaitement normaux.
En fonctionnement normal, le ZIL est écrit et n’est plus jamais lu. Lorsque les écritures sauvegardées dans la ZIL sont commises sur le stockage principal à partir de la RAM dans des TXGs normaux quelques instants plus tard, elles sont dissociées de la ZIL. La seule fois où la ZIL est lue est lors de l’importation du pool.
Si ZFS plante – ou le système d’exploitation plante, ou il y a une coupure de courant non gérée – alors qu’il y a des données dans la ZIL, ces données seront lues lors de la prochaine importation du pool (par exemple quand un système planté est redémarré). Tout ce qui se trouve dans la ZIL sera lu, agrégé en TXG, engagé sur le stockage principal, puis délié de la ZIL pendant le processus d’importation.
Une des classes de support vdev disponibles est LOG-également connue sous le nom de SLOG, ou dispositif de LOG secondaire. Tout ce que fait le SLOG, c’est de fournir au pool un vdevséparé-et, espérons-le, beaucoup plus rapide, avec une très grande endurance en écriture-pour stocker le ZIL, au lieu de garder le ZIL sur le stockage principal vdevs. À tous égards, le ZIL se comporte de la même manière qu’il soit sur le stockage principal, ou sur un LOG vdev – mais si le LOG vdev a des performances d’écriture très élevées, alors les retours d’écriture de synchronisation se feront très rapidement.
Ajouter un LOG vdev à un pool ne peut absolument pas et n’améliorera pas directement les performances d’écriture asynchrone – même si vous forcez toutes les écritures dans le ZIL en utilisant zfs set sync=always, elles sont toujours commises sur le stockage principal dans les TXG de la même manière et au même rythme qu’elles l’auraient fait sans le LOG. Les seules améliorations directes des performances concernent la latence des écritures synchrones (puisque la plus grande vitesse du LOG permet à l’appel sync de revenir plus rapidement).
Cependant, dans un environnement qui nécessite déjà beaucoup d’écritures synchrones, un vdev LOG peut indirectement accélérer les écritures asynchrones et les lectures non mises en cache également. Décharger les écritures ZIL sur un LOG vdev séparé signifie moins de contention pour les IOPS sur le stockage primaire, augmentant ainsi les performances pour toutes les lectures et écritures dans une certaine mesure.
Snapshots
La sémantique de copie sur écriture est également le fondement nécessaire pour les instantanés atomiques de ZFS et la réplication asynchrone incrémentielle. Le système de fichiers live possède un arbre de pointeurs marquant tous les records qui contiennent des données actuelles – lorsque vous prenez un instantané, vous faites simplement une copie de cet arbre de pointeurs.
Lorsqu’un enregistrement est écrasé dans le système de fichiers live, ZFS écrit d’abord la nouvelle version du block dans l’espace inutilisé. Ensuite, il dissocie l’ancienne version du block du système de fichiers courant. Mais si un snapshot fait référence à l’ancien block, il reste immuable. L’ancienne block ne sera pas réellement récupérée en tant qu’espace libre jusqu’à ce que toutes les snapshots référençant cette block aient été détruites!
Réplication

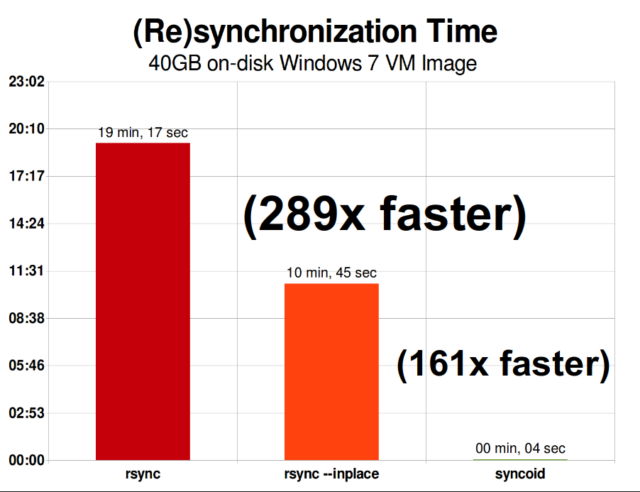
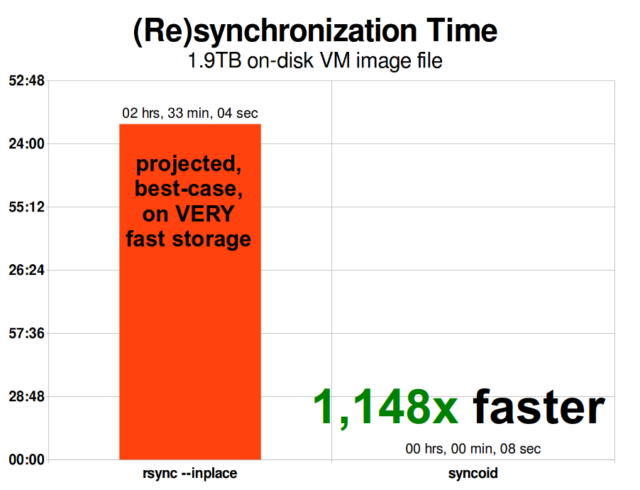 Une fois que vous avez compris comment les instantanés fonctionnent, vous êtes en bonne position pour comprendre la réplication. Puisqu’un snapshot est simplement un arbre de pointeurs vers
Une fois que vous avez compris comment les instantanés fonctionnent, vous êtes en bonne position pour comprendre la réplication. Puisqu’un snapshot est simplement un arbre de pointeurs versrecords, il s’ensuit que si nouszfs sendun snapshot, nous envoyons à la fois cet arbre et tous les enregistrements associés. Quand on pipe cezfs sendvers unzfs receivesur la cible, il écrit à la fois le contenu réel dublock, et l’arbre de pointeurs référençant leblocks, dans le jeu de données cible.
Les choses deviennent plus intéressantes sur votre deuxième zfs send. Maintenant que vous avez deux systèmes, chacun contenant l’instantané poolname/datasetname@1, vous pouvez prendre un nouvel instantané, poolname/datasetname@2. Donc, sur le pool source, vous avez datasetname@1 et datasetname@2, et sur le pool cible, jusqu’à présent, vous avez juste le premier instantané-datasetname@1.
Puisque nous avons un instantané commun entre la source et la destination-datasetname@1– nous pouvons construire un zfs send incrémental par dessus. Lorsque nous demandons au système de zfs send -i poolname/datasetname@1 poolname/datasetname@2, il compare les deux arbres de pointeurs. Tous les pointeurs qui n’existent que dans @2 font évidemment référence à la nouvelle blocks – nous aurons donc besoin du contenu de ces blocks également.
Sur le système distant, le piping dans la send incrémentale résultante est tout aussi facile. D’abord, nous écrivons tous les nouveaux records inclus dans le flux send, puis nous ajoutons les pointeurs vers ces blocks. Presto, nous avons @2 sur le nouveau système !
La réplication incrémentale asynchrone de ZFS est une énorme amélioration par rapport aux techniques antérieures, non basées sur les instantanés, comme rsync. Dans les deux cas, seules les données modifiées doivent être envoyées sur le fil – mais rsync doit d’abord lire toutes les données du disque, des deux côtés, afin de les additionner et de les comparer. En revanche, la réplication ZFS n’a pas besoin de lire quoi que ce soit d’autre que les arbres de pointeurs et tout blocksque l’arbre de pointeurs contient qui n’était pas déjà présent dans l’instantané commun.
Compression en ligne
La sémantique de copie sur écriture facilite également l’offre de compression en ligne. Avec un système de fichiers traditionnel offrant une modification en place, la compression est problématique – l’ancienne version et la nouvelle version des données modifiées doivent tenir exactement dans le même espace.
Si nous considérons un morceau de données au milieu d’un fichier qui commence sa vie comme 1MiB de zéros-0x00000000 ad nauseam- il se compresserait très facilement en un seul secteur de disque. Mais que se passe-t-il si nous remplaçons ces 1Mo de zéros par 1Mo de données incompressibles, comme du JPEG ou du bruit pseudo-aléatoire ? Soudain, ce 1MiB de données a besoin de 256 secteurs de 4KiB, et pas seulement d’un seul – et le trou au milieu du fichier n’est large que d’un secteur.
ZFS n’a pas ce problème, puisque les enregistrements modifiés sont toujours écrits dans l’espace inutilisé – le block original n’occupe qu’un seul 4KiB sector, et le nouvel enregistrement en occupe 256, mais ce n’est pas un problème – le morceau nouvellement modifié du « milieu » du fichier aurait été écrit dans l’espace inutilisé, que sa taille ait changé ou non, donc pour ZFS, ce « problème » est juste un autre jour au bureau.
La compression en ligne de ZFS est désactivée par défaut, et elle offre des algorithmes enfichables – incluant actuellement LZ4, gzip (1-9), LZJB et ZLE.
- LZ4 est un algorithme de flux offrant une compression et une décompression extrêmement rapides, et est un gain de performance pour la majorité des cas d’utilisation – même avec des CPU très anémiques.
- GZIP est le vénérable algorithme que tous les utilisateurs de type Unix connaissent et aiment. Il peut être mis en œuvre avec des niveaux de compression de 1 à 9, le taux de compression et l’utilisation du CPU augmentant à mesure que les niveaux approchent de 9. Gzip peut être une victoire pour les cas d’utilisation tout-texte (ou autrement extrêmement compressible), mais entraîne fréquemment des goulots d’étranglement du CPU autrement – à utiliser avec prudence, en particulier à des niveaux plus élevés.
- LZJB est l’algorithme original utilisé par ZFS. Il est déprécié, et ne devrait plus être utilisé-LZ4 est supérieur dans toutes les métriques.
- ZLE est Zero Level Encoding- il laisse les données normales entièrement seules, mais compressera de grandes séquences de zéros. Utile pour les ensembles de données entièrement incompressibles (par exemple JPEG, MP4, ou d’autres formats déjà compressés), car il ignore les données incompressibles, mais compresse l’espace libre sur les enregistrements finaux.
Nous recommandons la compression LZ4 pour presque tous les cas d’utilisation concevables ; la pénalité de performance lorsqu’elle rencontre des données incompressibles est très faible, et le gain de performance pour les données typiques est significatif. La copie d’une image VM pour une nouvelle installation de système d’exploitation Windows (juste le système d’exploitation Windows installé, pas encore de données dessus) est allée 27% plus vite avec compression=lz4 que compression=none dans ce test de 2015.
ARC-le cache de remplacement adaptatif
ZFS est le seul système de fichiers moderne que nous connaissons qui utilise son propre mécanisme de cache de lecture, plutôt que de compter sur le cache de page de son système d’exploitation pour garder des copies des blocs récemment lus en RAM pour lui.
Bien que le mécanisme de cache séparé ait ses problèmes – ZFS ne peut pas réagir aux nouvelles demandes d’allocation de mémoire aussi immédiatement que le noyau peut le faire, et donc un nouvel appel mallocate() peut échouer, s’il aurait besoin de la RAM actuellement occupée par l’ARC – il y a une bonne raison, au moins pour le moment, de s’en accommoder.
Tout système d’exploitation moderne bien connu – y compris MacOS, Windows, Linux et BSD – utilise l’algorithme LRU (Least Recently Used) pour sa mise en œuvre de cache de page. LRU est un algorithme naïf qui fait remonter un bloc mis en cache vers le « haut » de la file d’attente à chaque fois qu’il est lu, et qui évince les blocs du « bas » de la file d’attente si nécessaire pour ajouter de nouveaux manques de cache (blocs qui ont dû être lus depuis le disque, plutôt que depuis le cache) au « haut ». »
C’est bien jusqu’à présent, mais dans les systèmes avec de grands ensembles de données de travail, le LRU peut facilement finir par « thrashing »-éviction de blocs très fréquemment nécessaires, pour faire de la place pour des blocs qui ne seront jamais lus à nouveau dans le cache.
L’ARC est un algorithme beaucoup moins naïf, qui peut être considéré comme un cache « pondéré ». Chaque fois qu’un bloc mis en cache est lu, il devient un peu plus « lourd » et plus difficile à évincer – et même après une éviction, le bloc évincé est suivi pendant un certain temps. Un bloc qui a été évincé mais qui doit ensuite être relu dans le cache deviendra également plus « lourd » et plus difficile à évincer.
Le résultat final de tout cela est un cache avec des ratios de réussite généralement beaucoup plus élevés – le rapport entre les succès du cache (lectures servies à partir du cache) et les échecs du cache (lectures servies à partir du disque). C’est une statistique extrêmement importante – non seulement les hits de cache eux-mêmes sont servis des ordres de grandeur plus rapidement, mais les misses de cache peuvent également être servis plus rapidement, car plus de hits de cache==moins de demandes simultanées au disque==moins de latence pour les misses restants qui doivent être servis à partir du disque.
Conclusion
Maintenant que nous avons couvert la sémantique de base de ZFS-comment la copie sur l’écriture fonctionne, et les relations entre les pools, les vdevs, les blocs, les secteurs et les fichiers-nous sommes prêts à parler de performances réelles, avec de vrais chiffres.
Rester à l’écoute pour le prochain versement de notre série sur les fondamentaux du stockage pour voir les performances réelles observées dans les pools utilisant des vdevs miroir et RAIDz, comparés à la fois entre eux et aux topologies RAID traditionnelles du noyau Linux que nous avons explorées précédemment.
Dans un premier temps, nous allons juste couvrir les bases – les topologies ZFS elles-mêmes – mais après cela, nous serons prêts à parler de la configuration et du réglage plus avancés de ZFS, y compris l’utilisation de types de vdev de support comme L2ARC, SLOG et l’allocation spéciale.