
Come tutti noi entriamo nel terzo mese della pandemia COVID-19 e cerchiamo nuovi progetti per tenerci impegnati (leggi: sani di mente), possiamo interessarvi all’apprendimento dei fondamenti dello storage dei computer? Tranquillamente questa primavera, abbiamo già esaminato alcune basi necessarie come come testare la velocità dei vostri dischi e cosa diavolo è il RAID. Nella seconda di queste storie, abbiamo anche promesso un seguito per esplorare le prestazioni di varie topologie a dischi multipli in ZFS, il filesystem next-gen di cui avete sentito parlare per le sue apparizioni ovunque, da Apple a Ubuntu.
Bene, oggi è il giorno di esplorare, lettori curiosi di ZFS. Sappiate solo che, nelle sobrie parole dello sviluppatore di OpenZFS Matt Ahrens, “è davvero complicato.”
Ma prima di arrivare ai numeri – che stanno arrivando, lo prometto!-per tutti i modi in cui potete modellare otto dischi di ZFS, dobbiamo parlare di come ZFS memorizza i vostri dati su disco in primo luogo.
Zpools, vdevs, e dispositivi
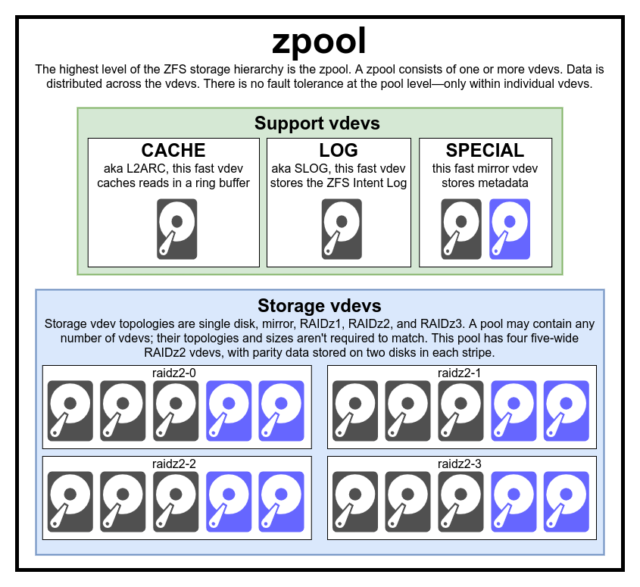

Per capire veramente ZFS, dovete prestare vera attenzione alla sua effettiva struttura. ZFS fonde i tradizionali livelli di gestione del volume e del filesystem, e usa un meccanismo transazionale copy-on-write – entrambe queste cose significano che il sistema è strutturalmente molto diverso dai filesystem convenzionali e dagli array RAID. Il primo gruppo di blocchi principali da capire sono zpools, vdevs e devices.
zpool
Il zpool è la struttura ZFS più alta. Uno zpool contiene uno o più vdevs, ognuno dei quali a sua volta contiene uno o più devices. Gli zpool sono unità autonome: un computer fisico può avere due o più zpool separati, ma ognuno è completamente indipendente dagli altri. Gli zpool non possono condividere vdevs tra loro.
La ridondanza di ZFS è a livello vdev, non a livello zpool. Non c’è assolutamente ridondanza a livello di zpool – se uno storage vdev o SPECIAL vdev viene perso, l’intero zpool viene perso con esso.
I moderni zpool possono sopravvivere alla perdita di un CACHE o LOG vdev-anche se possono perdere una piccola quantità di dati sporchi, se perdono un LOG vdev durante un’interruzione di corrente o un crash di sistema.
E’ un malinteso comune che ZFS “stripe” le scritture attraverso il pool-ma questo non è esatto. Uno zpool non è un RAID0 dall’aspetto buffo, è un JBOD dall’aspetto buffo, con un complesso meccanismo di distribuzione soggetto a cambiamenti.
Per la maggior parte, le scritture sono distribuite sui vdev disponibili in accordo al loro spazio libero disponibile, così che tutti i vdev saranno teoricamente pieni allo stesso tempo. Nelle versioni più recenti di ZFS, l’utilizzo dei vdev può anche essere preso in considerazione – se un vdev è significativamente più occupato di un altro (es: a causa del carico di lettura), può essere saltato temporaneamente per la scrittura nonostante abbia il più alto rapporto di spazio libero disponibile.
Il meccanismo di consapevolezza dell’utilizzo costruito nei moderni metodi di distribuzione della scrittura di ZFS può diminuire la latenza e aumentare il throughput durante i periodi di carico insolitamente alto-ma non dovrebbe essere scambiato per carta bianca per mischiare dischi rust lenti e SSD veloci volenti o nolenti nello stesso pool. Un tale pool disadattato generalmente funzionerà ancora come se fosse composto interamente dal dispositivo più lento presente.
vdev
Ogni zpool consiste di uno o più vdevs(abbreviazione di dispositivo virtuale). Ogni vdev, a sua volta, consiste di uno o più devices reali. La maggior parte dei vdev sono usati per l’archiviazione semplice, ma esistono anche diverse classi di supporto speciale di vdev, tra cui CACHE, LOG e SPECIAL. Ognuno di questi tipi di vdev può offrire una delle cinque topologie: dispositivo singolo, RAIDz1, RAIDz2, RAIDz3 o mirror.
RAIDz1, RAIDz2 e RAIDz3 sono varietà speciali di ciò che i greybeards dell’archiviazione chiamano “diagonal parity RAID”. L’1, il 2 e il 3 si riferiscono a quanti blocchi di parità sono assegnati a ciascuna striscia di dati. Piuttosto che avere interi dischi dedicati alla parità, i vdev RAIDz distribuiscono la parità in modo semi-uguale tra i dischi. Un array RAIDz può perdere tanti dischi quanti sono i blocchi di parità; se ne perde un altro, fallisce e porta con sé il zpool.
I vdev mirror sono esattamente quello che sembrano: in un vdev mirror, ogni blocco è memorizzato su ogni dispositivo nel vdev. Sebbene i mirror a due larghezze siano i più comuni, un vdev mirror può contenere qualsiasi numero arbitrario di dispositivi – tre vie sono comuni nelle configurazioni più grandi per le maggiori prestazioni di lettura e la resistenza agli errori. Un vdev mirror può sopravvivere a qualsiasi guasto, finché almeno un dispositivo nel vdev rimane sano.
I vdev a singolo dispositivo sono proprio quello che sembrano-e sono intrinsecamente pericolosi. Un vdev single-device non può sopravvivere a nessun guasto e se è usato come vdev di storage o SPECIAL, il suo guasto porterà l’intero zpool giù con esso. Fate molta, molta attenzione qui.
CACHE, LOG, e SPECIAL vdev possono essere creati usando qualsiasi topologia di cui sopra-ma ricordate, la perdita di un SPECIAL vdev significa la perdita del pool, quindi la topologia ridondante è fortemente incoraggiata.
device
Questo è probabilmente il termine ZFS più facile da capire-è letteralmente solo un dispositivo a blocchi ad accesso casuale. Ricordate, vdevs sono fatti di dispositivi individuali, e il zpool è fatto di vdevs.
I dischi – sia a ruggine che a stato solido – sono i dispositivi a blocchi più comuni usati come vdev building blocks. Qualsiasi cosa con un descrittore in /dev che permetta l’accesso casuale funzionerà, anche se – così interi array RAID hardware possono essere (e a volte sono) usati come dispositivi individuali.
Il semplice file grezzo è uno dei più importanti dispositivi a blocchi alternativi da cui un vdev può essere costruito. I pool di prova fatti di file sparsi sono un modo incredibilmente comodo per fare pratica con i comandi di zpool, e vedere quanto spazio è disponibile su un pool o vdev di una data topologia.

Diciamo che state pensando di costruire un server a otto alloggiamenti, e siete abbastanza sicuri di voler usare dischi da 10TB (~9300 GiB), ma non siete sicuri di quale topologia si adatti meglio alle vostre esigenze. Nell’esempio precedente, abbiamo costruito un pool di prova con file sparsi in pochi secondi e ora sappiamo che un vdev RAIDz2 composto da otto dischi da 10TB offre 50TiB di capacità utilizzabile.
C’è una classe speciale di device-la SPARE. I dispositivi Hotspare, a differenza dei dispositivi normali, appartengono all’intero pool, non a un singolo vdev. Se qualsiasi vdev nel pool subisce un guasto del dispositivo, e un SPARE è collegato al pool e disponibile, il SPARE si attaccherà automaticamente al vdev degradato.
Una volta collegato al vdev degradato, il SPARE inizia a ricevere copie o ricostruzioni dei dati che dovrebbero essere sul dispositivo mancante. Nel RAID tradizionale, questo sarebbe chiamato “ricostruzione” – in ZFS, è chiamato “resilvering.”
È importante notare che i dispositivi SPARE non sostituiscono permanentemente i dispositivi guasti. Sono solo dei segnaposto, destinati a ridurre al minimo la finestra durante la quale un vdev funziona in modo degradato. Una volta che l’amministratore ha sostituito il dispositivo fallito del vdev e il nuovo dispositivo sostitutivo permanente si resilvera’, il SPARE si stacca dal vdev, e ritorna al servizio di tutto il pool.
Insiemi di dati, blocchi e settori
Il prossimo set di blocchi che dovrai capire nel tuo viaggio in ZFS riguarda non tanto l’hardware, ma come i dati stessi sono organizzati e memorizzati. Stiamo saltando alcuni livelli qui – come il metaslab – nell’interesse di mantenere le cose il più semplici possibile, pur comprendendo la struttura generale.
Datasets

Un ZFS dataset è approssimativamente analogo ad un filesystem montato standard – come un filesystem convenzionale, sembra ad un’ispezione casuale come se fosse “solo un’altra cartella”. Ma anche come i filesystem montati convenzionali, ogni ZFS datasetha il proprio set di proprietà sottostanti.
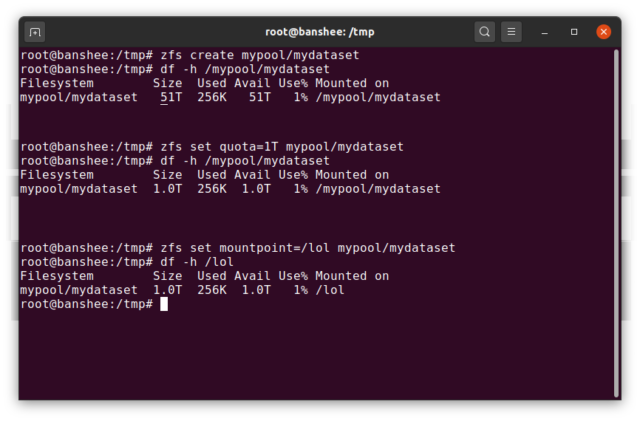
Prima di tutto, un dataset può avere una quota assegnata ad esso. Se si zfs set quota=100G poolname/datasetname, non sarà possibile mettere più di 100GiB di dati nella cartella /poolname/datasetname montata sul sistema.
Nota la presenza e l’assenza di slash iniziali nell’esempio precedente? Ogni set di dati ha il suo posto sia nella gerarchia ZFS, sia nella gerarchia di montaggio del sistema. Nella gerarchia ZFS, non ci sono slash iniziano con il nome del pool, e poi il percorso da un dataset al successivo – ad esempio pool/parent/child per un dataset chiamato child sotto il dataset padre parent, in un pool creativamente chiamato pool.
Di default, il punto di montaggio di un dataset sarà equivalente al suo nome gerarchico ZFS, con una barra iniziale – il pool chiamato pool è montato a /pool, il dataset parent è montato a /pool/parent, e il dataset figlio child è montato a /pool/parent/child. Il punto di montaggio di sistema di un dataset può essere alterato, tuttavia.
Se dovessimo zfs set mountpoint=/lol pool/parent/child, il dataset pool/parent/child sarebbe effettivamente montato sul sistema come /lol.
In aggiunta ai dataset, dovremmo menzionare zvols. Un zvol è approssimativamente analogo a un dataset, eccetto che non ha effettivamente un filesystem in esso – è solo un dispositivo a blocchi. Potresti, per esempio, creare un zvol chiamato mypool/myzvol, poi formattarlo con il filesystem ext4, quindi montare quel filesystem: ora hai un filesystem ext4, ma con tutte le caratteristiche di sicurezza di ZFS! Questo potrebbe sembrare stupido su un singolo computer, ma ha molto più senso come back end per un’esportazione iSCSI.
Blocchi
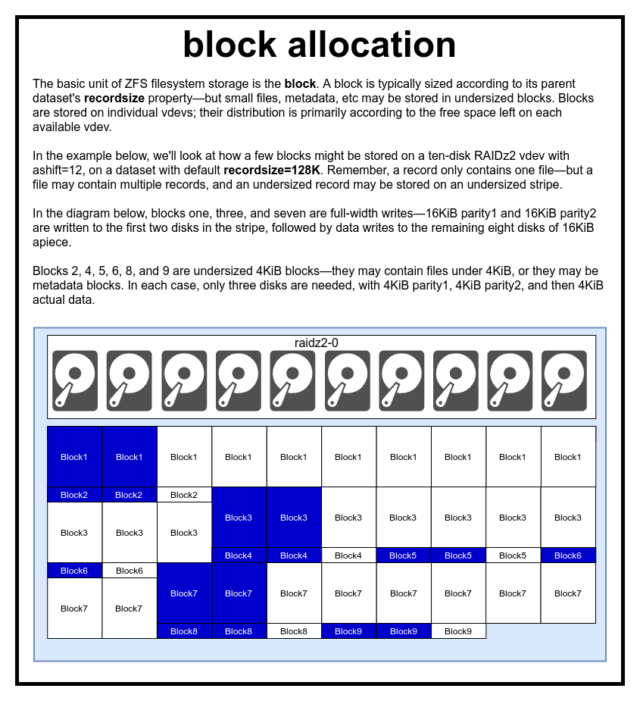

In un pool ZFS, tutti i dati, inclusi i metadati, sono memorizzati in blocks. La dimensione massima di un block è definita per ogni dataset nella proprietà recordsize. Recordsize è mutabile, ma cambiare recordsize non cambierà la dimensione o il layout di qualsiasi blocks che sia già stato scritto nel set di dati – solo per i nuovi blocchi quando vengono scritti.
Se non definito diversamente, l’attuale recordsize predefinito è 128KiB. Questo rappresenta una sorta di scomodo compromesso in cui le prestazioni non saranno ideali per molte cose, ma non saranno neanche terribili per molte cose. Recordsize può essere impostato a qualsiasi valore da 4K a 1M. (Recordsize può essere impostato anche più grande con ulteriore regolazione e sufficiente determinazione, ma raramente è una buona idea.)
Ogni dato block fa riferimento ai dati di un solo file – non puoi stipare due file separati nello stesso block. Ogni file sarà composto da uno o più blocks, a seconda della dimensione. Se un file è più piccolo di recordsize, sarà memorizzato in un blocco sottodimensionato – per esempio, un block che contiene un file di 2KiB occuperà solo un singolo sector 4KiB sul disco.
Se un file è abbastanza grande da richiedere più blocks, tutti i record che contengono quel file saranno recordsize di lunghezza – incluso l’ultimo record, che può essere per lo più spazio libero.
Zvols non hanno la proprietà recordsize – invece, hanno volblocksize, che è approssimativamente equivalente.
Settori
L’ultimo blocco da discutere è il modesto sector. Un sector è la più piccola unità fisica che può essere scritta o letta dal suo device sottostante. Per diversi decenni, la maggior parte dei dischi ha usato 512 byte sectors. Più recentemente, la maggior parte dei dischi usa 4KiB sectors, e alcuni – in particolare gli SSD – usano 8KiB sectors, o anche più grandi.
ZFS ha una proprietà che permette di impostare manualmente la dimensione sector, chiamata ashift. Un po’ confusamente, ashift è in realtà l’esponente binario che rappresenta la dimensione del settore-per esempio, impostando ashift=9 significa che la dimensione sector sarà 2^9, o 512 byte.
ZFS interroga il sistema operativo per i dettagli su ogni blocco device quando viene aggiunto a un nuovo vdev, e in teoria imposterà automaticamente ashift correttamente in base a queste informazioni. Sfortunatamente, ci sono molti dischi che mentono spudoratamente su quale sia la loro dimensione sector, al fine di rimanere compatibili con Windows XP (che era incapace di comprendere dischi con qualsiasi altra dimensione sector).
Questo significa che un amministratore ZFS è fortemente consigliato di essere consapevole della reale dimensione sector del suo devices, e impostare manualmente ashift di conseguenza. Se ashift è impostato troppo basso, si incorre in un’astronomica penalità di amplificazione in lettura/scrittura – scrivere un “settore” di 512 byte su un sector reale di 4KiB significa dover scrivere il primo “settore”, poi leggere il 4KiB sector, modificarlo con il secondo “settore” di 512 byte, scriverlo di nuovo su un *nuovo* 4KiB sector, e così via, per ogni singola scrittura.
In termini reali, questa penalità di amplificazione colpisce un SSD Samsung EVO – che dovrebbe avere ashift=13, ma mente sulla sua dimensione di settore e quindi ha come default ashift=9 se non viene annullato da un amministratore esperto – abbastanza duramente da farlo apparire più lento di un disco rust convenzionale.
Al contrario, non c’è virtualmente nessuna penalità per impostare ashift troppo alto. Non c’è una reale penalità in termini di prestazioni, e gli aumenti di slack space sono infinitesimali (o nulli, con la compressione abilitata). Raccomandiamo vivamente che anche i dischi che usano realmente settori da 512 byte siano impostati ashift=12 o anche ashift=13 per una prova futura.
La proprietà ashift è per-vdev-non per pool, come si pensa comunemente ed erroneamente!- ed è immutabile, una volta impostata. Se accidentalmente sbagliate ashift quando aggiungete un nuovo vdev a un pool, avete irrevocabilmente contaminato quel pool con un vdev drasticamente sottoperformante, e generalmente non avete altra soluzione che distruggere il pool e ricominciare da capo. Persino la rimozione di vdev non può salvarvi da un’impostazione ashift sbagliata!
Semantica della copia su scrittura




CoW-Copy on Write-è una base fondamentale sotto la maggior parte di ciò che rende ZFS fantastico. Il concetto di base è semplice: se chiedete a un filesystem tradizionale di modificare un file in-place, esso fa esattamente ciò che gli avete chiesto. Se chiedi ad un filesystem copy-on-write di fare la stessa cosa, ti dice “ok” – ma ti sta mentendo.
Invece, il filesystem copy-on-write scrive una nuova versione del block che hai modificato, poi aggiorna i metadati del file per scollegare il vecchio block, e collegare il nuovo block che hai appena scritto.
Lo scollegamento del vecchio block e il collegamento del nuovo è realizzato in una singola operazione, quindi non può essere interrotto – se si scarica l’alimentazione dopo che è successo, si ha la nuova versione del file, e se si scarica l’alimentazione prima, allora si ha la vecchia versione. Sei sempre coerente con il filesystem, in entrambi i casi.
Copy-on-write in ZFS non è solo a livello di filesystem, è anche a livello di gestione del disco. Questo significa che il RAID hole – una condizione in cui una striscia viene scritta solo parzialmente prima che il sistema si blocchi, rendendo l’array incoerente e corrotto dopo un riavvio – non ha effetto su ZFS. Le scritture sulle strisce sono atomiche, il vdev è sempre coerente, e Bob è tuo zio.
ZIL-il log degli intenti ZFS
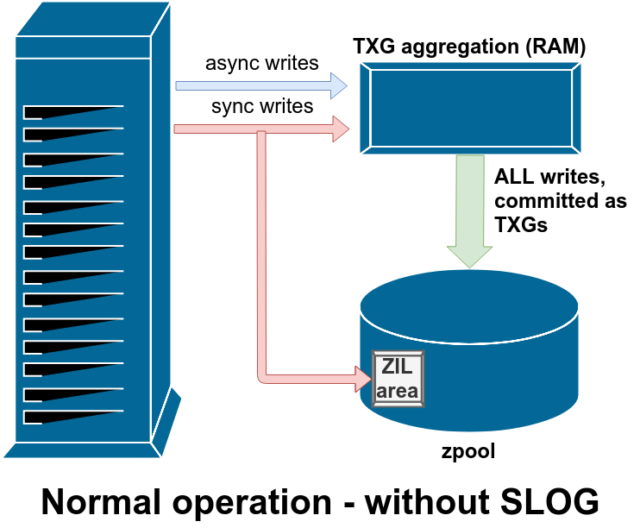

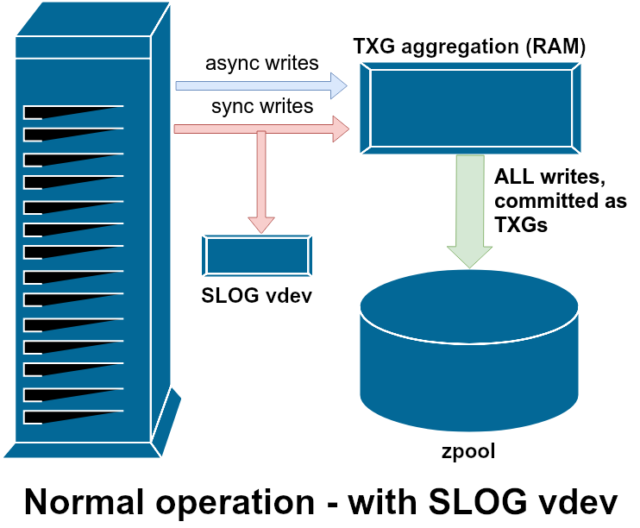

Ci sono due grandi categorie di operazioni di scrittura: sincrone (sync) e asincrone (async). Per la maggior parte dei carichi di lavoro, la stragrande maggioranza delle operazioni di scrittura sono asincrone – al filesystem è permesso di aggregarle e impegnarle in lotti, riducendo la frammentazione e aumentando enormemente il throughput.
Le scritture sincrone sono un animale completamente diverso – quando un’applicazione richiede una scrittura sincrona, sta dicendo al filesystem “devi impegnare questo su uno storage non volatile ora, e finché non lo fai, non posso fare altro”. Le scritture di sincronizzazione devono quindi essere impegnate su disco immediatamente – e se questo aumenta la frammentazione o diminuisce il throughput, così sia.
ZFS gestisce le scritture di sincronizzazione in modo diverso dai normali filesystem – invece di scaricare immediatamente le scritture di sincronizzazione nella memoria normale, ZFS le impegna in un’area di memoria speciale chiamata ZFS Intent Log, o ZIL. Il trucco qui è che queste scritture rimangono anche in memoria, essendo aggregate insieme alle normali richieste di scrittura asincrone, per poi essere scaricate nello storage come TXGs (Transaction Groups) perfettamente normali.
Nel funzionamento normale, lo ZIL viene scritto e mai più letto. Quando le scritture salvate sulla ZIL sono commesse alla memoria principale dalla RAM in TXGs normali pochi istanti dopo, sono scollegate dalla ZIL. L’unica volta che la ZIL viene letta è all’importazione del pool.
Se ZFS va in crash – o il sistema operativo va in crash, o c’è un’interruzione di corrente non gestita – mentre ci sono dati nella ZIL, quei dati saranno letti durante la prossima importazione del pool (ad esempio quando un sistema in crash viene riavviato). Qualunque cosa ci sia nello ZIL verrà letta, aggregata in TXGs, impegnata nella memoria principale, e poi scollegata dallo ZIL durante il processo di importazione.
Una delle classi di supporto vdev disponibili è LOG-anche conosciuta come SLOG, o dispositivo di LOG secondario. Tutto ciò che la SLOG fa è fornire al pool un vdev separato – e si spera molto più veloce, con una resistenza alla scrittura molto alta – per memorizzare il ZIL, invece di mantenere il ZIL sullo storage principale vdevs. In tutti gli aspetti, il ZIL si comporta allo stesso modo sia che sia sullo storage principale, o su un vdev LOG, ma se il vdev LOG ha prestazioni di scrittura molto elevate, allora i ritorni di scrittura sincronizzati avverranno molto rapidamente.
L’aggiunta di un vdev LOG a un pool non può assolutamente e non migliorerà direttamente le prestazioni di scrittura asincrona – anche se si forzano tutte le scritture nello ZIL usando zfs set sync=always, esse vengono ancora commesse allo storage principale in TXGs nello stesso modo e allo stesso ritmo che avrebbero senza il LOG. Gli unici miglioramenti diretti delle prestazioni sono per la latenza della scrittura sincrona (poiché la maggiore velocità di LOG permette alla chiamata sync di tornare più velocemente).
Tuttavia, in un ambiente che richiede già molte scritture sincrone, un vdev LOG può indirettamente accelerare anche le scritture asincrone e le letture nella cache. Offloading ZIL writes to a separate LOG vdev means less contention for IOPS on primary storage, thereby increasing performance for all reads and writes to some degree.
Snapshots
Copy-on-write semantics are also the necessary underpinning for ZFS’s atomic snapshots and incremental asynchronous replication. Il filesystem live ha un albero di puntatori che segna tutti i records che contengono dati correnti – quando si prende uno snapshot, si fa semplicemente una copia di quell’albero di puntatori.
Quando un record viene sovrascritto nel filesystem live, ZFS scrive prima la nuova versione del block nello spazio inutilizzato. Poi scollega la vecchia versione del block dal filesystem corrente. Ma se qualsiasi snapshot fa riferimento al vecchio block, questo rimane ancora immutabile. Il vecchio block non sarà effettivamente recuperato come spazio libero finché tutti i snapshots che fanno riferimento a quel block non saranno stati distrutti!
Replicazione

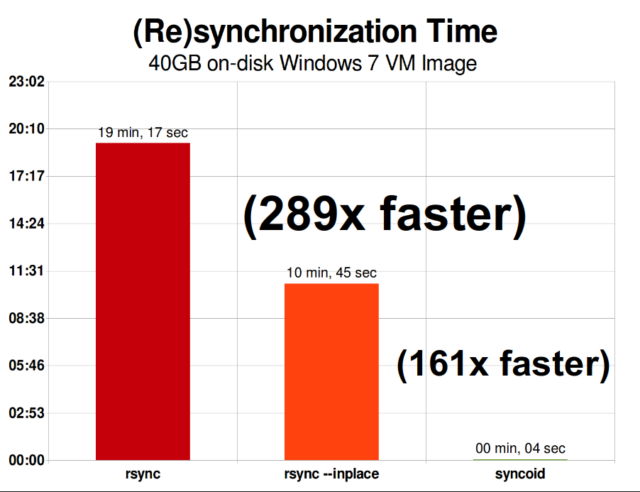
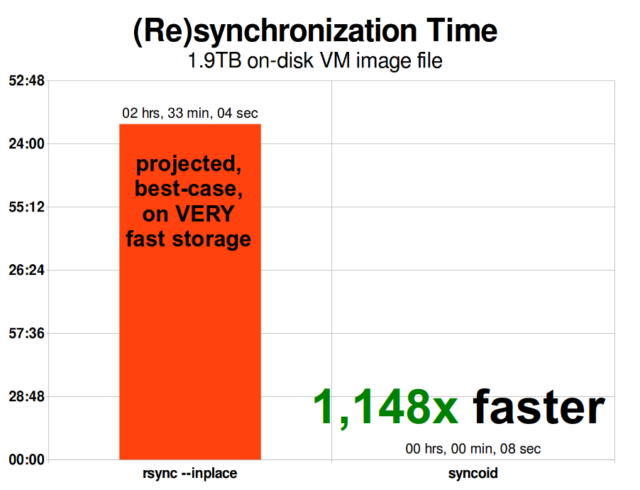 Una volta che hai capito come funzionano gli snapshot, sei in una buona posizione per capire la replica. Poiché un’istantanea è semplicemente un albero di puntatori a
Una volta che hai capito come funzionano gli snapshot, sei in una buona posizione per capire la replica. Poiché un’istantanea è semplicemente un albero di puntatori arecords, ne consegue che se noizfs sendun’istantanea, stiamo inviando sia quell’albero che tutti i record associati. Quando facciamo il pipe di quelzfs senda unzfs receivesulla destinazione, scrive sia il contenuto effettivo diblock, sia l’albero di puntatori che fa riferimento ablocks, nel set di dati di destinazione.
Le cose si fanno più interessanti sul vostro secondo zfs send. Ora che avete due sistemi, ognuno contenente lo snapshot poolname/datasetname@1, potete prendere un nuovo snapshot, poolname/datasetname@2. Quindi sul pool sorgente, hai datasetname@1 e datasetname@2, e sul pool di destinazione, finora hai solo la prima istantanea datasetname@1.
Poiché abbiamo un’istantanea comune tra sorgente e destinazione datasetname@1, possiamo costruire un zfs send incrementale su di essa. Quando chiediamo al sistema di zfs send -i poolname/datasetname@1 poolname/datasetname@2, esso confronta i due alberi dei puntatori. Qualsiasi puntatore che esiste solo in @2 ovviamente fa riferimento al nuovo blocks-quindi avremo bisogno anche del contenuto di questi blocks.
Sul sistema remoto, il piping nel send incrementale risultante è altrettanto facile. Prima, scriviamo tutti i nuovi records inclusi nel flusso send, poi aggiungiamo i puntatori a quei blocks. Presto, abbiamo @2 sul nuovo sistema!
La replica incrementale asincrona di ZFS è un enorme miglioramento rispetto alle precedenti tecniche non basate su snapshot come rsync. In entrambi i casi, solo i dati modificati devono essere inviati via cavo, ma rsync deve prima leggere tutti i dati dal disco, su entrambi i lati, per fare il checksum e confrontarli. Al contrario, la replica ZFS non ha bisogno di leggere altro che gli alberi dei puntatori e qualsiasi blocksche l’albero dei puntatori contiene che non sia già presente nell’istantanea comune.
Compressione in linea
La semantica copy-on-write rende anche più facile offrire compressione in linea. Con un filesystem tradizionale che offre modifiche sul posto, la compressione è problematica – sia la vecchia versione che la nuova versione dei dati modificati devono stare esattamente nello stesso spazio.
Se consideriamo un pezzo di dati nel mezzo di un file che inizia la vita come 1MiB di zeri-0x00000000 ad nauseam- si comprimerebbe fino ad un singolo settore del disco molto facilmente. Ma cosa succede se sostituiamo quel 1MiB di zeri con 1MiB di dati incomprimibili, come JPEG o rumore pseudo-casuale? Improvvisamente, quel 1MiB di dati ha bisogno di 256 settori da 4KiB, non solo uno, e il buco nel mezzo del file è largo solo un settore.
ZFS non ha questo problema, poiché i record modificati sono sempre scritti nello spazio inutilizzato – l’originale block occupa solo un singolo 4KiB sector, e il nuovo record ne occupa 256, ma questo non è un problema – il nuovo chunk modificato dal “centro” del file sarebbe stato scritto nello spazio inutilizzato sia che la sua dimensione cambiasse o meno, quindi per ZFS, questo “problema” è solo un altro giorno in ufficio.
La compressione in linea di ZFS è disattivata per impostazione predefinita, e offre algoritmi collegabili – attualmente inclusi LZ4, gzip (1-9), LZJB, e ZLE.
- LZ4 è un algoritmo di flusso che offre una compressione e decompressione estremamente rapida, ed è una vittoria di prestazioni per la maggior parte dei casi d’uso – anche con CPU molto anemiche.
- GZIP è il venerabile algoritmo che tutti gli utenti Unix-like conoscono e amano. Può essere implementato con livelli di compressione 1-9, con un aumento del rapporto di compressione e dell’utilizzo della CPU man mano che i livelli si avvicinano al 9. Gzip può essere una vittoria per tutti i casi d’uso di testo (o comunque estremamente comprimibili), ma spesso si traduce in colli di bottiglia della CPU altrimenti-usare con cautela, in particolare a livelli più alti.
- LZJB è l’algoritmo originale usato da ZFS. È deprecato, e non dovrebbe più essere usato-LZ4 è superiore in ogni metrica.
- ZLE è Zero Level Encoding – lascia i dati normali completamente da soli, ma comprimerà grandi sequenze di zeri. Utile per insiemi di dati interamente incomprimibili (ad esempio JPEG, MP4, o altri formati già compressi), poiché ignora i dati incomprimibili, ma comprime lo spazio residuo sui record finali.
Raccomandiamo la compressione LZ4 per quasi tutti i casi d’uso concepibili; la penalizzazione delle prestazioni quando incontra dati incomprimibili è molto piccola, e il guadagno di prestazioni per dati tipici è significativo. Copiare un’immagine VM per una nuova installazione del sistema operativo Windows (solo il sistema operativo Windows installato, nessun dato su di esso) è stato il 27% più veloce con compression=lz4 rispetto a compression=none in questo test del 2015.
ARC-the Adaptive Replacement Cache
ZFS è l’unico filesystem moderno che conosciamo che utilizza un proprio meccanismo di cache di lettura, piuttosto che affidarsi alla cache di pagina del sistema operativo per mantenere copie dei blocchi letti di recente nella RAM.
Anche se il meccanismo di cache separata ha i suoi problemi – ZFS non può reagire a nuove richieste di allocare memoria così immediatamente come può fare il kernel, e quindi una nuova chiamata mallocate() può fallire, se avrebbe bisogno di RAM attualmente occupata dall’ARC – ci sono buone ragioni, almeno per ora, per sopportarlo.
Ogni noto sistema operativo moderno – compresi MacOS, Windows, Linux e BSD – utilizza l’algoritmo LRU (Least Recently Used) per la sua implementazione della cache di pagina. LRU è un algoritmo ingenuo che fa salire un blocco in cache fino alla “cima” della coda ogni volta che viene letto, e sfratta i blocchi dal “fondo” della coda come necessario per aggiungere nuove cache miss (blocchi che hanno dovuto essere letti dal disco, piuttosto che dalla cache) alla “cima.”
Questo va bene fino a un certo punto, ma in sistemi con grandi insiemi di dati funzionanti, l’LRU può facilmente finire con il “thrashing” – sfrattare blocchi molto frequentemente necessari, per fare spazio a blocchi che non verranno mai più letti dalla cache.
L’ARC è un algoritmo molto meno ingenuo, che può essere pensato come una cache “pesata”. Ogni volta che un blocco in cache viene letto, diventa un po’ più “pesante” e più difficile da sfrattare, e anche dopo uno sfratto, il blocco sfrattato viene monitorato per un periodo di tempo. Un blocco che è stato sfrattato ma che poi deve essere riletto nella cache diventerà anch’esso più “pesante” e più difficile da sfrattare.
Il risultato finale di tutto questo è una cache con un hit ratio tipicamente molto maggiore, il rapporto tra i successi della cache (letture servite dalla cache) e le mancanze della cache (letture servite dal disco). Questa è una statistica estremamente importante: non solo gli hit della cache vengono serviti più rapidamente, ma anche i miss della cache possono essere serviti più rapidamente, poiché più hit della cache = meno richieste concorrenti al disco = minore latenza per quei miss rimanenti che devono essere serviti dal disco.
Conclusione
Ora che abbiamo coperto la semantica di base di ZFS – come funziona il copy-on-write, e le relazioni tra pool, vdev, blocchi, settori e file – siamo pronti per parlare di prestazioni reali, con numeri reali.
Starete sintonizzati per la prossima puntata della nostra serie sui fondamenti dello storage per vedere le prestazioni effettive viste nei pool che utilizzano vdev mirror e RAIDz, confrontati sia tra loro che con le tradizionali topologie RAID del kernel Linux che abbiamo esplorato in precedenza.
Inizialmente, copriremo solo le basi – le topologie ZFS stesse – ma dopo questo, saremo pronti a parlare della configurazione e messa a punto più avanzata di ZFS, compreso l’uso di tipi di vdev di supporto come L2ARC, SLOG, e Special Allocation.