
Como todos nós entramos no mês três da pandemia COVID-19 e procuramos novos projetos para nos manter engajados (leia: sãos), podemos lhe interessar em aprender os fundamentos do armazenamento do computador? Em silêncio nesta primavera, já revisamos alguns conceitos básicos necessários como como testar a velocidade dos seus discos e o que diabos é o RAID. Na segunda dessas histórias, nós até prometemos um acompanhamento explorando o desempenho de várias topologias de discos múltiplos no ZFS, o sistema de arquivos da próxima geração que você já ouviu falar por causa de suas aparições por toda parte, da Apple ao Ubuntu.
Bem, hoje é o dia de explorar, leitores curiosos em ZFS. Basta saber de antemão que nas palavras subestimadas do desenvolvedor do OpenZFS Matt Ahrens, “é realmente complicado”
Mas antes de chegarmos aos números – e eles estão chegando, eu prometo!-para todas as formas que você pode moldar oito discos de ZFS, precisamos falar sobre como ZFS armazena seus dados no disco em primeiro lugar.
Zpools, vdevs, e dispositivos
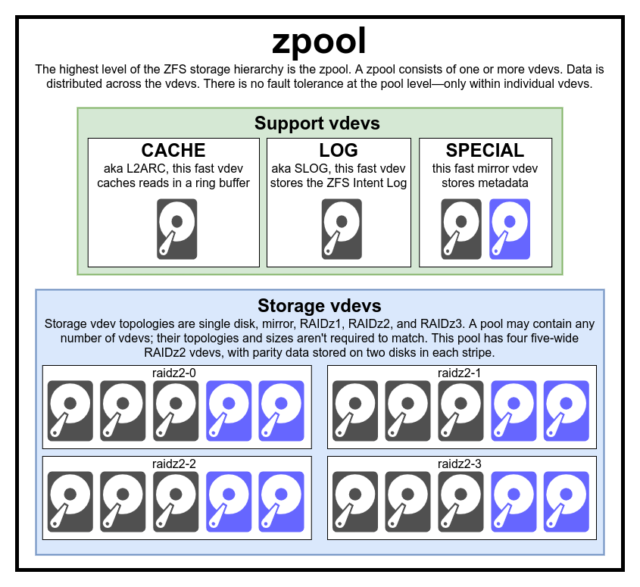

Para realmente entender ZFS, você precisa prestar atenção real à sua estrutura real. ZFS funde as camadas tradicionais de gerenciamento de volume e sistema de arquivos, e usa um mecanismo transacional de cópia-na-escrita – ambos significam que o sistema é muito diferente estruturalmente do que os sistemas de arquivos convencionais e matrizes RAID. O primeiro conjunto de blocos principais a serem entendidos são zpools, vdevs, e devices.
zpool
The zpool é a estrutura ZFS mais alta. Um zpool contém um ou mais vdevs, cada um dos quais por sua vez contém um ou mais devices. Os zpools são unidades autónomas – um computador físico pode ter dois ou mais zpools separados, mas cada um deles é totalmente independente de quaisquer outros. Zpools não podem compartilhar vdevs um com o outro.
ZFS redundância está no nível vdev, não no nível zpool. Não há absolutamente nenhuma redundância no nível do zpool – se algum armazenamento vdev ou SPECIAL vdev for perdido, todo o zpool é perdido com ele.
Os zpools modernos podem sobreviver à perda de um CACHE ou LOG vdev- embora possam perder uma pequena quantidade de dados sujos, se perderem um LOG vdev durante uma queda de energia ou falha do sistema.
É um equívoco comum que as “listras” ZFS escrevem através do pool – mas isto é impreciso. Um zpool não é um RAID0 engraçado – é um JBOD engraçado, com um mecanismo de distribuição complexo sujeito a alterações.
Para a maior parte, as escritas são distribuídas entre os vdevs disponíveis de acordo com seu espaço livre disponível, de modo que todos os vdevs teoricamente ficarão cheios ao mesmo tempo. Em versões mais recentes do ZFS, a utilização de vdevs também pode ser levada em conta – se um vdev está significativamente mais ocupado que outro (ex: devido à carga de leitura), ele pode ser pulado temporariamente para escrita apesar de ter a maior proporção de espaço livre disponível.
O mecanismo de consciência de utilização incorporado nos métodos modernos de distribuição de escrita ZFS pode diminuir a latência e aumentar a produção durante períodos de carga invulgarmente elevada – mas não deve ser confundido com carta branca para misturar discos de ferrugem lenta e SSDs rápidos intencionalmente a zero na mesma piscina. Uma piscina tão desajustada geralmente ainda terá um desempenho como se fosse inteiramente composta pelo dispositivo mais lento presente.
vdev
Cada zpool consiste em um ou mais vdevs(abreviação de dispositivo virtual). Cada vdev, por sua vez, é composto por um ou mais reais devices. A maioria dos vdevs são usados para armazenamento simples, mas várias classes especiais de suporte de vdev também existem, incluindo CACHE, LOG, e SPECIAL. Cada um destes tipos de vdevs pode oferecer uma das cinco topologias – dispositivo único, RAIDz1, RAIDz2, RAIDz3, ou espelho.
RAIDz1, RAIDz2, e RAIDz3 são variedades especiais do que as barbas cinzentas de armazenamento chamam de “paridade diagonal RAID”. O 1, 2, e 3 referem-se a quantos blocos de paridade são alocados para cada faixa de dados. Ao invés de ter discos inteiros dedicados à paridade, RAIDz vdevs distribuem essa paridade de forma semi-regular pelos discos. Um array RAIDz pode perder tantos discos quanto blocos de paridade; se perder outro, ele falha, e leva a zpool para baixo com ele.
Mirror vdevs são exatamente como eles soam – em um vdev espelho, cada bloco é armazenado em cada dispositivo no vdev. Embora dois espelhos de largura sejam os mais comuns, um espelho vdev pode conter qualquer número arbitrário de dispositivos – três-vias são comuns em configurações maiores para um maior desempenho de leitura e resistência a falhas. Um vdev espelho vdev pode sobreviver a qualquer falha, desde que pelo menos um dispositivo no vdev permaneça saudável.
Vdevs de um único dispositivo também são exatamente como eles soam – e são inerentemente perigosos. Um único dispositivo vdev não pode sobreviver a qualquer falha – e se estiver sendo usado como um armazenamento ou SPECIAL vdev, sua falha levará todo o zpool para baixo com ele. Seja muito, muito cuidadoso aqui.
CACHE, LOG, e SPECIAL vdevs podem ser criados usando qualquer uma das topologias acima – mas lembre-se, perda de um SPECIAL vdev significa perda do pool, então topologia redundante é fortemente encorajada.
device
Este é provavelmente o termo mais fácil de entender relacionado a ZFS – é literalmente apenas um dispositivo de bloco de acesso aleatório. Lembre-se, vdevs são feitos de dispositivos individuais, e o zpool é feito de vdevs.
Discos – sejam ferrugem ou de estado sólido – são os dispositivos de bloco mais comuns usados como vdev blocos de construção. Qualquer coisa com um descritor em /dev que permita acesso aleatório funcionará, embora – assim arrays RAID de hardware inteiros podem ser (e às vezes são) usados como dispositivos individuais.
O arquivo raw simples é um dos mais importantes dispositivos de bloco alternativos a partir dos quais um vdev pode ser construído. Test pools feitos de arquivos esparsos são uma maneira incrivelmente conveniente para praticar comandos zpool, e ver quanto espaço está disponível em um pool ou vdev de uma determinada topologia.

Vamos dizer que você está pensando em construir um servidor de oito baias, e com muita certeza você vai querer usar discos de 10TB (~9300 GiB) – mas você não tem certeza qual topologia melhor atende às suas necessidades. No exemplo acima, construímos um pool de teste a partir de arquivos esparsos em segundos – e agora sabemos que um vdev RAIDz2 feito de oito discos de 10TB oferece 50TiB de capacidade utilizável.
Existe uma classe especial de device–SPARE. Os dispositivos Hotspare, ao contrário dos dispositivos normais, pertencem a toda a piscina, não a um único vdev. Se algum vdev no pool sofrer uma falha no dispositivo, e um SPARE estiver anexado ao pool e disponível, o SPARE se anexará automaticamente ao degradado vdev.
>
Após anexado ao degradado vdev, o SPARE começará a receber cópias ou reconstruções dos dados que devem estar no dispositivo em falta. No RAID tradicional, isto seria chamado de “rebuild”- em ZFS, é chamado de “resilvering”
É importante notar que SPARE dispositivos não substituem permanentemente dispositivos falhos. Eles são apenas suportes de lugar, destinados a minimizar a janela durante a qual um vdev roda degradado. Uma vez que o administrador substituiu o dispositivo defeituoso do vdev e o novo dispositivo de substituição permanente de resilvers, o SPARE desliga-se do vdev, e volta ao pool-wide duty.
Datasets, blocos e setores
O próximo conjunto de blocos de construção que você precisará entender na sua jornada ZFS relaciona-se não tanto com o hardware, mas como os dados em si são organizados e armazenados. Estamos pulando alguns níveis aqui – como o metaslab – no interesse de manter as coisas o mais simples possível, enquanto ainda entendemos a estrutura geral.
Datasets
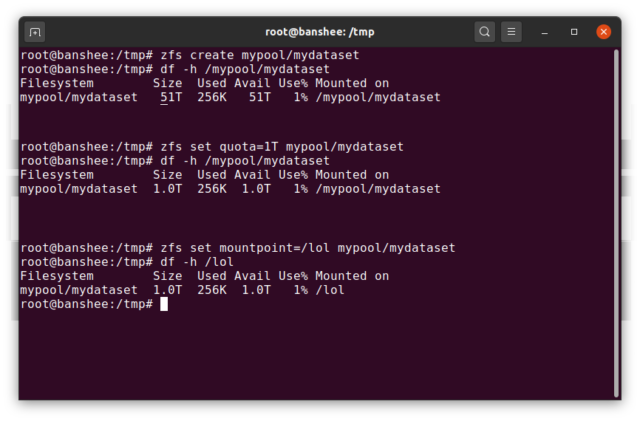

A ZFS dataset é mais ou menos análogo a um sistema de arquivos padrão, montado como um sistema de arquivos convencional, parece uma inspeção casual como se fosse “apenas outra pasta”. Mas também como um sistema de arquivos montado convencional, cada ZFS dataset tem seu próprio conjunto de propriedades subjacentes.
Primeiro e acima de tudo, um dataset pode ter uma cota atribuída a ele. Se você zfs set quota=100G poolname/datasetname, não poderá colocar mais de 100GiB de dados na pasta system mounted /poolname/datasetname.
Notificar a presença e ausência de cortes principais no exemplo acima? Cada conjunto de dados tem seu lugar tanto na hierarquia ZFS, quanto na hierarquia de montagem do sistema. Na hierarquia ZFS, não há nenhuma barra principal – você começa com o nome do conjunto de dados e, em seguida, o caminho de um conjunto de dados para o próximo ovo pool/parent/child para um conjunto de dados chamado child sob o conjunto de dados pai parent, em um conjunto de dados criativamente chamado pool.
Por padrão, o ponto de montagem de um conjunto de dados dataset será equivalente ao seu nome hierárquico ZFS, com uma barra principal – o conjunto de dados chamado pool é montado em /pool, o conjunto de dados parent é montado em /pool/parent, e o conjunto de dados filho child é montado em /pool/parent/child. O ponto de montagem do sistema de um conjunto de dados pode ser alterado, entretanto.
Se estivéssemos em zfs set mountpoint=/lol pool/parent/child, o conjunto de dados pool/parent/child seria realmente montado no sistema como /lol.
Além dos conjuntos de dados, devemos mencionar zvols. Um zvol é mais ou menos análogo a um dataset, exceto que ele não tem um sistema de arquivos nele – é apenas um dispositivo de bloco. Você poderia, por exemplo, criar um zvol chamado mypool/myzvol, depois formatá-lo com o sistema de arquivos ext4, depois montar esse sistema de arquivos – agora você tem um sistema de arquivos ext4, mas com todas as características de segurança do ZFS! Isso pode parecer bobagem em um único computador – mas faz muito mais sentido como back end para uma exportação iSCSI.
Blocks
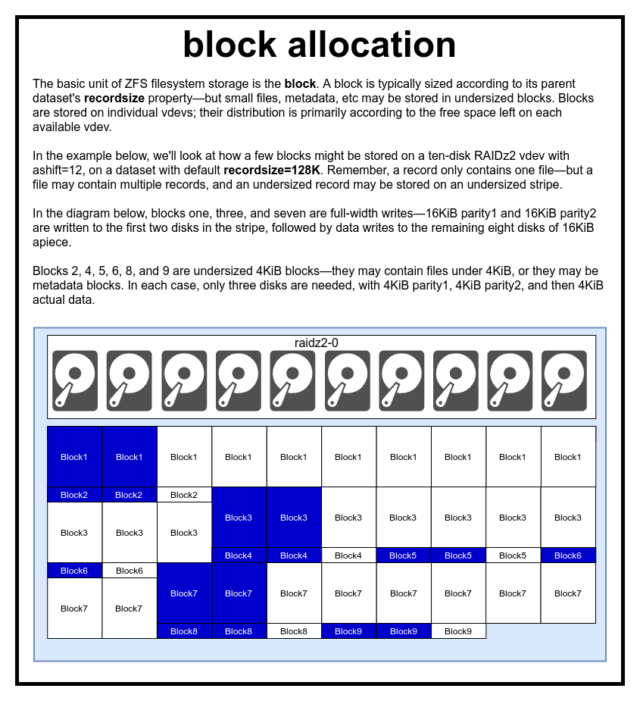

Em um pool ZFS, todos os dados, incluindo metadados, são armazenados em blocks. O tamanho máximo de um block é definido para cada dataset na propriedade recordsize. O tamanho do registro é mutável, mas alterar recordsize não irá alterar o tamanho ou layout de nenhum blocks que já tenham sido escritos no conjunto de dados apenas para novos blocos à medida que são escritos.
Se não for definido de outra forma, o padrão atual recordsize é 128KiB. Isto representa uma espécie de compromisso desconfortável no qual o desempenho não será ideal para muito de nada, mas também não será horrível para muito de nada. Recordsize pode ser definido para qualquer valor desde 4K até 1M. (Recordsize pode ser definido ainda maior com afinação adicional e determinação suficiente, mas isso raramente é uma boa ideia.)
Ainda dada block referencia dados de apenas um ficheiro – não se pode enfiar dois ficheiros separados no mesmo block. Cada ficheiro será composto por um ou mais blocks, dependendo do tamanho. Se um arquivo for menor que recordsize, ele será armazenado em um bloco subdimensionado – por exemplo, um arquivo block contendo um arquivo de 2KiB só ocupará um único 4KiB sector em disco.
Se um arquivo for grande o suficiente para requerer múltiplos blocks, todos os registros contendo esse arquivo serão recordsize em comprimento – incluindo o último registro, que pode ser na maioria das vezes pouco espaço.
Zvols não têm o recordsize propriedade-em vez disso, eles têm volblocksize, que é mais ou menos equivalente.
Sectores
O último bloco de construção a discutir é o mais baixo sector. A sector é a menor unidade física que pode ser escrita ou lida a partir do seu subjacente device. Durante várias décadas, a maioria dos discos usou 512 byte sectors. Mais recentemente, a maioria dos discos usa 4KiB sectors, e alguns – especialmente SSD- usam 8KiB sectors, ou até maiores.
ZFS tem uma propriedade que permite definir manualmente o tamanho sector, chamado ashift. Um pouco confuso, ashift é na verdade o expoente binário que representa o tamanho do setor – por exemplo, configurar ashift=9 significa que seu tamanho sector será 2^9, ou 512 bytes.
ZFS consulta o sistema operacional para obter detalhes sobre cada bloco device como é adicionado a um novo vdev, e em teoria irá automaticamente configurar ashift corretamente com base nessa informação. Infelizmente, existem muitos discos que se encontram através dos dentes sobre o seu tamanho sector, a fim de permanecer compatível com o Windows XP (que era incapaz de compreender discos com qualquer outro tamanho sector).
Isto significa que um administrador ZFS é fortemente aconselhado a estar ciente do tamanho real sector do seu devices, e definir manualmente ashift em conformidade. Se ashift for definido muito baixo, uma penalidade astronômica de amplificação de leitura/escrita é incorrida – escrever um “setores” de 512 bytes para um real de 4KiB sector significa ter que escrever o primeiro “setor”, então leia o 4KiB sector, modifique-o com o segundo “setor” de 512 bytes, escreva-o novamente para um *novo* 4KiB sector, e assim por diante, para cada escrita.
Em termos reais, esta penalidade de amplificação atinge um Samsung EVO SSD – que deveria ter ashift=13, mas mente sobre seu tamanho de setor e, portanto, o padrão é ashift=9 se não for anulado por um administrador experiente o suficiente para fazê-lo parecer mais lento que um disco de ferrugem convencional.
Pelo contrário, não há praticamente nenhuma penalidade para definir ashift muito alto. Não há penalidade de desempenho real, e os aumentos de espaço frouxo são infinitesimais (ou zero, com compressão ativada). Nós recomendamos fortemente que até mesmo discos que realmente usam setores de 512 bytes sejam configurados ashift=12 ou até mesmo ashift=13 para a prova de futuro.
A propriedade ashift é per-vdev-não por piscina, como é comum e erroneamente pensado!-e é imutável, uma vez configurada. Se você acidentalmente flubular ashift ao adicionar um novo vdev a uma piscina, você contaminou irrevogavelmente essa piscina com um desempenho drasticamente inferior a vdev, e geralmente não tem outro recurso senão destruir a piscina e começar de novo. Mesmo vdev remoção não pode salvá-lo de um flubbed ashift ajuste!
Copy-on-Write semantics




CoW-Copy on Write-é um suporte fundamental abaixo da maioria do que torna o ZFS impressionante. O conceito básico é simples – se você pedir a um sistema de arquivos tradicional para modificar um arquivo no local, ele faz exatamente o que você pediu. Se você pedir a um sistema de arquivos copy-on-write para fazer a mesma coisa, ele diz “ok” – mas está mentindo para você.
Em vez disso, o sistema de arquivos copy-on-write escreve uma nova versão do block que você modificou, então atualiza os metadados do arquivo para desvincular o antigo block, e liga o novo block que você acabou de escrever.
Alterar o antigo block e ligar no novo é feito em uma única operação, então não pode ser interrompido – se você despejar a energia depois de acontecer, você tem a nova versão do arquivo, e se você despejar a energia antes, então você tem a versão antiga. Você é sempre consistente com o sistema de arquivos, de qualquer forma.
Copy-on-write em ZFS não é apenas no nível do sistema de arquivos, é também no nível de gerenciamento de disco. Isto significa que o buraco RAID – uma condição na qual uma faixa é apenas parcialmente escrita antes do sistema travar, tornando o array inconsistente e corrompido após um reinício – não afeta o ZFS. As escritas em stripe são atômicas, o vdev é sempre consistente, e Bob é seu tio.
ZIL- o Log de Intenção ZFS
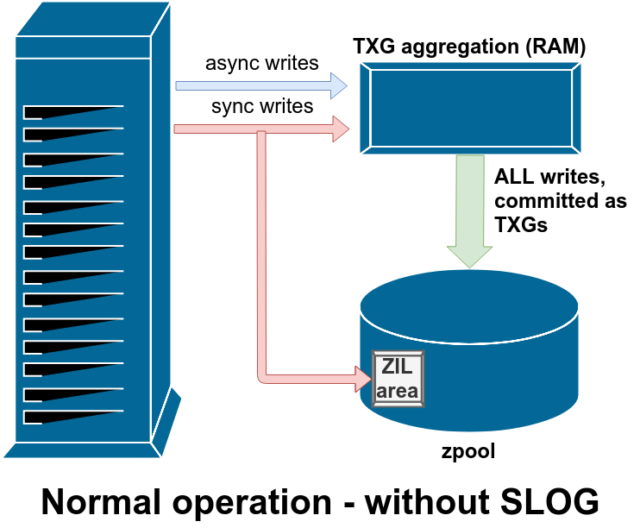

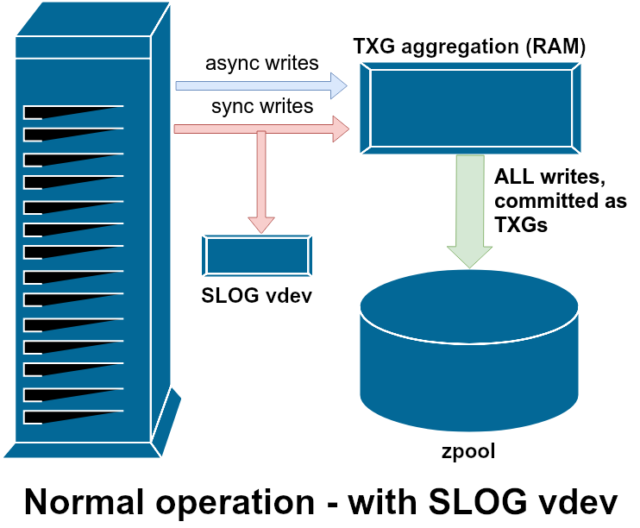

Existem duas categorias principais de operações de escrita – assíncrona (sync) e assíncrona (async). Para a maioria das cargas de trabalho, a grande maioria das operações de escrita são assíncronas – o sistema de arquivos é permitido agregá-las e submetê-las em lotes, reduzindo a fragmentação e aumentando tremendamente a produção.
Sync writes são um animal totalmente diferente – quando uma aplicação solicita uma escrita sincronizada, ela está dizendo ao sistema de arquivos “você precisa submetê-la a um armazenamento não volátil agora, e até que você o faça, eu não posso fazer mais nada”. Sync writes devem ser submetidos ao disco imediatamente – e se isso aumentar a fragmentação ou diminuir a produção, assim seja.
ZFS lida com a sincronização escreve de forma diferente dos sistemas de arquivos normais – em vez de descarregar a sincronização escreve para o armazenamento normal imediatamente, ZFS os submete para uma área especial de armazenamento chamada ZFS Intent Log, ou ZIL. O truque aqui é que essas gravações também permanecem na memória, sendo agregadas juntamente com as solicitações de gravação assíncrona normal, para mais tarde serem descarregadas para o armazenamento como TXGs (Grupos de Transação) perfeitamente normais. Quando as escritas gravadas na ZIL são comprometidas com o armazenamento principal da RAM em TXGs normais alguns momentos depois, elas são desvinculadas da ZIL. A única vez que a ZIL é lida é na importação do pool.
Se a ZFS falhar – ou se o sistema operacional falhar, ou se houver uma queda de energia – enquanto houver dados na ZIL, esses dados serão lidos durante a próxima importação do pool (por exemplo, quando um sistema falhar for reiniciado). O que quer que esteja na ZIL será lido, agregado em TXGs, comprometido com o armazenamento principal e depois desvinculado da ZIL durante o processo de importação.
Uma das classes de suporte vdev disponível é LOG–tão conhecida como SLOG, ou dispositivo LOG secundário. Tudo o que a SLOG faz é prover a piscina com um separado – e esperançosamente muito mais rápido, com alta resistência de escrita –vdev para armazenar o ZIL em, ao invés de manter o ZIL no armazenamento principal vdevs. Em todos os aspectos, o ZIL comporta-se da mesma forma, seja no armazenamento principal, ou em um LOG vdev-mas se o LOG vdev tem um desempenho de escrita muito alto, então os retornos de escrita sincronizados acontecerão muito rapidamente.
Adicionando um LOG vdev a um pool absolutamente não pode e não irá melhorar diretamente a performance de escrita assíncrona – mesmo se você forçar todas as escritas na ZIL usando zfs set sync=always, elas ainda se comprometem com o armazenamento principal em TXGs da mesma forma e no mesmo ritmo que teriam sem o LOG. As únicas melhorias de desempenho direto são para a latência de escrita síncrona (já que a maior velocidade do LOG permite que o sync volte mais rápido).
No entanto, em um ambiente que já requer muitas escritas sincronizadas, um LOG vdev pode acelerar indiretamente as escritas assíncronas e leituras em cache também. Descarregar ZIL escreve em um separado LOG vdev significa menos contenção para IOPS no armazenamento primário, aumentando assim a performance para todas as leituras e escritas em algum grau.
Snapshots
Copy-on-write semantics também são a base necessária para os snapshots atômicos de ZFS e replicação assíncrona incremental. O sistema de arquivos live tem uma árvore de ponteiros marcando todos os records que contêm dados atuais quando você tira uma foto, você simplesmente faz uma cópia dessa árvore de ponteiros.
Quando um registro é sobrescrito no sistema de arquivos live, ZFS escreve a nova versão do block para o espaço não utilizado primeiro. Em seguida ele desabilita a versão antiga do block a partir do sistema de arquivos atual. Mas se algum snapshot faz referência ao antigo block, ele ainda permanece imutável. O antigo block não será recuperado como espaço livre até que todos os snapshots referenciem que block foram destruídos!
Replicação

 Uma vez que você entenda como os instantâneos funcionam, você está em um bom lugar para entender a replicação. Como um instantâneo é simplesmente uma árvore de apontadores para
Uma vez que você entenda como os instantâneos funcionam, você está em um bom lugar para entender a replicação. Como um instantâneo é simplesmente uma árvore de apontadores pararecords, segue-se que se nószfs sendum instantâneo, estamos a enviar tanto essa árvore como todos os registos associados. Quando canalizamos issozfs sendpara umzfs receiveno alvo, ele escreve tanto o conteúdo real deblock, como a árvore de ponteiros referenciando oblocks, no conjunto de dados do alvo.
As coisas ficam mais interessantes no seu segundo zfs send. Agora que você tem dois sistemas, cada um contendo o snapshot poolname/datasetname@1, você pode tirar um novo snapshot, poolname/datasetname@2. Então no pool de fontes, você tem datasetname@1 e datasetname@2, e no pool de destino, até agora você só tem o primeiro snapshot-datasetname@1.
Desde que temos um snapshot comum entre o fonte e o destino-datasetname@1– podemos construir um incremental zfs send em cima dele. Quando pedimos ao sistema para zfs send -i poolname/datasetname@1 poolname/datasetname@2, ele compara as duas árvores ponteiro. Quaisquer apontadores que existam apenas em @2 obviamente referenciam novos blocks– então precisaremos do conteúdo daqueles blocks também.
No sistema remoto, piping no incremental resultante send é similarmente fácil. Primeiro, nós escrevemos todos os novos records incluídos no fluxo send, depois adicionamos nos ponteiros aqueles blocks. Presto, temos @2 no novo sistema!
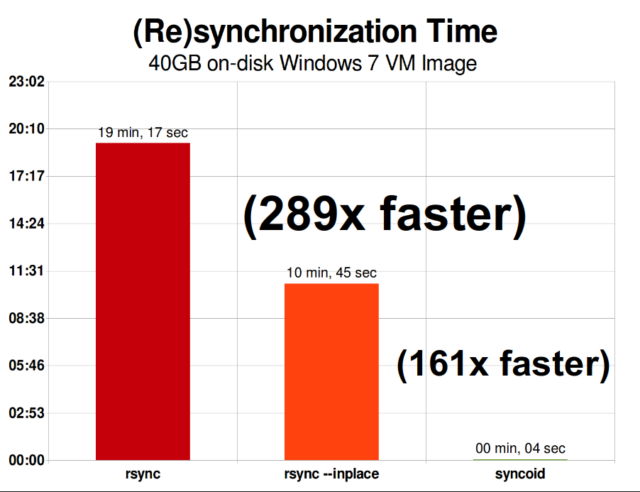
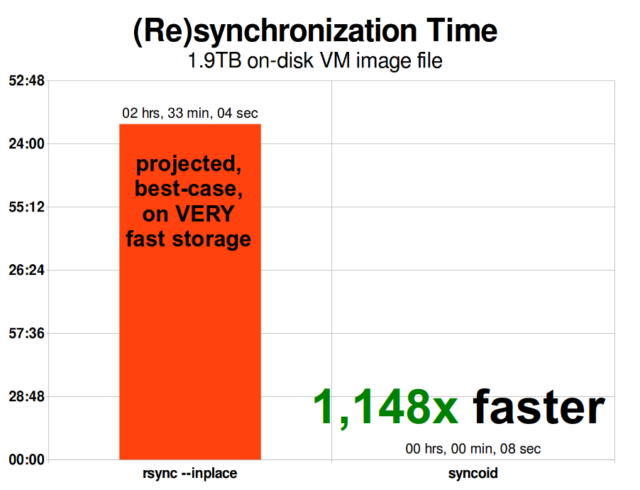
ZFS a replicação incremental assíncrona é uma enorme melhoria em relação a técnicas anteriores, não baseadas em instantâneos, como rsync. Em ambos os casos, apenas os dados alterados precisam ser enviados através do fio – mas rsync precisa primeiro ler todos os dados do disco, em ambos os lados, para poder verificar e comparar o checksum. Em contraste, a replicação ZFS não precisa ler nada além das árvores de ponteiro – e qualquer blocks que a árvore de ponteiro contenha que ainda não estavam presentes no snapshot comum.
Compressão em linha
Copy-on-write semantics também facilita a compressão em linha. Com um sistema de arquivos tradicional oferecendo modificação no local, a compressão é problemática – tanto a versão antiga quanto a nova versão dos dados modificados devem caber exatamente no mesmo espaço.
Se considerarmos um pedaço de dados no meio de um arquivo que começa a vida útil como 1MiB de zeros-0x00000000 ad nauseam- ele se comprimiria até um único setor do disco muito facilmente. Mas o que acontece se substituirmos esse 1MiB de zeros por 1MiB de dados incompressíveis, tais como JPEG ou ruído pseudo-aleatória? De repente, esse 1MiB de dados precisa de 256 sectores de 4KiB, não apenas um – e o buraco no meio do ficheiro é apenas um sector de largura.
ZFS não tem este problema, uma vez que os registos modificados são sempre escritos em espaço não utilizado – o original block ocupa apenas um único 4KiB sector, e o novo registo ocupa 256 deles, mas isso não é um problema – o pedaço recentemente modificado do “meio” do ficheiro teria sido escrito em espaço não utilizado quer o seu tamanho fosse alterado ou não, por isso para ZFS, este “problema” é apenas mais um dia no escritório.
A compressão em linha do ZFS está desligada por padrão, e oferece algoritmos plugáveis – atualmente incluindo LZ4, gzip (1-9), LZJB, e ZLE.
- LZ4 é um algoritmo de fluxo que oferece compressão e descompressão extremamente rápidas, e é um ganho de performance para a maioria dos casos de uso – mesmo com CPUs muito anêmicas.
- GZIP é o venerável algoritmo que todos os usuários do tipo Unix conhecem e adoram. Ele pode ser implementado com níveis de compressão 1-9, com aumento da taxa de compressão e uso de CPU à medida que os níveis se aproximam de 9. Gzip pode ser uma vitória para todos os casos de uso de texto (ou extremamente compressível), mas freqüentemente resulta em gargalos de CPU de uso diferente com cautela, particularmente em níveis mais altos.
- LZJB é o algoritmo original usado pelo ZFS. Ele é depreciado, e não deve mais ser usado – LZ4 é superior em todas as métricas.
- ZLE é Codificação de Nível Zero – ele deixa os dados normais sozinhos por completo, mas comprime grandes seqüências de zeros. Útil para conjuntos de dados totalmente incompressíveis (ex. JPEG, MP4, ou outros formatos já comprimidos), uma vez que ignora os dados incompressíveis, mas comprime pouco espaço nos registros finais.
Recomendamos a compressão LZ4 para praticamente qualquer caso de uso concebível; a penalidade de desempenho quando encontra dados incompressíveis é muito pequena, e o ganho de desempenho para dados típicos é significativo. Copiar uma imagem VM para uma nova instalação do sistema operacional Windows (apenas o sistema operacional Windows instalado, sem dados sobre ele ainda) foi 27% mais rápido com compression=lz4 do que compression=none neste teste de 2015.
ARC-o Cache de Substituição Adaptativa
ZFS é o único sistema de arquivos moderno que conhecemos que usa seu próprio mecanismo de cache de leitura, em vez de confiar no cache de páginas do seu sistema operacional para manter cópias de blocos recentemente lidos na RAM para ele.
Embora o mecanismo de cache separado tenha seus problemas-ZFS não pode reagir a novas requisições para alocar memória tão imediatamente quanto o kernel pode, e portanto uma nova chamada mallocate() pode falhar, se precisar de RAM atualmente ocupada pelo ARC – há uma boa razão, pelo menos por enquanto, para aturá-lo.
Todos os sistemas operacionais modernos bem conhecidos – incluindo MacOS, Windows, Linux e BSD – utilizam o algoritmo LRU (Menos Usado Recentemente) para sua implementação de cache de páginas. A LRU é um algoritmo ingênuo que coloca um bloco em cache até o “topo” da fila cada vez que é lido, e despeja blocos do “fundo” da fila conforme necessário para adicionar novas falhas de cache (blocos que tiveram que ser lidos do disco, ao invés de cache) no “topo”.”
Até aqui tudo bem, mas em sistemas com grandes conjuntos de dados em funcionamento, a LRU pode facilmente acabar por “bater” – evitando blocos muito frequentemente necessários, para criar espaço para blocos que nunca mais serão lidos da cache.
O ARC é um algoritmo muito menos ingénuo, que pode ser pensado como uma cache “ponderada”. Cada vez que um bloco em cache é lido, torna-se um pouco mais “pesado” e mais difícil de despejar – e mesmo depois de um despejo, o bloco despejado é rastreado por um período de tempo. Um bloco que foi despejado mas que depois deve ser lido de volta para o cache também se tornará “mais pesado” e mais difícil de despejar.
O resultado final de tudo isto é um cache com rácios de acerto tipicamente muito maiores – o rácio entre acertos (leituras servidas a partir do cache) e falhas no cache (leituras servidas a partir do disco). Esta é uma estatística extremamente importante – não apenas o cache é servido em ordens de magnitude mais rapidamente, mas também as falhas de cache podem ser servidas mais rapidamente, já que mais falhas de cache===menos pedidos simultâneos ao disco=== latência mais baixa para as falhas restantes que devem ser servidas a partir do disco.
Conclusão
Agora já cobrimos a semântica básica do ZFS – como funciona a copy-on-write, e as relações entre pools, vdevs, blocos, setores e arquivos – estamos prontos para falar do desempenho real, com números reais.
Fique ligado para a próxima parcela da nossa série de fundamentos de armazenamento para ver o desempenho real visto em pools usando vdevs de mirror e RAIDz, em comparação com as topologias tradicionais de RAID do kernel Linux que exploramos anteriormente.
Inicialmente, vamos apenas cobrir o básico – as próprias topologias ZFS – mas depois disso, estaremos prontos para falar sobre configuração e ajuste mais avançado de ZFS, incluindo o uso de tipos de suporte vdevs como L2ARC, SLOG e Special Allocation.