
În timp ce intrăm cu toții în luna a treia a pandemiei COVID-19 și căutăm noi proiecte care să ne țină ocupați (a se citi: sănătoși la cap), putem să vă interesăm să învățați elementele fundamentale ale stocării pe calculator? În liniște în această primăvară, am trecut deja în revistă câteva noțiuni de bază necesare, cum ar fi cum să testați viteza discurilor și ce naiba este RAID. În cel de-al doilea dintre aceste articole, am promis chiar și o continuare care să exploreze performanța diferitelor topologii de discuri multiple în ZFS, sistemul de fișiere de ultimă generație despre care ați auzit din cauza aparițiilor sale peste tot, de la Apple la Ubuntu.
Bine, astăzi este ziua în care trebuie să explorați, cititori curioși de ZFS. Doar să știți de la început că, în cuvintele subînțelese ale dezvoltatorului OpenZFS Matt Ahrens, „este foarte complicat.”
Dar înainte de a ajunge la cifre – și ele vin, promit!-pentru toate modurile în care puteți modela ZFS în valoare de opt discuri, trebuie să vorbim, în primul rând, despre modul în care ZFS vă stochează datele pe disc.
Zpools, vdevs și dispozitive
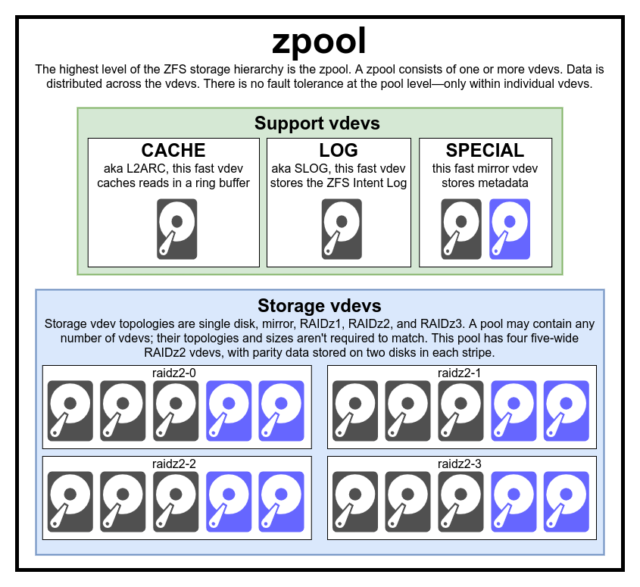

Pentru a înțelege cu adevărat ZFS, trebuie să acordați o atenție reală structurii sale reale. ZFS îmbină straturile tradiționale de gestionare a volumelor și de sistem de fișiere și utilizează un mecanism tranzacțional de copiere la scriere – ambele înseamnă că sistemul este foarte diferit din punct de vedere structural față de sistemele de fișiere convenționale și de matricele RAID. Primul set de blocuri de construcție majore care trebuie înțelese sunt zpools, vdevs și devices.
zpool
zpool este cea mai înaltă structură ZFS. Un zpool conține unul sau mai multe vdevs, fiecare dintre acestea conținând la rândul său unul sau mai multe devices. Zpools sunt unități de sine stătătoare – un computer fizic poate avea două sau mai multe zpools separate pe el, dar fiecare este complet independent de celelalte. Zpools nu pot împărți vdevs între ele.
Redundanța ZFS este la nivelul vdev, nu la nivelul zpool. Nu există absolut nicio redundanță la nivel de zpool – dacă orice vdev de stocare vdev sau SPECIAL se pierde, întregul zpool se pierde odată cu el.
Zpools moderne pot supraviețui pierderii unui CACHE sau LOG vdev – deși pot pierde o cantitate mică de date murdare, dacă pierd un LOG vdev în timpul unei pene de curent sau a unei căderi de sistem.
Este o concepție greșită comună că ZFS „stripează” scrierile în cadrul pool-ului – dar acest lucru este inexact. Un zpool nu este un RAID0 cu aspect amuzant – este un JBOD cu aspect amuzant, cu un mecanism complex de distribuție supus schimbării.
În cea mai mare parte, scrierile sunt distribuite pe vdev-urile disponibile în funcție de spațiul liber disponibil, astfel încât toate vdev-urile vor deveni teoretic pline în același timp. În versiunile mai recente ale ZFS, utilizarea vdev-urilor poate fi, de asemenea, luată în considerare – dacă un vdev este semnificativ mai ocupat decât altul (de exemplu: din cauza încărcării de citire), acesta poate fi sărit temporar pentru scriere, în ciuda faptului că are cel mai mare raport de spațiu liber disponibil.
Mecanismul de conștientizare a utilizării încorporat în metodele moderne de distribuire a scrierilor ZFS poate reduce latența și poate crește debitul în timpul perioadelor de încărcare neobișnuit de mare – dar nu trebuie confundat cu o carte albă pentru a amesteca discuri lente cu rugină și SSD-uri rapide în mod voit sau nu în același pool. Un astfel de pool nepotrivit va continua să funcționeze, în general, ca și cum ar fi compus în întregime din cel mai lent dispozitiv prezent.
vdev
Care zpool este format din unul sau mai multe vdevs(prescurtare de la dispozitiv virtual). Fiecare vdev, la rândul său, este format din unul sau mai multe devices reale. Cele mai multe vdev-uri sunt folosite pentru stocare simplă, dar există și câteva clase speciale de suport pentru vdev – inclusiv CACHE, LOG și SPECIAL. Fiecare dintre aceste tipuri de vdev-uri poate oferi una dintre cele cinci topologii – un singur dispozitiv, RAIDz1, RAIDz2, RAIDz3 sau oglindă.
RAIDz1, RAIDz2 și RAIDz3 sunt varietăți speciale a ceea ce cărturarii în materie de stocare numesc „RAID cu paritate diagonală”. 1, 2 și 3 se referă la câte blocuri de paritate sunt alocate pentru fiecare bandă de date. În loc de a avea discuri întregi dedicate parității, vdev-urile RAIDz distribuie această paritate în mod semi-egal pe discuri. O matrice RAIDz poate pierde atâtea discuri câte blocuri de paritate are; dacă mai pierde încă unul, cedează și duce zpool în jos cu el.
Vdev-urile în oglindă sunt exact ceea ce sună – într-un vdev în oglindă, fiecare bloc este stocat pe fiecare dispozitiv din vdev. Deși oglinzile cu două lățimi sunt cele mai comune, un vdev în oglindă poate conține orice număr arbitrar de dispozitive – cele cu trei căi sunt comune în configurațiile mai mari pentru performanța mai mare de citire și rezistența la erori. Un vdev în oglindă poate supraviețui oricărei defecțiuni, atâta timp cât cel puțin un dispozitiv din vdev rămâne sănătos.
Vdev-urile cu un singur dispozitiv sunt, de asemenea, exact ceea ce par a fi – și sunt în mod inerent periculoase. Un vdev cu un singur dispozitiv nu poate supraviețui oricărei defecțiuni – și dacă este folosit ca vdev de stocare sau SPECIAL vdev, defecțiunea sa va duce întregul zpool în jos cu el. Fiți foarte, foarte atenți aici.
CACHE, LOG și SPECIAL vdevs pot fi create folosind oricare dintre topologiile de mai sus – dar nu uitați, pierderea unui SPECIAL vdev înseamnă pierderea pool-ului, astfel încât topologia redundantă este puternic încurajată.
device
Acesta este probabil cel mai ușor de înțeles termen legat de ZFS – este literalmente doar un dispozitiv de bloc cu acces aleatoriu. Amintiți-vă, vdevs sunt formate din dispozitive individuale, iar zpool este format din vdevs.
Discurile – fie ruginite, fie în stare solidă – sunt cele mai comune dispozitive de bloc utilizate ca blocuri de construcție vdev. Cu toate acestea, orice lucru cu un descriptor în /dev care permite accesul aleatoriu va funcționa – astfel încât array-uri hardware RAID întregi pot fi (și uneori sunt) folosite ca dispozitive individuale.
Fișierul brut simplu este unul dintre cele mai importante dispozitive bloc alternative din care poate fi construit un vdev. Pool-urile de test realizate din fișiere rare sunt o modalitate incredibil de convenabilă de a exersa comenzile zpool și de a vedea cât spațiu este disponibil pe un pool sau vdev de o anumită topologie.

Să spunem că vă gândiți să construiți un server cu opt bay-uri și sunteți destul de sigur că veți dori să folosiți discuri de 10TB (~9300 GiB) – dar nu sunteți sigur ce topologie se potrivește cel mai bine nevoilor dumneavoastră. În exemplul de mai sus, construim un pool de testare din fișiere rare în câteva secunde – și acum știm că un vdev RAIDz2 format din opt discuri de 10TB oferă 50TiB de capacitate utilizabilă.
Există o clasă specială de device – SPARE. Dispozitivele Hotspare, spre deosebire de dispozitivele normale, aparțin întregului pool, nu unui singur vdev. Dacă orice vdev din pool suferă o defecțiune a unui dispozitiv, iar un SPARE este atașat la pool și este disponibil, SPARE se va atașa automat la vdev degradat.
După ce este atașat la vdev degradat, SPARE începe să primească copii sau reconstrucții ale datelor care ar trebui să se afle pe dispozitivul lipsă. În RAID tradițional, acest lucru s-ar numi „reconstrucție” – în ZFS, se numește „resilverizare.”
Este important să rețineți că dispozitivele SPARE nu înlocuiesc permanent dispozitivele defecte. Ele sunt doar niște înlocuitori, menite să minimizeze fereastra în timpul căreia un vdev rulează degradat. Odată ce administratorul a înlocuit dispozitivul defectuos al vdev-ului și noul dispozitiv de înlocuire permanentă se resilitează, SPARE se detașează de vdev și se întoarce la datoria de la nivelul întregului pool.
Dataset-uri, blocuri și sectoare
Următorul set de elemente de construcție pe care va trebui să le înțelegeți în călătoria dvs. în ZFS se referă nu atât de mult la hardware, cât la modul în care datele în sine sunt organizate și stocate. Vom sări peste câteva niveluri aici – cum ar fi metaslab – în interesul de a păstra lucrurile cât mai simple posibil, înțelegând în același timp structura generală.
Datasets
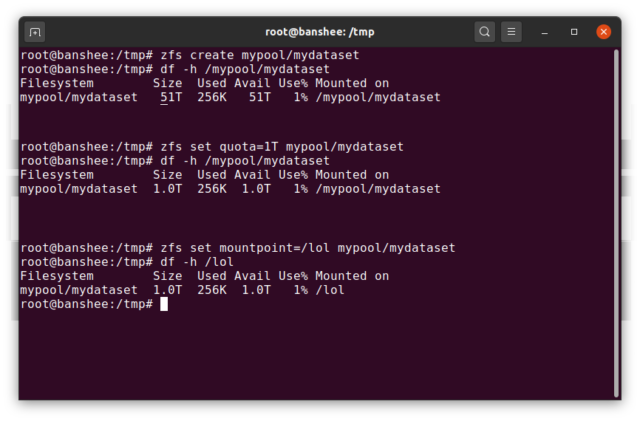

Un ZFS dataset este aproximativ analog cu un sistem de fișiere standard, montat – ca un sistem de fișiere convențional, apare la o inspecție ocazională ca și cum ar fi „doar un alt dosar”. Dar, de asemenea, la fel ca și sistemele de fișiere convenționale montate, fiecare ZFS dataset are propriul set de proprietăți de bază.
În primul rând, un dataset poate avea o cotă care să-i fie atribuită. Dacă zfs set quota=100G poolname/datasetname, nu veți putea pune mai mult de 100GiB de date în dosarul montat în sistem /poolname/datasetname.
Observați prezența – și absența – slash-urilor de început în exemplul de mai sus? Fiecare set de date își are locul său atât în ierarhia ZFS, cât și în ierarhia de montare în sistem. În ierarhia ZFS, nu există nici o bară oblică de început – începeți cu numele pool-ului și apoi cu calea de la un set de date la următorul – de exemplu pool/parent/child pentru un set de date numit child sub setul de date părinte parent, într-un pool numit în mod creativ pool.
În mod implicit, punctul de montare al unui dataset va fi echivalent cu numele său ierarhic ZFS, cu o bară oblică la început – pool-ul numit pool este montat la /pool, setul de date parent este montat la /pool/parent, iar setul de date copil child este montat la /pool/parent/child. Cu toate acestea, punctul de montare în sistem al unui set de date poate fi modificat.
Dacă ar fi să zfs set mountpoint=/lol pool/parent/child, setul de date pool/parent/child ar fi de fapt montat pe sistem ca /lol.
Pe lângă seturile de date, ar trebui să menționăm zvols. Un zvol este aproximativ analog cu un dataset, cu excepția faptului că nu are de fapt un sistem de fișiere în el – este doar un dispozitiv de bloc. Ați putea, de exemplu, să creați un zvol numit mypool/myzvol, apoi să îl formatați cu sistemul de fișiere ext4, apoi să montați acel sistem de fișiere – acum aveți un sistem de fișiere ext4, dar susținut de toate caracteristicile de siguranță ale ZFS! Acest lucru ar putea părea o prostie pe un singur calculator – dar are mult mai mult sens ca back-end pentru un export iSCSI.
Blocuri
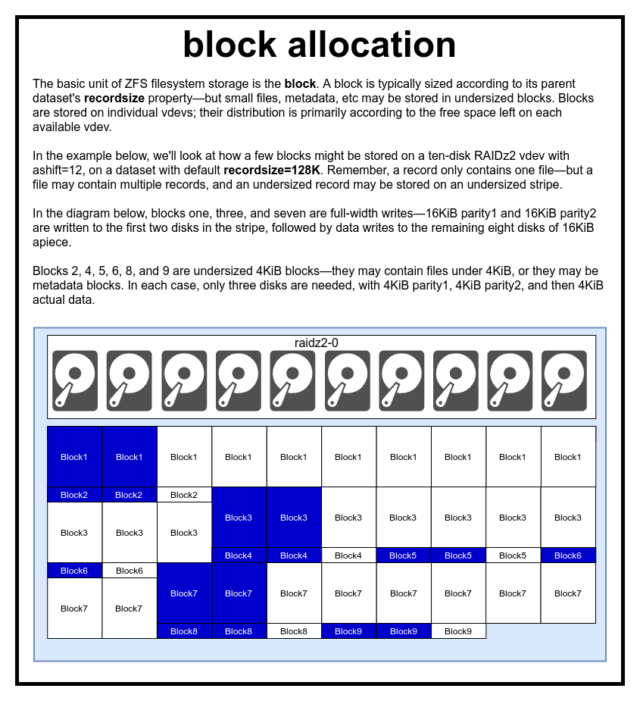

Într-un pool ZFS, toate datele – inclusiv metadatele – sunt stocate în blocks. Dimensiunea maximă a unui block este definită pentru fiecare dataset în proprietatea recordsize. Recordsize este mutabilă, dar modificarea recordsize nu va schimba dimensiunea sau aspectul niciunui blocks care a fost deja scris în setul de date – doar pentru blocurile noi, pe măsură ce sunt scrise.
Dacă nu este definit altfel, valoarea implicită actuală a recordsize este de 128KiB. Acest lucru reprezintă un fel de compromis incomod în care performanța nu va fi ideală pentru aproape nimic, dar nici nu va fi îngrozitoare pentru aproape nimic. Recordsize poate fi setat la orice valoare de la 4K la 1M. ( poate fi setat chiar mai mare cu un reglaj suplimentar și suficientă determinare, dar aceasta este rareori o idee bună.)
Care block dat face referire la date dintr-un singur fișier – nu puteți înghesui două fișiere separate în același block. Fiecare fișier va fi compus din unul sau mai multe blocks, în funcție de dimensiune. Dacă un fișier este mai mic de recordsize, acesta va fi stocat într-un bloc subdimensionat – de exemplu, un block care conține un fișier de 2KiB va ocupa doar un singur sector de 4KiB pe disc.
Dacă un fișier este suficient de mare pentru a necesita mai multe blocks, toate înregistrările care conțin acel fișier vor avea o lungime de recordsize – inclusiv ultima înregistrare, care poate fi în mare parte spațiu liber.
Zvols nu au proprietatea recordsize – în schimb, au volblocksize, ceea ce este aproximativ echivalent.
Sectoare
Ultimul element de construcție care trebuie discutat este micul sector. Un sector este cea mai mică unitate fizică care poate fi scrisă sau citită din device care îi stă la bază. Timp de câteva decenii, majoritatea discurilor au folosit sectors de 512 octeți. Mai recent, majoritatea discurilor utilizează sectors de 4KiB, iar unele – în special SSD-urile – utilizează sectors de 8KiB, sau chiar mai mari.
ZFS are o proprietate care vă permite să setați manual dimensiunea sector, numită ashift. În mod oarecum confuz, ashift este de fapt exponentul binar care reprezintă dimensiunea sectorului – de exemplu, dacă setați ashift=9 înseamnă că dimensiunea sector va fi 2^9, sau 512 octeți.
ZFS interoghează sistemul de operare pentru detalii despre fiecare bloc device pe măsură ce este adăugat la un nou vdev și, în teorie, va seta automat ashift în mod corespunzător pe baza acestor informații. Din nefericire, există multe discuri care mint cu nerușinare cu privire la dimensiunea sector, pentru a rămâne compatibile cu Windows XP (care era incapabil să înțeleagă discurile cu orice altă dimensiune sector).
Aceasta înseamnă că un administrator ZFS este recomandat cu tărie să fie conștient de dimensiunea reală sector a devices sa și să seteze manual ashift în consecință. Dacă ashift este setat prea mic, se înregistrează o penalizare astronomică de amplificare a citirii/scrierii – scrierea unui „sector” de 512 octeți pe un sector real de 4KiB înseamnă că trebuie să scrie primul „sector”, apoi să citească sector de 4KiB, să-l modifice cu al doilea „sector” de 512 octeți, să-l scrie din nou pe un *nou* sector de 4KiB, și așa mai departe, pentru fiecare scriere în parte.
În termeni din lumea reală, această penalizare de amplificare lovește un SSD Samsung EVO – care ar trebui să aibă ashift=13, dar minte cu privire la dimensiunea sectorului său și, prin urmare, setează implicit ashift=9 dacă nu este anulat de un administrator priceput – suficient de tare pentru a-l face să pară mai lent decât un disc de rugină convențional.
În schimb, nu există practic nicio penalizare pentru setarea ashift prea mare. Nu există o penalizare reală a performanței, iar creșterile de spațiu liber sunt infinitezimale (sau zero, cu compresia activată). Recomandăm cu insistență ca până și discurile care folosesc cu adevărat sectoare de 512 octeți să fie setate ashift=12 sau chiar ashift=13 pentru siguranță în viitor.
Proprietatea ashift este per-vdev-nu per pool, așa cum se crede în mod obișnuit și eronat!-și este imuabilă, odată setată. Dacă, din greșeală, greșești ashift atunci când adaugi un nou vdev la un pool, ai contaminat irevocabil acel pool cu un vdev drastic neperformant și, în general, nu ai altă cale de atac decât să distrugi pool-ul și să o iei de la capăt. Nici măcar eliminarea vdev nu vă poate salva de o setare ashift greșită!
Semantica Copy-on-Write




CoW-Copy on Write-este o bază fundamentală sub cea mai mare parte a ceea ce face ca ZFS să fie minunat. Conceptul de bază este simplu – dacă cereți unui sistem de fișiere tradițional să modifice un fișier pe loc, acesta face exact ceea ce i-ați cerut. Dacă îi cereți unui sistem de fișiere cu copiere la scriere să facă același lucru, acesta spune „bine” – dar vă minte.
În schimb, sistemul de fișiere cu copiere la scriere scrie o nouă versiune a block pe care ați modificat-o, apoi actualizează metadatele fișierului pentru a dezlipi vechiul block și a lega noul block pe care tocmai l-ați scris.
Deconectarea vechiului block și conectarea noului este realizată într-o singură operațiune, astfel încât nu poate fi întreruptă – dacă descărcați curentul după ce se întâmplă, veți avea noua versiune a fișierului, iar dacă descărcați curentul înainte, veți avea versiunea veche. Sunteți întotdeauna consecvent cu sistemul de fișiere, în orice caz.
Copierea la scriere în ZFS nu este doar la nivelul sistemului de fișiere, ci și la nivelul de gestionare a discului. Acest lucru înseamnă că gaura RAID – o condiție în care o bandă este scrisă doar parțial înainte ca sistemul să se prăbușească, ceea ce face ca matricea să fie inconsistentă și coruptă după un restart – nu afectează ZFS. Scrierile pe bandă sunt atomice, vdev-ul este întotdeauna consistent, iar Bob este unchiul tău.
ZIL-the ZFS Intent Log


Există două categorii majore de operații de scriere – sincronă (sync) și asincronă (async). Pentru cele mai multe sarcini de lucru, marea majoritate a operațiunilor de scriere sunt asincrone – sistemului de fișiere i se permite să le agregheze și să le comande în loturi, reducând fragmentarea și crescând extraordinar de mult randamentul.
Scrierile sincronizate sunt un animal complet diferit – atunci când o aplicație solicită o scriere sincronizată, aceasta îi spune sistemului de fișiere „trebuie să comanzi acest lucru în memoria nevolatilă acum, iar până când nu faci acest lucru, nu pot face nimic altceva”. Scrierile de sincronizare trebuie, prin urmare, să fie trimise imediat pe disc – și dacă acest lucru crește fragmentarea sau scade randamentul, așa să fie.
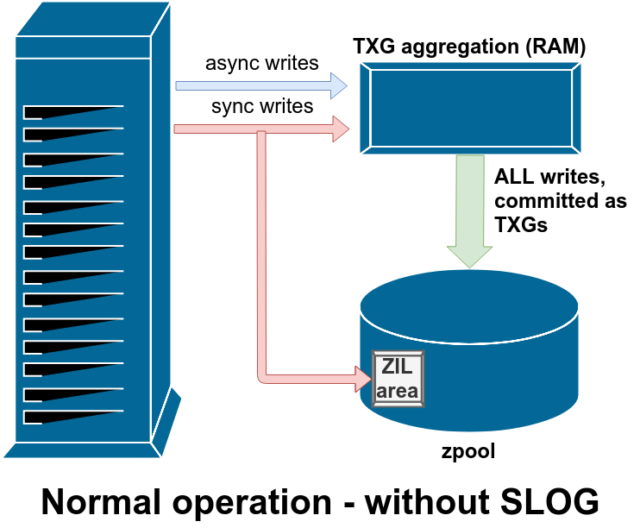
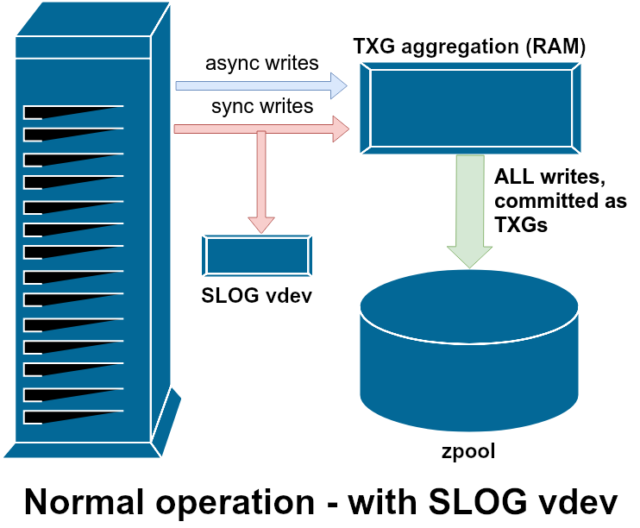
ZFS gestionează scrierile de sincronizare în mod diferit față de sistemele de fișiere normale – în loc să arunce imediat scrierile de sincronizare în memoria normală, ZFS le trimite într-o zonă de stocare specială numită ZFS Intent Log, sau ZIL. Șmecheria aici este că aceste scrieri rămân, de asemenea, în memorie, fiind agregate împreună cu cererile normale de scriere asincronă, pentru a fi mai târziu eliminate în spațiul de stocare ca TXG-uri (Transaction Groups) perfect normale.
În timpul funcționării normale, ZIL este scrisă în ZIL și nu mai este citită niciodată. Atunci când scrierile salvate în ZIL sunt trimise în memoria principală din RAM în TXG-uri normale câteva momente mai târziu, acestea sunt dezlegate de ZIL. Singurul moment în care ZIL este citit din ZIL este la importul pool-ului.
Dacă ZFS se blochează – sau sistemul de operare se blochează, sau există o pană de curent netransmisă – în timp ce există date în ZIL, aceste date vor fi citite în timpul următorului import al pool-ului (de exemplu, când un sistem blocat este repornit). Tot ceea ce se află în ZIL va fi citit, agregat în TXG-uri, trimis în memoria principală și apoi dezlegat din ZIL în timpul procesului de import.
Una dintre clasele de suport vdev disponibile este LOG-cunoscută și ca SLOG, sau dispozitiv LOG secundar. Tot ceea ce face SLOG este să ofere pool-ului un vdev separat – și se speră că mult mai rapid, cu o rezistență foarte mare la scriere –vdev în care să stocheze ZIL, în loc să păstreze ZIL pe stocarea principală vdevs. Din toate punctele de vedere, ZIL se comportă la fel indiferent dacă se află pe stocarea principală sau pe un vdev LOG – dar dacă vdev-ul LOG are o performanță de scriere foarte mare, atunci revenirile de sincronizare a scrierilor vor avea loc foarte repede.
Adăugarea unui LOG vdev LOG la un pool absolut nu poate îmbunătăți și nu va îmbunătăți în mod direct performanța scrierilor asincrone – chiar dacă forțați toate scrierile în ZIL folosind zfs set sync=always, acestea continuă să fie trimise pe stocarea principală în TXG-uri în același mod și în același ritm în care ar fi făcut-o fără LOG. Singurele îmbunătățiri directe ale performanței sunt pentru latența scrierilor sincrone (deoarece viteza mai mare a LOG permite apelului sync să se întoarcă mai repede).
Cu toate acestea, într-un mediu care necesită deja o mulțime de scrieri sincrone, un vdev LOG poate accelera indirect și scrierile asincrone și citirile fără memorie cache. Descărcarea scrierilor ZIL pe un LOG vdev separat înseamnă mai puțină concurență pentru IOPS pe stocarea primară, crescând astfel performanța pentru toate citirile și scrierile într-o oarecare măsură.
Snapshots
Semantica de copiere la scriere este, de asemenea, fundamentul necesar pentru snapshot-urile atomice și replicarea asincronă incrementală a ZFS. Sistemul de fișiere live are un arbore de pointeri care marchează toate records care conțin date curente – atunci când faceți un instantaneu, pur și simplu faceți o copie a acestui arbore de pointeri.
Când o înregistrare este suprascrisă în sistemul de fișiere live, ZFS scrie mai întâi noua versiune a block în spațiul neutilizat. Apoi, el dezleagă vechea versiune a block din sistemul de fișiere curent. Dar dacă orice snapshot face referire la vechiul block, acesta rămâne în continuare imuabil. Vechiul block nu va fi de fapt recuperat ca spațiu liber până când toate snapshots care fac referire la acel block nu vor fi distruse!
Replicare

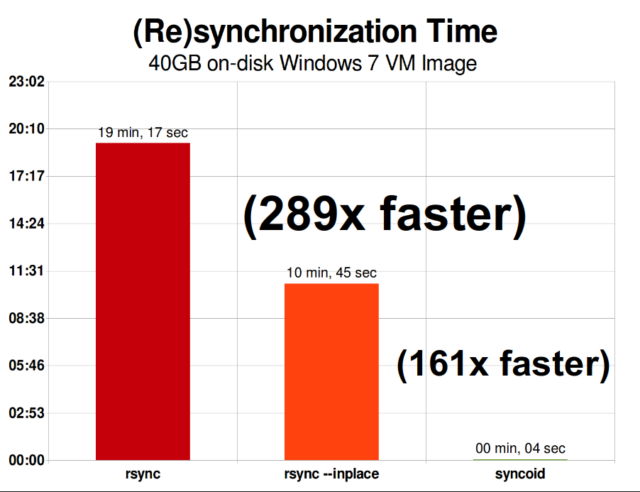
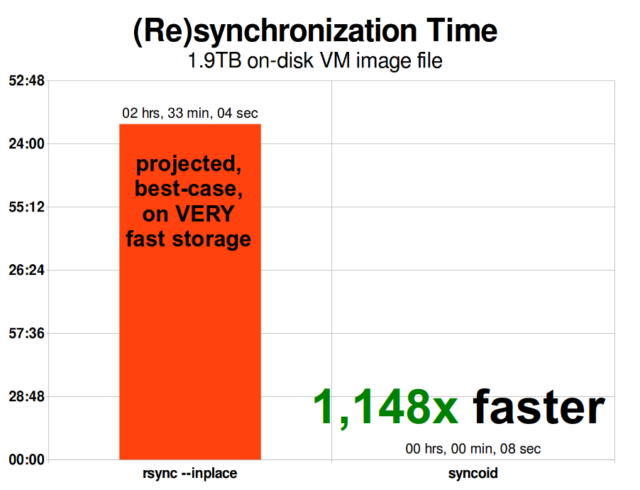 Odată ce ați înțeles cum funcționează instantaneele, sunteți într-o poziție bună pentru a înțelege replicarea. Deoarece un instantaneu este pur și simplu un arbore de pointeri la
Odată ce ați înțeles cum funcționează instantaneele, sunteți într-o poziție bună pentru a înțelege replicarea. Deoarece un instantaneu este pur și simplu un arbore de pointeri la records, rezultă că dacă zfs send un instantaneu, trimitem atât acel arbore, cât și toate înregistrările asociate. Când direcționăm acel zfs send către un zfs receive de pe țintă, acesta scrie în setul de date țintă atât conținutul real al block, cât și arborele de pointeri care fac referire la blocks.
Lucrurile devin mai interesante la al doilea zfs send. Acum că aveți două sisteme, fiecare conținând instantaneul poolname/datasetname@1, puteți face un nou instantaneu, poolname/datasetname@2. Așadar, pe fondul sursă, aveți datasetname@1 și datasetname@2, iar pe fondul țintă, până acum aveți doar primul instantaneu – datasetname@1.
Din moment ce avem un instantaneu comun între sursă și destinație – datasetname@1 – putem construi un zfs send incremental peste acesta. Când cerem sistemului să zfs send -i poolname/datasetname@1 poolname/datasetname@2, acesta compară cei doi arbori de pointeri. Orice pointeri care există doar în @2 fac în mod evident referire la noul blocks – deci vom avea nevoie și de conținutul acelor blocks.
Pe sistemul de la distanță, introducerea send incremental rezultat este la fel de ușoară. Mai întâi, scriem toate noile records incluse în fluxul send, apoi adăugăm indicatorii către acele blocks. Presto, avem @2 pe noul sistem!
Replicarea incrementală asincronă ZFS este o îmbunătățire enormă față de tehnicile anterioare, care nu se bazează pe instantanee, cum ar fi rsync. În ambele cazuri, doar datele modificate trebuie să fie trimise pe fir – dar rsync trebuie mai întâi să citească toate datele de pe disc, de ambele părți, pentru a le verifica și compara. În schimb, replicarea ZFS nu trebuie să citească nimic altceva decât arborele de pointeri – și orice blocks pe care arborele de pointeri îl conține și care nu era deja prezent în instantaneul comun.
Compresie în linie
Semantica de copiere la scriere facilitează, de asemenea, oferirea compresiei în linie. Cu un sistem de fișiere tradițional care oferă modificarea pe loc, compresia este problematică – atât versiunea veche, cât și noua versiune a datelor modificate trebuie să încapă exact în același spațiu.
Dacă luăm în considerare o bucată de date din mijlocul unui fișier care își începe viața ca 1MiB de zerouri-0x00000000 ad nauseam – s-ar comprima foarte ușor până la un singur sector de disc. Dar ce se întâmplă dacă înlocuim acel 1MiB de zerouri cu 1MiB de date incompresibile, cum ar fi JPEG sau zgomot pseudo-aleatoriu? Dintr-o dată, acel 1MiB de date are nevoie de 256 de sectoare de 4KiB, nu doar de unul singur, iar gaura din mijlocul fișierului are o lățime de doar un sector.
ZFS nu are această problemă, deoarece înregistrările modificate sunt întotdeauna scrise în spațiul nefolosit – block originalul ocupă doar un singur sector de 4KiB, iar noua înregistrare ocupă 256 de sectoare, dar aceasta nu este o problemă – bucata nou modificată din „mijlocul” fișierului ar fi fost scrisă în spațiul nefolosit indiferent dacă dimensiunea sa s-ar fi schimbat sau nu, astfel încât pentru ZFS, această „problemă” este doar o altă zi la birou.
Compresia inline a ZFS este dezactivată în mod implicit și oferă algoritmi care pot fi conectați – incluzând în prezent LZ4, gzip (1-9), LZJB și ZLE.
- LZ4 este un algoritm de flux care oferă o compresie și decompresie extrem de rapidă și este un câștig de performanță pentru majoritatea cazurilor de utilizare – chiar și cu procesoare foarte anemice.
- GZIP este venerabilul algoritm pe care toți utilizatorii de tip Unix îl cunosc și îl iubesc. Acesta poate fi implementat cu niveluri de compresie 1-9, cu un raport de compresie și o utilizare a CPU în creștere pe măsură ce nivelurile se apropie de 9. Gzip poate fi un câștig pentru cazurile de utilizare de tip „all-text” (sau extrem de compresibile în alt mod), dar, în caz contrar, duce frecvent la blocaje CPU – utilizați cu prudență, în special la niveluri mai ridicate.
- LZJB este algoritmul original utilizat de ZFS. Este depreciat și nu ar trebui să mai fie utilizat – LZ4 este superior din toate punctele de vedere.
- ZLE este Zero Level Encoding – lasă datele normale în întregime în pace, dar va comprima secvențe mari de zerouri. Utile pentru seturi de date complet incompresibile (de exemplu, JPEG, MP4 sau alte formate deja comprimate), deoarece ignoră datele incompresibile, dar comprimă spațiul liber de pe înregistrările finale.
Recomandăm compresia LZ4 pentru aproape orice caz de utilizare imaginabil; penalizarea performanței atunci când întâlnește date incompresibile este foarte mică, iar câștigul de performanță pentru datele obișnuite este semnificativ. Copierea unei imagini VM pentru o nouă instalare a unui sistem de operare Windows (doar sistemul de operare Windows instalat, fără date pe el încă) s-a desfășurat cu 27% mai rapid cu compression=lz4 decât cu compression=none în acest test din 2015.
ARC-the Adaptive Replacement Cache
ZFS este singurul sistem de fișiere modern pe care îl cunoaștem care utilizează propriul mecanism de cache de citire, în loc să se bazeze pe cache-ul de pagină al sistemului de operare pentru a păstra în RAM copii ale blocurilor citite recent pentru el.
Deși mecanismul de cache separat are problemele sale – ZFS nu poate reacționa la noile cereri de alocare a memoriei la fel de imediat cum o poate face nucleul și, prin urmare, un nou apel mallocate() poate eșua, dacă ar avea nevoie de memoria RAM ocupată în prezent de ARC – există un motiv bun, cel puțin pentru moment, pentru a-l suporta.
Toate sistemele de operare moderne cunoscute – inclusiv MacOS, Windows, Linux și BSD – utilizează algoritmul LRU (Least Recently Used) pentru implementarea cache-ului de pagină. LRU este un algoritm naiv care urcă un bloc din cache în „partea de sus” a cozii de fiecare dată când este citit și evacuează blocurile din „partea de jos” a cozii, după cum este necesar, pentru a adăuga noi ratări ale cache-ului (blocuri care au trebuit să fie citite de pe disc, mai degrabă decât din cache) în „partea de sus”.”
Acest lucru este în regulă în măsura în care merge, dar în sistemele cu seturi mari de date de lucru, LRU poate ajunge cu ușurință să „thrashing”-evacuarea blocurilor foarte frecvent necesare, pentru a face loc unor blocuri care nu vor mai fi citite niciodată din memoria cache.
ARC este un algoritm mult mai puțin naiv, care poate fi considerat ca o memorie cache „ponderată”. De fiecare dată când un bloc din cache este citit, acesta devine puțin mai „greu” și mai dificil de evitat – și chiar și după o evacuare, blocul evacuat este urmărit pentru o perioadă de timp. Un bloc care a fost evacuat, dar care apoi trebuie să fie citit din nou în memoria cache va deveni, de asemenea, mai „greu” și mai dificil de evacuat.
Rezultatul final al tuturor acestor lucruri este o memorie cache cu rate de accesare de obicei mult mai mari – raportul dintre accesările în memorie cache (citiri efectuate din memorie cache) și ratările în memorie cache (citiri efectuate de pe disc). Aceasta este o statistică extrem de importantă – nu numai că hiturile din cache sunt servite cu câteva ordine de mărime mai rapid, dar și ratările din cache pot fi, de asemenea, servite mai rapid, deoarece mai multe hituri din cache = mai puține cereri simultane pe disc = latență mai mică pentru ratările rămase care trebuie servite de pe disc.
Concluzie
Acum că am acoperit semantica de bază a ZFS – cum funcționează copy-on-write și relațiile dintre pool-uri, vdev-uri, blocuri, sectoare și fișiere – suntem gata să vorbim despre performanța reală, cu numere reale.
Rămâneți pe recepție pentru următorul episod al seriei noastre de fundamente de stocare pentru a vedea performanța reală observată în pool-uri care utilizează vdev-uri în oglindă și RAIDz, în comparație atât între ele, cât și cu topologiile RAID tradiționale ale kernelului Linux pe care le-am explorat mai devreme.
În primă fază, vom acoperi doar elementele de bază – topologiile ZFS în sine – dar, după aceea, vom fi gata să vorbim despre configurarea și reglarea mai avansată a ZFS, inclusiv despre utilizarea tipurilor de vdev de suport, cum ar fi L2ARC, SLOG și Special Allocation.