
Serhii Maksymenko,
Data Science Solution Architect
Face recognition technology appears in a different light today. Os casos de uso incluem uma ampla aplicação desde a detecção de crimes até a identificação de doenças genéticas.
Embora governos de todo o mundo tenham investido em sistemas de reconhecimento facial, algumas cidades norte-americanas como Oakland, Somerville e Portland a proibiram devido a questões de direitos civis e privacidade.
O que é isso – uma bomba relógio ou um avanço tecnológico? Este artigo abre o que é o reconhecimento de rostos a partir de uma perspectiva tecnológica, e como o aprendizado profundo aumenta suas capacidades. Somente percebendo como a tecnologia de reconhecimento de face funciona de dentro para fora, é possível entender do que ela é capaz.
Atualizado em 06/09/2020: Detecção e reconhecimento facial mascarado
Como a aprendizagem profunda pode modernizar o software de reconhecimento facial
Download PDF
Como funciona o reconhecimento facial?
O algoritmo de computador do software de reconhecimento facial é um pouco como o reconhecimento visual humano. Mas se as pessoas armazenam dados visuais num cérebro e automaticamente se lembram de dados visuais uma vez necessários, os computadores devem solicitar dados de uma base de dados e combiná-los para identificar um rosto humano.
Em resumo, um sistema computadorizado equipado por uma câmera, detecta e identifica um rosto humano, extrai características faciais como a distância entre os olhos, um comprimento de um nariz, uma forma de uma testa e maçãs do rosto. Em seguida, o sistema reconhece o rosto e o combina com imagens armazenadas em um banco de dados.
No entanto, uma tecnologia tradicional de reconhecimento facial ainda não é perfeita. Ela tem tanto força quanto fraquezas:
| Força
Identificação biométrica sem contacto > Até um segundo de processamento de dados > Compatibilidade com a maioria das câmaras > A facilidade de integração > |
Fraquezas
Guias e viés racial Precisão dos dados Ataques de apresentação (PA) Baixa precisão em más condições de iluminação |
Realizar os pontos fracos dos sistemas de reconhecimento facial, os cientistas de dados foram mais longe. Ao aplicar técnicas tradicionais de visão por computador e algoritmos de aprendizagem profunda, eles aperfeiçoaram o sistema de reconhecimento facial para prevenir ataques e melhorar a precisão. É assim que funciona uma tecnologia anti-spoofing facial.
Como o aprendizado profundo atualiza o software de reconhecimento facial
O aprendizado profundo é uma das formas mais inovadoras de melhorar a tecnologia de reconhecimento facial. A idéia é extrair incrustações de rostos de imagens com rostos. Tais incrustações faciais serão únicas para diferentes rostos. E o treinamento de uma rede neural profunda é a maneira mais ideal para realizar essa tarefa.
Dependente de uma tarefa e prazos, há dois métodos comuns para usar o aprendizado profundo para sistemas de reconhecimento facial:
Utilizar modelos pré-treinados tais como dlib, DeepFace, FaceNet, e outros. Este método leva menos tempo e esforço porque os modelos pré-treinados já possuem um conjunto de algoritmos para fins de reconhecimento de face. Também podemos afinar modelos pré-treinados para evitar viés e deixar o sistema de reconhecimento de face funcionar corretamente.
Desenvolver uma rede neural a partir do zero. Este método é adequado para sistemas complexos de reconhecimento de face com funcionalidade multiuso. Leva mais tempo e esforço e requer milhões de imagens no conjunto de dados de treinamento, ao contrário de um modelo pré-treinado que requer apenas milhares de imagens em caso de aprendizagem de transferência.

Mas se o sistema de reconhecimento facial incluir características únicas, pode ser uma forma ideal a longo prazo. Os pontos-chave para prestar atenção são:
- A seleção correta da arquitetura CNN e função de perda
- Otimização do tempo de detecção
- O poder de um hardware
É recomendado o uso de redes neurais convolucionais (CNN) ao desenvolver uma arquitetura de rede, pois elas provaram ser eficazes nas tarefas de reconhecimento e classificação de imagens. Para obter os resultados esperados, é melhor usar uma arquitetura de rede neural geralmente aceita como base, por exemplo, ResNet ou EfficientNet.
Ao treinar uma rede neural para fins de desenvolvimento de software de reconhecimento facial, devemos minimizar os erros na maioria dos casos. Aqui é crucial considerar as funções de perda utilizadas para o cálculo de erros entre o output real e o previsto. As funções mais comumente usadas em sistemas de reconhecimento facial são perda triplet e AM-Softmax.
- A função de perda triplet implica em ter três imagens de duas pessoas diferentes. Existem duas imagens – âncora e positiva – para uma pessoa, e a terceira – negativa – para outra pessoa. Os parâmetros de rede estão sendo aprendidos para aproximar as mesmas pessoas no espaço de recursos, e separar pessoas diferentes.
- A função softmax é uma das modificações mais recentes da função softmax padrão, que utiliza uma regularização particular baseada em uma margem aditiva. Ela permite alcançar uma melhor separabilidade das classes e, portanto, melhora a precisão do sistema de reconhecimento facial.
Também existem várias abordagens para melhorar uma rede neural. Nos sistemas de reconhecimento facial, os mais interessantes são a destilação do conhecimento, o aprendizado da transferência, a quantização e as convoluções separáveis em profundidade.
- Destilação do conhecimento envolve duas redes de tamanhos diferentes quando uma grande rede ensina sua própria variação menor. O valor chave é que, após o treinamento, a rede menor funciona mais rapidamente que a grande, dando o mesmo resultado.
- A abordagem de aprendizagem por transferência permite melhorar a precisão através do treinamento de toda a rede ou apenas de certas camadas em um conjunto de dados específico. Por exemplo, se o sistema de reconhecimento de faces tiver problemas de viés racial, podemos pegar um conjunto particular de imagens, digamos, fotos de chineses, e treinar a rede para atingir maior precisão.
- A abordagem de quantization melhora uma rede neural para atingir maior velocidade de processamento. Aproximando uma rede neural que usa números de ponto flutuante por uma rede neural de baixa largura de bit, podemos reduzir o tamanho da memória e o número de cálculos.
- Convoluções separáveis em profundidade é uma classe de camadas, que permite construir CNNs com um conjunto muito menor de parâmetros em comparação com CNNs padrão. Embora tenha um pequeno número de cálculos, esta característica pode melhorar o sistema de reconhecimento facial de modo a torná-lo adequado para aplicações de visão móvel.
O elemento-chave das tecnologias de aprendizagem profunda é a demanda por hardware de alta potência. Ao usar redes neurais profundas para o desenvolvimento de software de reconhecimento facial, o objetivo não é apenas aumentar a precisão do reconhecimento, mas também reduzir o tempo de resposta. É por isso que a GPU, por exemplo, é mais adequada para sistemas de reconhecimento de face com aprendizagem profunda do que a CPU.
Como implementamos o aplicativo de reconhecimento de face com aprendizagem profunda
Ao desenvolver o Big Brother (um aplicativo de câmera de demonstração) no MobiDev, o nosso objetivo era criar um software de verificação biométrica com streaming de vídeo em tempo real. Sendo um aplicativo de console local para Ubuntu e Raspbian, o Big Brother é escrito em Golang, e configurado com o ID da câmera local e tipo de leitor de câmera através do arquivo de configuração JSON. Este vídeo descreve como o Big Brother funciona na prática:
Do interior, o ciclo de trabalho da aplicação Big Brother compreende:
1. Detecção de rostos
O aplicativo detecta rostos em um fluxo de vídeo. Uma vez capturada a face, a imagem é cortada e enviada para o back end via HTTP form-data request. A API do back end salva a imagem em um sistema de arquivos local e salva um registro no Log de Detecção com um personID.
O back end utiliza Golang e MongoDB Collections para armazenar dados de funcionários. Todas as solicitações da API são baseadas em RESTful API.

2. Reconhecimento de face instantâneo
O back end tem um trabalhador de fundo que encontra novos registros não classificados e usa o Dlib para calcular o vetor descritor 128-dimensional de características de face. Sempre que um vector é calculado, é comparado com múltiplas imagens faciais de referência calculando a distância Euclidiana a cada vector de características de cada pessoa na base de dados, encontrando uma correspondência.
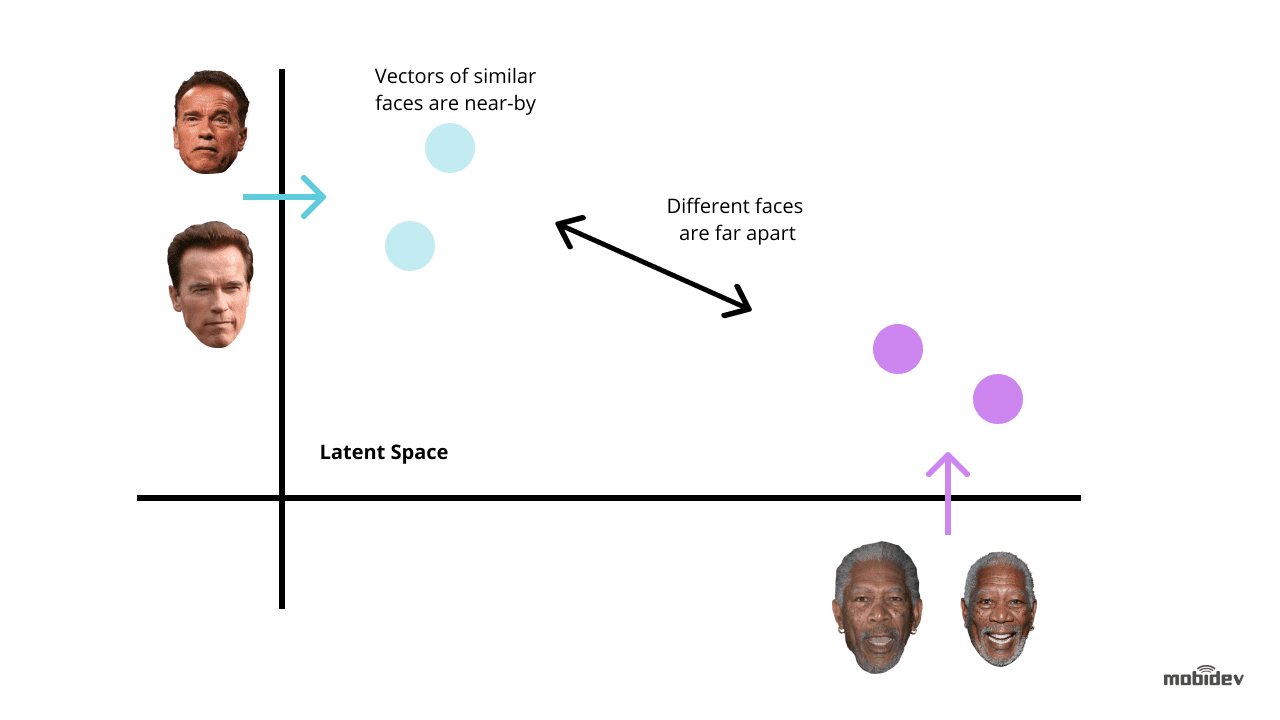
Se a distância Euclidiana à pessoa detectada for inferior a 0,6, o trabalhador define um ID de pessoa para o Registo de Detecção e marca-o como classificado. Se a distância exceder 0,6, ele cria um novo ID de pessoa para o log.
3. Ações de acompanhamento: alertas, concessão de acesso e outras
Imagens de uma pessoa não identificada são enviadas ao gerente correspondente com notificações via chatbots em mensageiros. No aplicativo Big Brother, usamos o Microsoft Bot Framework e o Errbot baseado em Python, o que nos permitiu implementar o chatbot de alerta em cinco dias.

Após isso, esses registros podem ser gerenciados através do Painel de Administração, que armazena fotos com identificações no banco de dados. O software de reconhecimento facial funciona em tempo real e realiza tarefas de reconhecimento facial instantaneamente. Utilizando Golang e MongoDB Collections para o armazenamento de dados dos funcionários, nós inserimos a base de dados de IDs, incluindo 200 entradas.
Aqui está como o aplicativo de reconhecimento de face Big Brother foi projetado:
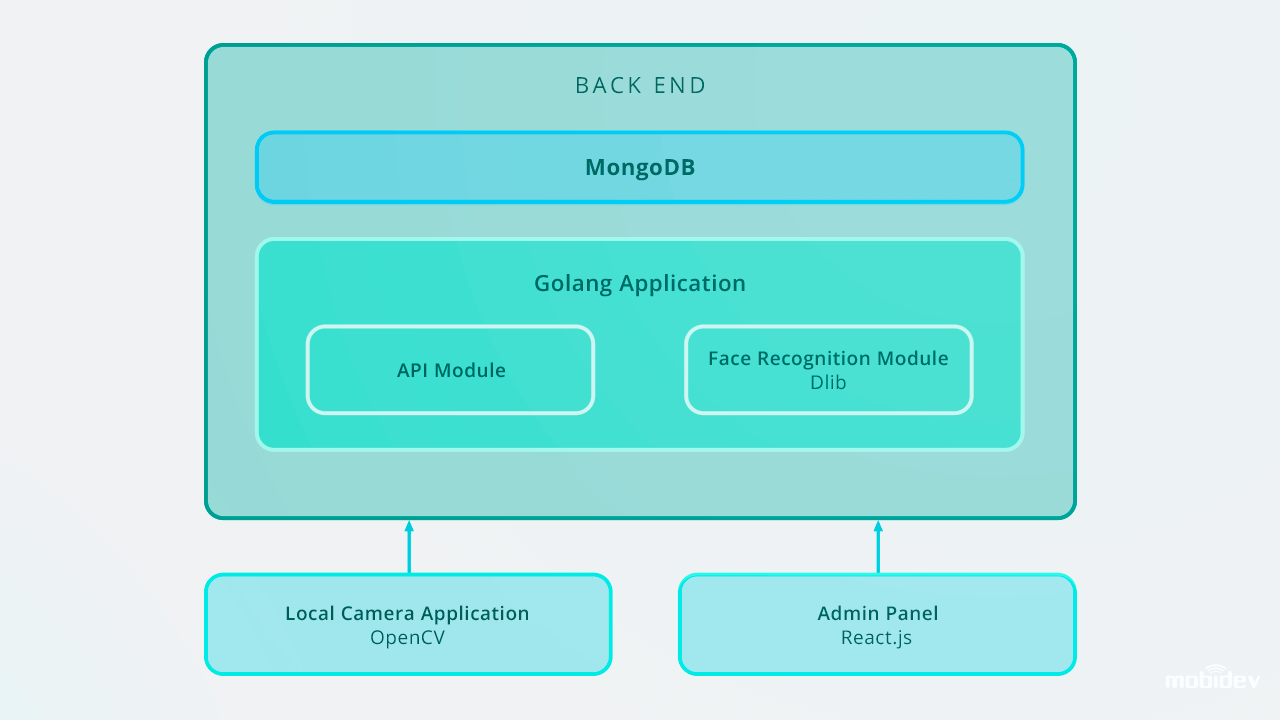
No caso de escalar até 10.000 entradas, nós recomendaríamos melhorar o sistema de reconhecimento de face a fim de manter a alta velocidade de reconhecimento no back end. Uma das formas ideais é usar a paralelização. Ao configurar um balanceador de carga e construir vários trabalhadores da web, podemos garantir o trabalho adequado de uma parte traseira e a velocidade ideal de todo um sistema.
Outros casos de uso de reconhecimento baseado em aprendizagem profunda
O reconhecimento facial não é a única tarefa onde o desenvolvimento de software baseado em aprendizagem profunda pode melhorar o desempenho. Outros exemplos incluem:
Detecção e reconhecimento facial mascarado
Desde que a COVID-19 fez com que pessoas em muitos países usassem máscaras faciais, a tecnologia de reconhecimento facial tornou-se mais avançada. Ao usar o algoritmo de aprendizado profundo baseado em redes neurais convolucionais, as câmeras agora podem reconhecer rostos cobertos com máscaras. Os engenheiros da ciência dos dados utilizam algoritmos como modelos de reconhecimento facial multigranular e periocular baseados em olhos para melhorar as capacidades do sistema de reconhecimento facial. Ao identificar características faciais como testa, contorno facial, detalhes oculares e perioculares, sobrancelhas, olhos e maçãs do rosto, esses modelos permitem o reconhecimento de rostos mascarados com até 95% de precisão.
Um bom exemplo de tal sistema é a tecnologia de reconhecimento facial criada por uma das empresas chinesas. O sistema consiste em dois algoritmos: reconhecimento facial baseado em aprendizagem profunda, e medição de temperatura de imagem térmica infravermelha. Quando pessoas com máscaras faciais ficam em frente à câmera, o sistema extrai características faciais e as compara com as imagens existentes no banco de dados. Ao mesmo tempo, o mecanismo de medição de temperatura por infravermelhos mede a temperatura, detectando assim pessoas com temperaturas anormais.
Detecção de efeitos
Nos últimos dois anos, os fabricantes têm usado a inspecção visual baseada em IA para a detecção de defeitos. O desenvolvimento de algoritmos de aprendizagem profunda permite que este sistema defina automaticamente os mais pequenos arranhões e fissuras, evitando factores humanos.
Detecção de anomalias corporais
A empresa Aidoc, sediada em Israel, desenvolveu uma solução de aprendizagem profunda para radiologia. Através da análise de imagens médicas, este sistema detecta anormalidades no peito, coluna c, cabeça e abdômen.
Identificação de falantes
Tecnologia de identificação de falantes criada pela empresa Phonexia também identifica falantes utilizando a abordagem de aprendizagem métrica. O sistema reconhece os alto-falantes por voz, produzindo modelos matemáticos de fala humana denominados impressões de voz. Essas impressões de voz são armazenadas em bancos de dados, e quando uma pessoa fala a tecnologia do alto-falante identifica a impressão de voz única.
Reconhecimento das emoções humanas
Reconhecimento das emoções humanas é uma tarefa hoje em dia exequível. Ao rastrear movimentos de um rosto através da câmera, a tecnologia de Reconhecimento de Emoções categoriza as emoções humanas. O algoritmo de aprendizagem profunda identifica pontos de referência de um rosto humano, detecta uma expressão facial neutra e mede os desvios das expressões faciais reconhecendo as mais positivas ou negativas.
Reconhecimento de ações
Visual Uma empresa, que é fornecedora de câmaras de ninho, alimentou seu produto com IA. Utilizando técnicas de aprendizagem profunda, aperfeiçoaram as câmaras de ninho para reconhecer não só diferentes objectos como pessoas, animais de estimação, carros, etc., mas também identificar acções. O conjunto de ações a serem reconhecidas é customizável e selecionado pelo usuário. Por exemplo, uma câmera pode reconhecer um gato arranhando a porta, ou uma criança brincando com o fogão.
Se quiser resumir, redes neurais profundas são uma ferramenta poderosa para a humanidade. E somente um humano decide que futuro tecnológico está por vir.
Como o aprendizado profundo pode modernizar o software de reconhecimento facial
Download PDF
>