
Serhii Maksymenko,
Data Science Solution Architect
La tecnologia di riconoscimento facciale appare oggi in una luce diversa. I casi d’uso includono un’ampia applicazione dal rilevamento del crimine all’identificazione delle malattie genetiche.
Mentre i governi di tutto il mondo hanno investito in sistemi di riconoscimento facciale, alcune città statunitensi come Oakland, Somerville e Portland, lo hanno vietato a causa dei diritti civili e delle preoccupazioni sulla privacy.
Cos’è – una bomba a orologeria o una svolta tecnologica? Questo articolo spiega cos’è il riconoscimento facciale dal punto di vista della tecnologia, e come il deep learning ne aumenta le capacità. Solo capendo come funziona la tecnologia di riconoscimento facciale dall’interno, è possibile capire di cosa è capace.
Aggiornato il 06/09/2020: Masked face detection and recognition
How Deep Learning Can Modernize Face Recognition Software
Download PDF
Come funziona il riconoscimento facciale?
L’algoritmo informatico del software di riconoscimento facciale è un po’ come il riconoscimento visivo umano. Ma se le persone immagazzinano dati visivi in un cervello e richiamano automaticamente i dati visivi una volta necessari, i computer dovrebbero richiedere dati da un database e abbinarli per identificare un volto umano.
In poche parole, un sistema computerizzato dotato di una telecamera, rileva e identifica un volto umano, estrae le caratteristiche facciali come la distanza tra gli occhi, la lunghezza di un naso, la forma di una fronte e gli zigomi. Poi, il sistema riconosce il volto e lo abbina alle immagini memorizzate in un database.
Tuttavia, una tecnologia di riconoscimento facciale tradizionale non è ancora perfetta. Ha sia punti di forza che di debolezza:
| Forza
Identificazione biometrica senza contatto Fino a un secondo di elaborazione dati Compatibilità con la maggior parte delle fotocamere La facilità di integrazione |
Punti deboli
Parecchi e pregiudizi razziali Problemi di privacy dei dati Attacchi di presentazione (PA) Bassa precisione in condizioni di scarsa illuminazione |
Riconoscere le debolezze dei sistemi di riconoscimento facciale, gli scienziati dei dati sono andati oltre. Applicando tecniche tradizionali di computer vision e algoritmi di deep learning, hanno messo a punto il sistema di riconoscimento facciale per prevenire gli attacchi e migliorare la precisione. Ecco come funziona una tecnologia anti-spoofing del volto.
Come l’apprendimento profondo migliora il software di riconoscimento del volto
L’apprendimento profondo è uno dei modi più innovativi per migliorare la tecnologia di riconoscimento del volto. L’idea è quella di estrarre embeddings facciali da immagini con volti. Tali incorporazioni facciali saranno uniche per diversi volti. E l’addestramento di una rete neurale profonda è il modo più ottimale per eseguire questo compito.
A seconda del compito e dei tempi, ci sono due metodi comuni per utilizzare l’apprendimento profondo per i sistemi di riconoscimento dei volti:
Utilizzare modelli pre-addestrati come dlib, DeepFace, FaceNet e altri. Questo metodo richiede meno tempo e sforzo perché i modelli pre-addestrati hanno già una serie di algoritmi per il riconoscimento dei volti. Possiamo anche mettere a punto i modelli pre-addestrati per evitare distorsioni e far funzionare correttamente il sistema di riconoscimento facciale.
Sviluppare una rete neurale da zero. Questo metodo è adatto a sistemi di riconoscimento facciale complessi con funzionalità multiuso. Richiede più tempo e sforzo, e richiede milioni di immagini nel set di dati di addestramento, a differenza di un modello pre-addestrato che richiede solo migliaia di immagini nel caso del transfer learning.

Ma se il sistema di riconoscimento facciale include caratteristiche uniche, può essere un modo ottimale nel lungo periodo. I punti chiave a cui prestare attenzione sono:
- La corretta selezione dell’architettura CNN e della funzione di perdita
- Ottimizzazione del tempo di inferenza
- La potenza di un hardware
Si raccomanda di usare reti neurali convoluzionali (CNN) quando si sviluppa un’architettura di rete poiché hanno dimostrato di essere efficaci nei compiti di riconoscimento e classificazione delle immagini. Per ottenere i risultati attesi, è meglio usare un’architettura di rete neurale generalmente accettata come base, per esempio, ResNet o EfficientNet.
Quando si addestra una rete neurale per lo sviluppo di software di riconoscimento facciale, dovremmo minimizzare gli errori nella maggior parte dei casi. Qui è fondamentale considerare le funzioni di perdita utilizzate per il calcolo dell’errore tra l’output reale e quello previsto. Le funzioni più comunemente usate nei sistemi di riconoscimento facciale sono triplet loss e AM-Softmax.
- La funzione triplet loss implica avere tre immagini di due persone diverse. Ci sono due immagini – ancora e positiva – per una persona, e la terza – negativa – per un’altra persona. I parametri della rete vengono appresi in modo da avvicinare le stesse persone nello spazio delle caratteristiche, e separare persone diverse.
- La funzioneAM-Softmax è una delle modifiche più recenti della funzione softmax standard, che utilizza una particolare regolarizzazione basata su un margine additivo. Permette di ottenere una migliore separabilità delle classi e quindi migliora l’accuratezza del sistema di riconoscimento facciale.
Ci sono anche diversi approcci per migliorare una rete neurale. Nei sistemi di riconoscimento facciale, i più interessanti sono la distillazione della conoscenza, l’apprendimento di trasferimento, la quantizzazione e le convoluzioni separabili in profondità.
- La distillazione della conoscenza coinvolge due reti di dimensioni diverse quando una rete grande insegna la sua variazione più piccola. Il valore chiave è che dopo l’addestramento, la rete più piccola lavora più velocemente di quella grande, dando lo stesso risultato.
- L’approccio del transfer learning permette di migliorare la precisione attraverso l’addestramento dell’intera rete o solo di alcuni strati su un set di dati specifico. Per esempio, se il sistema di riconoscimento facciale ha problemi di pregiudizi razziali, possiamo prendere un particolare set di immagini, diciamo, foto di persone cinesi, e addestrare la rete in modo da raggiungere una maggiore precisione.
- L’approccio di quantizzazione migliora una rete neurale per raggiungere una maggiore velocità di elaborazione. Approssimando una rete neurale che usa numeri in virgola mobile con una rete neurale di numeri a bassa larghezza di bit, possiamo ridurre la dimensione della memoria e il numero di calcoli.
- Le convoluzioni separabili in profondità sono una classe di strati, che permettono di costruire CNN con un set di parametri molto più piccolo rispetto alle CNN standard. Pur avendo un piccolo numero di calcoli, questa caratteristica può migliorare il sistema di riconoscimento facciale in modo da renderlo adatto ad applicazioni di visione mobile.
L’elemento chiave delle tecnologie di apprendimento profondo è la richiesta di hardware ad alta potenza. Quando si utilizzano reti neurali profonde per lo sviluppo di software di riconoscimento facciale, l’obiettivo non è solo quello di migliorare la precisione del riconoscimento, ma anche di ridurre il tempo di risposta. Questo è il motivo per cui la GPU, per esempio, è più adatta per i sistemi di riconoscimento facciale alimentati dall’apprendimento profondo, rispetto alla CPU.
Come abbiamo implementato l’app di riconoscimento facciale alimentata dall’apprendimento profondo
Quando abbiamo sviluppato il Grande Fratello (un’app demo per fotocamera) a MobiDev, avevamo l’obiettivo di creare un software di verifica biometrica con streaming video in tempo reale. Essendo un’app per console locale per Ubuntu e Raspbian, Big Brother è scritta in Golang, e configurata con l’ID della telecamera locale e il tipo di lettore della telecamera tramite il file di configurazione JSON. Questo video descrive come Big Brother funziona in pratica:
Dall’interno, il ciclo di lavoro dell’app Big Brother comprende:
1. Rilevamento dei volti
L’app rileva i volti in un flusso video. Una volta catturato il volto, l’immagine viene ritagliata e inviata al back end tramite richiesta HTTP form-data. L’API del back end salva l’immagine in un file system locale e salva un record nel Detection Log con un personID.
Il back end utilizza Golang e MongoDB Collections per memorizzare i dati dei dipendenti. Tutte le richieste API sono basate su API RESTful.

2. Riconoscimento istantaneo del volto
Il back end ha un lavoratore in background che trova nuovi record non classificati e usa Dlib per calcolare il vettore descrittore 128-dimensionale delle caratteristiche del volto. Ogni volta che un vettore viene calcolato, viene confrontato con più immagini di riferimento del volto calcolando la distanza euclidea da ogni vettore di caratteristiche di ogni persona nel database, trovando una corrispondenza.
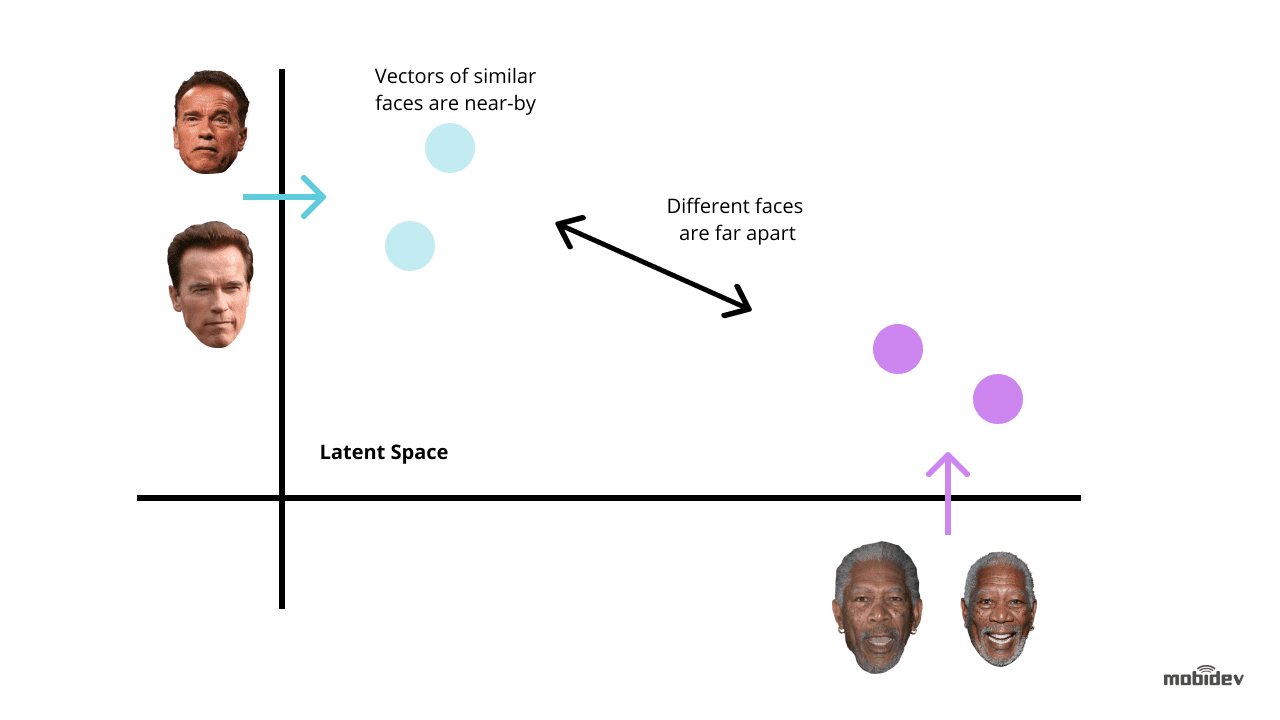
Se la distanza euclidea dalla persona rilevata è inferiore a 0,6, il lavoratore imposta un personID nel registro di rilevamento e lo segna come classificato. Se la distanza supera lo 0,6, crea un nuovo Person ID al log.
3. Azioni di follow-up: avvertire, concedere l’accesso e altro
Le immagini di una persona non identificata vengono inviate al manager corrispondente con notifiche tramite chatbot in messenger. Nell’applicazione Big Brother, abbiamo usato Microsoft Bot Framework e Errbot basato su Python, che ci ha permesso di implementare il chatbot di allerta in cinque giorni.

In seguito, questi record possono essere gestiti tramite il pannello di amministrazione, che memorizza le foto con ID nel database. Il software di riconoscimento facciale funziona in tempo reale ed esegue i compiti di riconoscimento facciale istantaneamente. Utilizzando Golang e MongoDB Collections per l’archiviazione dei dati dei dipendenti, abbiamo inserito il database degli ID, che include 200 voci.
Ecco come è progettata l’applicazione di riconoscimento facciale Big Brother:
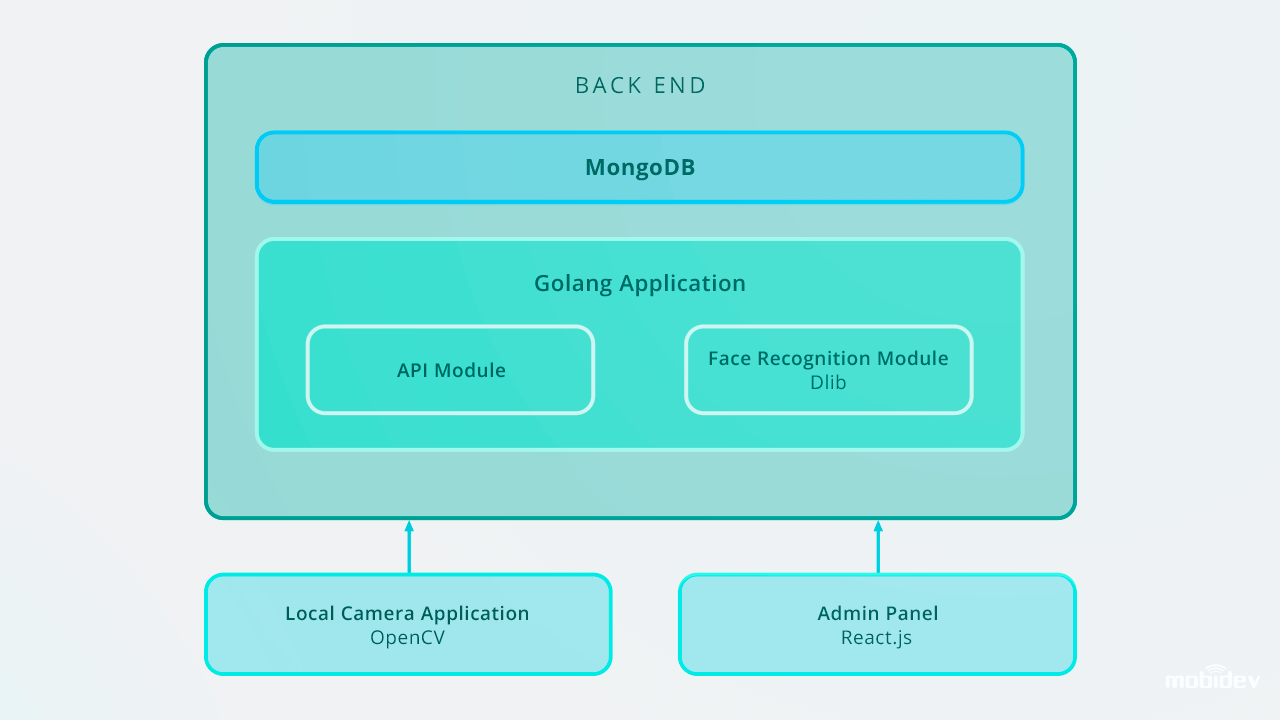
Nel caso di scalare fino a 10.000 voci, si consiglia di migliorare il sistema di riconoscimento facciale al fine di mantenere alta la velocità di riconoscimento sul back-end. Uno dei modi ottimali è quello di utilizzare la parallelizzazione. Impostando un bilanciatore di carico e costruendo diversi web worker, possiamo assicurare il corretto lavoro di una parte del back end e la velocità ottimale di un intero sistema.
Altri casi d’uso di riconoscimento basati sull’apprendimento profondo
Il riconoscimento dei volti non è l’unico compito in cui lo sviluppo di software basato sull’apprendimento profondo può migliorare le prestazioni. Altri esempi includono:
Rilevamento e riconoscimento dei volti mascherati
Da quando il COVID-19 ha fatto sì che le persone in molti paesi indossassero maschere facciali, la tecnologia di riconoscimento facciale è diventata più avanzata. Utilizzando l’algoritmo di apprendimento profondo basato sulle reti neurali convoluzionali, le telecamere possono ora riconoscere i volti coperti da maschere. Gli ingegneri della scienza dei dati utilizzano algoritmi come i modelli di riconoscimento multigranulare e perioculare basati sugli occhi del viso per migliorare le capacità del sistema di riconoscimento facciale. Identificando tali caratteristiche del viso come la fronte, il contorno del viso, i dettagli oculari e perioculari, le sopracciglia, gli occhi e gli zigomi, questi modelli permettono il riconoscimento dei volti mascherati con una precisione fino al 95%.
Un buon esempio di tale sistema è la tecnologia di riconoscimento facciale creata da una delle aziende cinesi. Il sistema è composto da due algoritmi: il riconoscimento dei volti basato sul deep learning e la misurazione della temperatura con immagini termiche a infrarossi. Quando le persone con maschere facciali stanno davanti alla telecamera, il sistema estrae le caratteristiche del viso e le confronta con le immagini esistenti nel database. Allo stesso tempo, il meccanismo di misurazione della temperatura a infrarossi misura la temperatura, rilevando così le persone con temperature anormali.
Rilevamento dei difetti
Negli ultimi due anni, i produttori hanno utilizzato l’ispezione visiva basata sull’AI per il rilevamento dei difetti. Lo sviluppo di algoritmi di apprendimento profondo permette a questo sistema di definire automaticamente i più piccoli graffi e crepe, evitando il fattore umano.
Rilevamento delle anomalie del corpo
L’azienda israeliana Aidoc ha sviluppato una soluzione alimentata dal deep learning per la radiologia. Analizzando le immagini mediche, questo sistema rileva le anomalie in un torace, colonna vertebrale, testa e addome.
Identificazione degli altoparlanti
La tecnologia di identificazione degli altoparlanti creata dalla società Phonexia identifica anche gli altoparlanti utilizzando l’approccio di apprendimento metrico. Il sistema riconosce i parlanti in base alla voce, producendo modelli matematici del discorso umano chiamati impronte vocali. Queste impronte vocali sono immagazzinate in database, e quando una persona parla la tecnologia dell’altoparlante identifica l’impronta vocale unica.
Riconoscimento delle emozioni
Il riconoscimento delle emozioni umane è un compito fattibile oggi. Tracciando i movimenti di un volto tramite una telecamera, la tecnologia Emotion Recognition categorizza le emozioni umane. L’algoritmo di apprendimento profondo identifica i punti di riferimento di un volto umano, rileva un’espressione facciale neutra e misura le deviazioni delle espressioni facciali riconoscendo quelle più positive o negative.
Riconoscimento delle azioni
L’azienda Visual One, che è un fornitore di Nest Cams, ha alimentato il suo prodotto con AI. Utilizzando tecniche di apprendimento profondo, hanno messo a punto Nest Cams per riconoscere non solo diversi oggetti come persone, animali domestici, auto, ecc, ma anche identificare le azioni. L’insieme di azioni da riconoscere è personalizzabile e selezionato dall’utente. Ad esempio, una telecamera può riconoscere un gatto che graffia la porta, o un bambino che gioca con la stufa.
Se per riassumere, reti neurali profonde sono un potente strumento per l’umanità. E solo un umano decide quale futuro tecnologico sta arrivando.
Come il Deep Learning può modernizzare il software di riconoscimento dei volti
Download PDF