
När vi alla går in i månad tre av COVID-19-pandemin och letar efter nya projekt för att hålla oss sysselsatta (läs: friska), kan vi intressera dig för att lära dig grunderna i datorlagring? I lugn och ro under våren har vi redan gått igenom några nödvändiga grunder som hur man testar hastigheten på sina diskar och vad i helvete RAID är. I den andra av dessa berättelser lovade vi till och med en uppföljning där vi utforskade prestandan hos olika topologier med flera diskar i ZFS, nästa generations filsystem som ni har hört talas om på grund av att det dyker upp överallt från Apple till Ubuntu.
Ja, i dag är det dags att utforska, ZFS-nyfikna läsare. Men vet på förhand att med OpenZFS-utvecklaren Matt Ahrens understrukna ord: ”Det är verkligen komplicerat.”
Men innan vi kommer till siffrorna – och de kommer, det lovar jag!-för alla sätt som du kan forma åtta diskar av ZFS, måste vi prata om hur ZFS lagrar dina data på disken till att börja med.
Zpools, vdevs och enheter
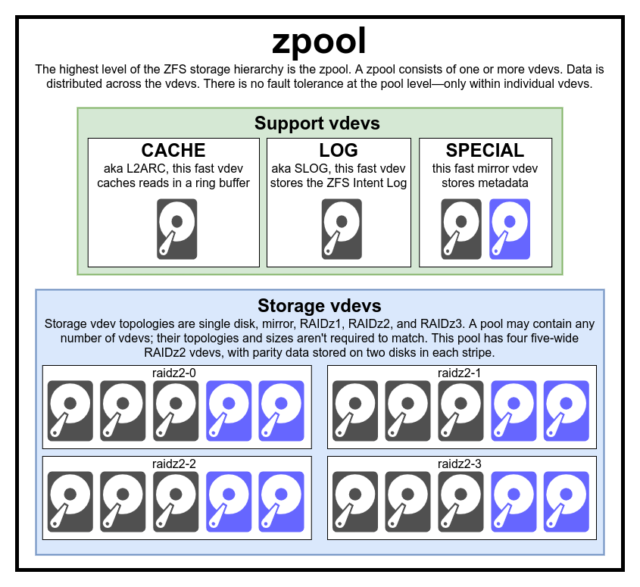

För att verkligen förstå ZFS måste du ägna riktig uppmärksamhet åt dess faktiska struktur. ZFS slår samman de traditionella lagren för volymhantering och filsystem, och det använder en transaktionsmekanism för kopiering vid skrivning – båda dessa faktorer innebär att systemet skiljer sig strukturellt mycket från konventionella filsystem och RAID-matriser. Den första uppsättningen större byggstenar att förstå är zpools, vdevs och devices.
zpool
zpool är den översta ZFS-strukturen. En zpool innehåller en eller flera vdevs som i sin tur innehåller en eller flera devices. Zpooler är fristående enheter – en fysisk dator kan ha två eller flera separata zpooler på sig, men var och en är helt oberoende av alla andra. Zpooler kan inte dela vdevs med varandra.
ZFS-redundans finns på vdev-nivån, inte zpool-nivån. Det finns absolut ingen redundans på zpoolnivå – om någon vdev eller SPECIAL vdev för lagring försvinner, försvinner hela zpool med den.
Moderna zpooler kan överleva förlusten av en CACHE eller LOG vdev – även om de kan förlora en liten mängd smutsiga data, om de förlorar en LOG vdev under ett strömavbrott eller en systemkrasch.
Det är ett vanligt missförstånd att ZFS ”stripar” skrivningar över poolen – men detta är felaktigt. En zpool är inte en lustig RAID0- det är en lustig JBOD, med en komplex fördelningsmekanism som kan ändras.
För det mesta fördelas skrivningar över tillgängliga vdevs i enlighet med deras tillgängliga lediga utrymme, så att alla vdevs teoretiskt sett kommer att bli fulla vid samma tidpunkt. I nyare versioner av ZFS kan även vdev-utnyttjande beaktas – om en vdev är betydligt mer upptagen än en annan (t.ex. på grund av läslast) kan den tillfälligt hoppas över för skrivning trots att den har det högsta förhållandet av tillgängligt ledigt utrymme.
Mekanismen för medvetenhet om utnyttjandet som är inbyggd i moderna skrivfördelningsmetoder i ZFS kan minska latenstiden och öka genomströmningen under perioder med ovanligt hög belastning – men den bör inte förväxlas med en carte blanche för att blanda långsamma rostdiskar och snabba SSD-diskar godtyckligt i samma pool. En sådan missanpassad pool kommer fortfarande i allmänhet att prestera som om den helt och hållet bestod av den långsammaste enheten som är närvarande.
vdev
Varje zpool består av en eller flera vdevs(förkortning för virtuell enhet). Varje vdev består i sin tur av en eller flera riktiga devices. De flesta vdev:er används för vanlig lagring, men det finns också flera speciella stödklasser av vdev:er – däribland CACHE, LOG och SPECIAL. Var och en av dessa vdev-typer kan erbjuda en av fem topologier – single-device, RAIDz1, RAIDz2, RAIDz3 eller mirror.
RAIDz1, RAIDz2 och RAIDz3 är särskilda varianter av det som lagringsgråsossar kallar ”diagonal parity RAID”. 1, 2 och 3 hänvisar till hur många paritetsblock som tilldelas varje datastripe. I stället för att ha hela diskar dedikerade till paritet fördelar RAIDz-vdevs pariteten halvt jämnt över diskarna. En RAIDz-array kan förlora lika många diskar som den har paritetsblock; om den förlorar ytterligare en disk går den sönder och tar zpool med sig.
Spegelvdevs är precis vad de låter som – i en spegelvdev lagras varje block på varje enhet i vdeven. Även om två breda speglar är vanligast kan en mirror vdev innehålla ett godtyckligt antal enheter – trevägsspeglar är vanliga i större konfigurationer på grund av den högre läsprestandan och felresistensen. En mirror vdev kan överleva vilket fel som helst, så länge minst en enhet i vdev:n är frisk.
Single-device vdevs är också precis vad de låter som – och de är i sig farliga. En vdev med en enda enhet kan inte överleva något fel – och om den används som en lagrings- eller SPECIAL vdev kommer felet att dra med sig hela zpool. Var mycket, mycket försiktig här.
CACHE, LOG och SPECIAL vdevs kan skapas med någon av ovanstående topologier – men kom ihåg att förlust av en SPECIAL vdev innebär förlust av poolen, så en redundant topologi uppmuntras starkt.
device
Det här är troligen den enklaste ZFS-relaterade termen att förstå – det är bokstavligen bara en blockenhet med slumpmässig åtkomst. Kom ihåg att vdevs består av enskilda enheter och zpool består av vdevs.
Diskar – antingen rost eller solid-state – är de vanligaste blockenheterna som används som vdev byggblock. Allt med en deskriptor i /dev som tillåter slumpmässig åtkomst fungerar dock – hela RAID-arrayer av hårdvara kan användas (och används ibland) som enskilda enheter.
Den enkla råfilen är en av de viktigaste alternativa blockenheterna som en vdev kan byggas upp utifrån. Testpooler gjorda av sparade filer är ett otroligt bekvämt sätt att öva på zpool-kommandon och se hur mycket utrymme som finns tillgängligt på en pool eller vdev med en viss topologi.

Säg att du funderar på att bygga en server med åtta fack och är ganska säker på att du vill använda diskar på 10 TB (~9300 GiB), men du är inte säker på vilken topologi som bäst passar dina behov. I exemplet ovan bygger vi en testpool av sparse-filer på några sekunder – och nu vet vi att en RAIDz2-vdev som består av åtta 10 TB-diskar erbjuder 50 TiB användbar kapacitet.
Det finns en speciell klass av device – SPARE. Hotspare-enheter tillhör till skillnad från vanliga enheter hela poolen, inte en enskild vdev. Om någon vdev i poolen drabbas av ett enhetsfel och en SPARE är ansluten till poolen och tillgänglig, kommer SPARE automatiskt att ansluta sig till den nedbrutna vdev.
När den väl är ansluten till den nedbrutna vdev börjar SPARE ta emot kopior eller rekonstruktioner av de data som borde finnas på den saknade enheten. I traditionell RAID skulle detta kallas ”rekonstruktion” – i ZFS kallas det ”resilvering”.
Det är viktigt att notera att SPARE-enheter inte permanent ersätter misslyckade enheter. De är bara platshållare, avsedda att minimera det fönster under vilket en vdev körs försämrad. När administratören har ersatt vdev-enhetens misslyckade enhet och den nya, permanenta ersättningsenheten återställs, kopplar SPARE av sig själv från vdev-enheten och återgår till pool-wide-tjänstgöring.
Dataset, block och sektorer
Nästa uppsättning byggstenar som du behöver förstå på din ZFS-resa har inte så mycket med hårdvaran att göra, utan med hur själva datan är organiserad och lagrad. Vi hoppar över några nivåer här – t.ex. metaslab – för att hålla det så enkelt som möjligt och ändå förstå den övergripande strukturen.
Datasets
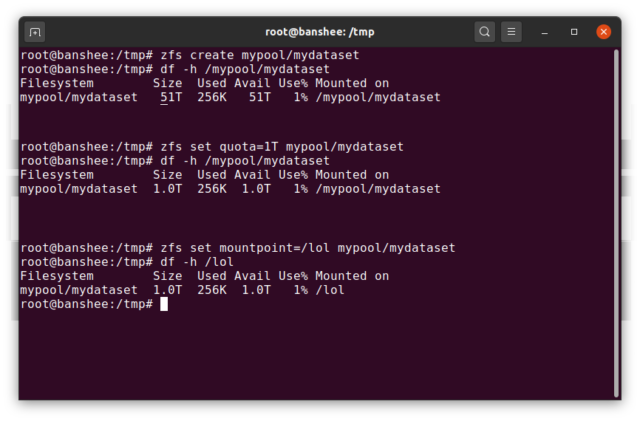

En ZFS dataset motsvarar i stort sett ett vanligt, monterat filsystem – som ett konventionellt filsystem ser det vid en tillfällig inspektion ut som om det är ”bara en mapp till”. Men precis som konventionella monterade filsystem har varje ZFS dataset en egen uppsättning underliggande egenskaper.
Först och främst kan en dataset ha tilldelats en kvot. Om du zfs set quota=100G poolname/datasetname kommer du inte att kunna lägga mer än 100 GB data i den systemmonterade mappen /poolname/datasetname.
Märker du närvaron – och frånvaron – av ledande snedstreck i exemplet ovan? Varje dataset har sin plats i både ZFS-hierarkin och systemmonteringshierarkin. I ZFS-hierarkin finns det inget ledande snedstreck – du börjar med poolens namn och sedan sökvägen från en datauppsättning till nästa – t.ex. pool/parent/child för en datauppsättning som heter child under den överordnade datauppsättningen parent, i en pool med det kreativa namnet pool.
Som standard kommer monteringspunkten för en dataset att motsvara dess ZFS-hierarkiska namn, med ett inledande snedstreck – poolen som heter pool är monterad på /pool, dataset parent är monterad på /pool/parent och underordnade dataset child är monterad på /pool/parent/child. Systemets monteringspunkt för ett dataset kan dock ändras.
Om vi skulle zfs set mountpoint=/lol pool/parent/child skulle datasetet pool/parent/child faktiskt monteras på systemet som /lol.
Förutom dataset bör vi nämna zvols. En zvol är ungefär analog med en dataset, förutom att den faktiskt inte har ett filsystem i den – det är bara en blockenhet. Du kan till exempel skapa en zvol som heter mypool/myzvol, sedan formatera den med filsystemet ext4 och sedan montera det filsystemet – du har nu ett ext4-filsystem, men med stöd av alla säkerhetsfunktioner i ZFS! Detta kan låta fånigt på en enskild dator – men det är mycket vettigare som baksida för en iSCSI-export.
Block
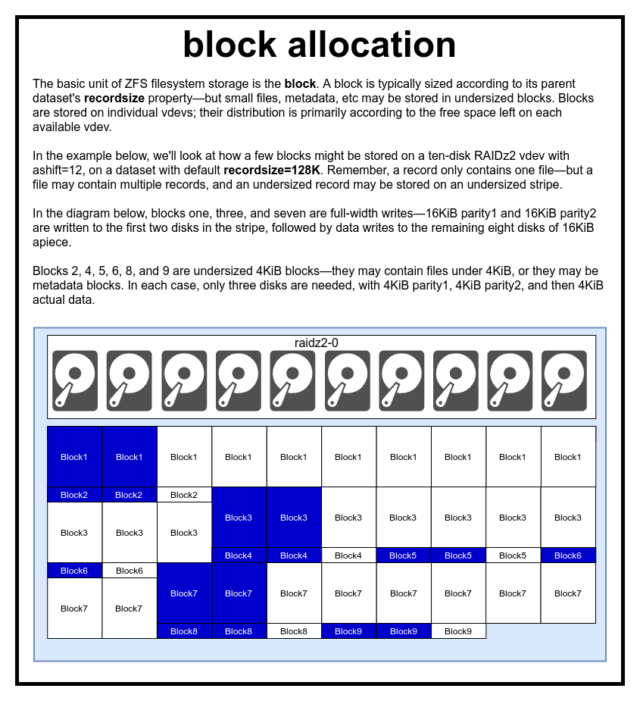

I en ZFS-pool lagras alla data – inklusive metadata – i blocks. Den maximala storleken på en block definieras för varje dataset i egenskapen recordsize. Recordsize kan ändras, men om recordsize ändras inte storleken eller layouten för blocks som redan har skrivits till datasetet – endast för nya block när de skrivs.
Om inte annat är definierat är det nuvarande standardvärdet recordsize 128KiB. Detta representerar en slags orolig kompromiss där prestandan inte kommer att vara idealisk för mycket av något, men inte heller förskräcklig för mycket av något. Recordsize kan sättas till vilket värde som helst från 4K till 1M. (Recordsize kan ställas in ännu större med ytterligare inställningar och tillräcklig beslutsamhet, men det är sällan en bra idé.)
Varje given block refererar till data från endast en fil – du kan inte klämma in två separata filer i samma block. Varje fil består av en eller flera blocks, beroende på storlek. Om en fil är mindre än recordsize kommer den att lagras i ett underdimensionerat block – till exempel kommer en block som innehåller en 2KiB-fil bara att uppta en enda 4KiB sector på disken.
Om en fil är tillräckligt stor för att kräva flera blocks kommer alla poster som innehåller den filen att vara recordsize långa – inklusive den sista posten, som kan bestå av mestadels slappt utrymme.
Zvols har inte egenskapen recordsize – i stället har de volblocksize, vilket är ungefär likvärdigt.
Sektorer
Den sista byggstenen att diskutera är den låga sector. En sector är den minsta fysiska enheten som kan skrivas till eller läsas från sin underliggande device. Under flera decennier använde de flesta diskar 512 byte sectors. På senare tid använder de flesta diskar 4KiB sectors, och vissa – särskilt SSD – använder 8KiB sectors, eller till och med större.
ZFS har en egenskap som gör att du manuellt kan ställa in sector storleken, kallad ashift. Något förvirrande nog är ashift faktiskt den binära exponenten som representerar sektorstorlek – om du till exempel ställer in ashift=9 innebär det att din sector-storlek blir 2^9, eller 512 byte.
ZFS frågar operativsystemet om detaljer om varje block device när det läggs till i ett nytt vdev, och i teorin kommer det att automatiskt ställa in ashift på rätt sätt baserat på den informationen. Tyvärr finns det många diskar som ljuger genom tänderna om vad deras sector-storlek är, för att förbli kompatibla med Windows XP (som inte kunde förstå diskar med någon annan sector-storlek).
Detta innebär att en ZFS-administratör rekommenderas starkt att känna till den faktiska sector-storleken på sin devices, och manuellt ställa in ashift i enlighet med detta. Om ashift sätts för lågt uppkommer ett astronomiskt läs-/skrivförstärkningsstraff – att skriva en 512 byte stor ”sektor” till en 4KiB verklig sector innebär att man måste skriva den första ”sektorn”, sedan läsa 4KiB sector, ändra den med den andra 512 byte stora ”sektorn”, skriva tillbaka den till en *nya* 4KiB sector och så vidare, för varje enskild skrivning.
I verkligheten drabbar detta förstärkningsstraff en Samsung EVO SSD – som borde ha ashift=13, men som ljuger om sin sektorstorlek och därför har standardvärdet ashift=9 om det inte åsidosätts av en kunnig administratör – tillräckligt hårt för att få den att framstå som långsammare än en konventionell rostskiva.
Däremot finns det i stort sett ingen straffavgift för att ställa ashift för högt. Det finns ingen riktig prestandaförlust och ökningen av slack space är oändligt liten (eller noll, om komprimering är aktiverad). Vi rekommenderar starkt att även diskar som verkligen använder 512 byte-sektorer bör ställas in på ashift=12 eller till och med ashift=13 för att säkra framtiden.
Den ashift-egenskapen är per-vdev-inte per pool, som man vanligen och felaktigt tror!-och är oföränderlig när den väl har ställts in. Om du av misstag klantar ashift när du lägger till en ny vdev till en pool har du oåterkalleligen kontaminerat den poolen med en drastiskt underpresterande vdev, och har i allmänhet ingen annan utväg än att förstöra poolen och börja om från början. Inte ens borttagning av vdev kan rädda dig från en misslyckad ashift-inställning!
Copy-on-Write-semantik




CoW-Copy on Write är en grundläggande grund för det mesta av det som gör ZFS fantastiskt. Grundkonceptet är enkelt – om du ber ett traditionellt filsystem att ändra en fil på plats gör det exakt vad du bad det om. Om du ber ett copy-on-write-filsystem att göra samma sak säger det ”okej” – men det ljuger för dig.
Istället skriver copy-on-write-filsystemet ut en ny version av block som du har ändrat, och uppdaterar sedan filens metadata för att ta bort länken till den gamla block och länka till den nya block som du just skrev.
Underlänkning av den gamla block och inlänkning av den nya sker i en enda operation, så det kan inte avbrytas – om du släpper strömmen efter det att det har hänt har du den nya versionen av filen, och om du släpper strömmen innan har du den gamla versionen. Du är alltid filsystemkonsistent, oavsett vilket.
Copy-on-write i ZFS finns inte bara på filsystemnivå, utan även på diskhanteringsnivå. Detta innebär att RAID-hålet – ett tillstånd där en remsa endast skrivs delvis innan systemet kraschar, vilket gör arrayen inkonsekvent och korrupt efter en omstart – inte påverkar ZFS. Stripe-skrivningar är atomära, vdev:n är alltid konsistent och Bob är din farbror.
ZIL – ZFS Intent Log
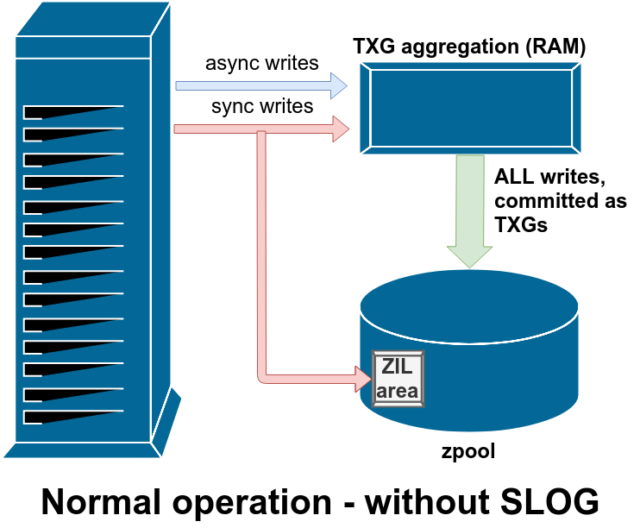

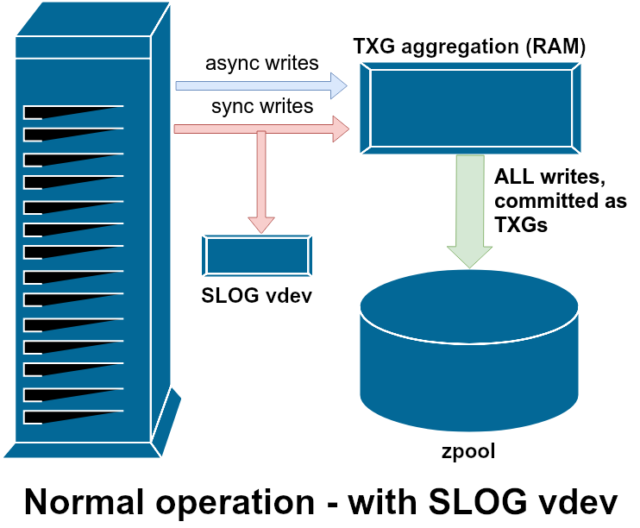

Det finns två huvudkategorier av skrivoperationer – synkrona (sync) och asynkrona (async). För de flesta arbetsbelastningar är den stora majoriteten av skrivoperationer asynkrona – filsystemet tillåts samla dem och överföra dem i omgångar, vilket minskar fragmenteringen och ökar genomströmningen enormt.
Synkrona skrivningar är ett helt annat djur – när ett program begär en synkron skrivning talar det om för filsystemet att ”du måste överföra det här till icke-flyktigt lagringsutrymme nu, och förrän du gör det kan jag inte göra något annat”. Sync writes måste därför överföras till disken omedelbart – och om det ökar fragmenteringen eller minskar genomströmningen får det vara så.
ZFS hanterar sync writes på ett annat sätt än normala filsystem – i stället för att omedelbart spola ut sync writes till normalt lagringsutrymme överförs de av ZFS till ett särskilt lagringsutrymme som kallas ZFS Intent Log, eller ZIL. Tricket här är att dessa skrivningar också stannar kvar i minnet och aggregeras tillsammans med normala asynkrona skrivförfrågningar, för att senare spolas ut till lagret som helt normala TXGs (Transaction Groups).
I normal drift skrivs det till ZIL och läses aldrig mer därifrån. När skrivningar som sparats till ZIL några ögonblick senare överförs till huvudlagret från RAM i normala TXGs, kopplas de bort från ZIL. Den enda gången ZIL läses från är vid poolimport.
Om ZFS kraschar – eller om operativsystemet kraschar, eller om det blir ett obehandlat strömavbrott – medan det finns data i ZIL, kommer dessa data att läsas från vid nästa poolimport (t.ex. när ett kraschat system startas om). Det som finns i ZIL kommer att läsas in, aggregeras till TXGs, överföras till huvudlagret och sedan avlänkas från ZIL under importprocessen.
En av de klasser av stöd vdev som finns tillgängliga är LOG-också känd som SLOG, eller Secondary LOG-enhet. Allt SLOG gör är att förse poolen med en separat – och förhoppningsvis mycket snabbare, med mycket hög skrivuthållighet – vdev att lagra ZIL i, i stället för att behålla ZIL på huvudlagret vdevs. I alla avseenden beter sig ZIL på samma sätt oavsett om den finns på huvudlagringsutrymmet eller på en LOG vdev – men om LOG vdev har mycket hög skrivprestanda kommer synkroniserade skrivreturer att ske mycket snabbt.
Att lägga till en LOG vdev till en pool kan absolut inte och kommer inte att direkt förbättra den asynkrona skrivprestandan – även om du tvingar in alla skrivningar i ZIL med hjälp av zfs set sync=always, blir de fortfarande överförda till huvudlagret i TXGs på samma sätt och i samma takt som de skulle ha gjort utan LOG. De enda direkta prestandaförbättringarna gäller synkron skrivlatens (eftersom LOGs högre hastighet gör att sync-anropet kan återkomma snabbare).
I en miljö som redan kräver många synkrona skrivningar kan en LOG vdev dock indirekt påskynda även asynkrona skrivningar och läsningar utan cachning. Att avlasta ZIL-skrivningar till en separat LOG vdev innebär mindre konkurrens om IOPS på den primära lagringsenheten, vilket ökar prestandan för alla läsningar och skrivningar till viss del.
Snapshots
Kopiering vid skrivning-semantiken är också det nödvändiga underlaget för ZFS atomära ögonblicksbilder och inkrementell asynkron replikering. Det levande filsystemet har ett träd av pekare som markerar alla records som innehåller aktuella data – när du tar en ögonblicksbild gör du helt enkelt en kopia av detta träd av pekare.
När en post skrivs över i det levande filsystemet skriver ZFS den nya versionen av block till oanvänt utrymme först. Sedan kopplar den bort den gamla versionen av block från det aktuella filsystemet. Men om någon snapshot refererar till den gamla block förblir den fortfarande oföränderlig. Den gamla block kommer faktiskt inte att återtas som ledigt utrymme förrän alla snapshots som refererar till den block har förstörts!
Replikering

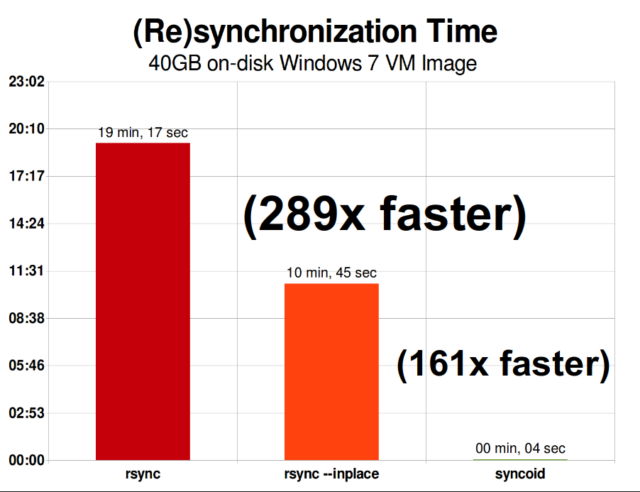
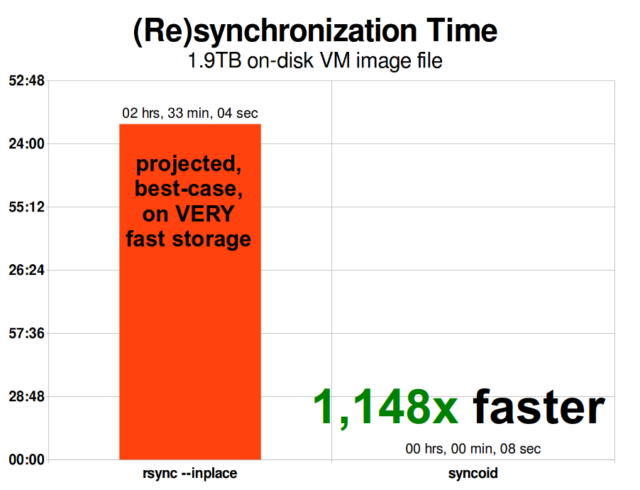 När du väl har förstått hur ögonblicksbilder fungerar har du en bra utgångspunkt för att förstå replikering. Eftersom en ögonblicksbild helt enkelt är ett träd av pekare till
När du väl har förstått hur ögonblicksbilder fungerar har du en bra utgångspunkt för att förstå replikering. Eftersom en ögonblicksbild helt enkelt är ett träd av pekare till records följer det att om vi zfs send en ögonblicksbild skickar vi både det trädet och alla tillhörande poster. När vi överför den zfs send till en zfs receive på målet skrivs både det faktiska block-innehållet och trädet av pekare som hänvisar till blocks in i måldatasetetet.
Det blir intressantare med din andra zfs send. Nu när du har två system som båda innehåller ögonblicksbilden poolname/datasetname@1 kan du ta en ny ögonblicksbild, poolname/datasetname@2. Så på källpoolen har du datasetname@1 och datasetname@2, och på målpoolen har du än så länge bara den första ögonblicksbilden – datasetname@1.
Då vi har en gemensam ögonblicksbild mellan källa och mål – datasetname@1 – kan vi bygga en inkrementell zfs send ovanpå den. När vi ber systemet att zfs send -i poolname/datasetname@1 poolname/datasetname@2 jämför det de två pekarträden. Alla pekare som bara finns i @2 refererar uppenbarligen till nya blocks-så vi behöver innehållet i dessa blocks också.
På fjärrsystemet är det lika enkelt att pipa in den resulterande inkrementella send. Först skriver vi ut alla nya records som ingår i send-strömmen, sedan lägger vi in pekarna till dessa blocks. Presto, vi har @2 på det nya systemet!
ZFS asynkron inkrementell replikering är en enorm förbättring jämfört med tidigare, icke-snapshotbaserade tekniker som rsync. I båda fallen är det bara de ändrade uppgifterna som behöver sändas över kabeln – men rsync måste först läsa alla uppgifter från disken, på båda sidor, för att kunna göra en kontrollsumma och jämföra dem. Däremot behöver ZFS-replikering inte läsa något annat än pekarträden – och alla blocks som pekarträden innehåller och som inte redan fanns i den gemensamma ögonblicksbilden.
Inlinekomprimering
Kopiering vid skrivning-semantiken gör det också lättare att erbjuda inlinekomprimering. Med ett traditionellt filsystem som erbjuder ändring på plats är komprimering problematisk – både den gamla och den nya versionen av de ändrade uppgifterna måste rymmas i exakt samma utrymme.
Om vi tänker på en datamängd i mitten av en fil som börjar sitt liv som 1 MB nollor – 0x00000000 ad nauseam – skulle den mycket lätt kunna komprimeras ner till en enda disksektor. Men vad händer om vi ersätter denna 1MiB nollor med 1MiB inkomprimerbara data, t.ex. JPEG eller pseudo slumpmässigt brus? Plötsligt behöver den 1MiB data 256 4KiB-sektorer, inte bara en – och hålet i mitten av filen är bara en sektor brett.
ZFS har inte det här problemet, eftersom modifierade poster alltid skrivs till oanvänt utrymme – den ursprungliga block upptar bara en enda 4KiB sector, och den nya posten upptar 256 stycken, men det är inget problem – den nymodifierade biten från ”mitten” av filen skulle ha skrivits till oanvänt utrymme vare sig storleken ändrats eller inte, så för ZFS är det här ”problemet” bara en vanlig dag på kontoret.
ZFS:s inline-komprimering är avstängd som standard, och den erbjuder instoppbara algoritmer – för närvarande LZ4, gzip (1-9), LZJB och ZLE.
- LZ4 är en strömalgoritm som erbjuder extremt snabb komprimering och dekomprimering, och är en prestandavinst för de flesta användningsfall – till och med med med mycket anemiska CPU:er.
- GZIP är den anrika algoritmen som alla Unix-lika användare känner till och älskar. Den kan implementeras med komprimeringsnivåerna 1-9, med ökande kompressionsförhållande och CPU-användning när nivåerna närmar sig 9. Gzip kan vara en vinst för användningsfall med enbart text (eller på annat sätt extremt komprimerbara), men resulterar ofta i flaskhalsar i processorn i andra fall – använd med försiktighet, särskilt på högre nivåer.
- LZJB är den ursprungliga algoritmen som används av ZFS. Den är föråldrad och bör inte längre användas – LZ4 är överlägsen i alla avseenden.
- ZLE är Zero Level Encoding (kodning på nollnivå) – den lämnar normala data helt ifred, men komprimerar stora sekvenser av nollor. Användbar för helt inkomprimerbara dataset (t.ex. JPEG, MP4 eller andra redan komprimerade format), eftersom den ignorerar de inkomprimerbara uppgifterna men komprimerar det slappa utrymmet i de slutliga posterna.
Vi rekommenderar LZ4-komprimering för nästan alla tänkbara användningsfall; prestandaförlusten när den möter inkomprimerbara uppgifter är mycket liten och prestandaförbättringen för typiska uppgifter är betydande. Att kopiera en VM-avbildning för en ny Windows-operativsysteminstallation (bara det installerade Windows-operativsystemet, inga data på det ännu) gick 27 % snabbare med compression=lz4 än compression=none i detta test från 2015.
ARC-the Adaptive Replacement Cache
ZFS är det enda moderna filsystem som vi känner till som använder en egen mekanism för läscache, i stället för att förlita sig på operativsystemets sidcache för att hålla kopior av nyligen lästa block i RAM för det.
Och även om den separata cachemekanismen har sina problem – ZFS kan inte reagera på nya förfrågningar om att allokera minne lika omedelbart som kärnan kan, och därför kan ett nytt mallocate()-anrop misslyckas om det skulle behöva RAM-minne som för närvarande är upptaget av ARC – finns det goda skäl, åtminstone för tillfället, att stå ut med det.
Varje välkänt modernt operativsystem – inklusive MacOS, Windows, Linux och BSD – använder LRU-algoritmen (Least Recently Used) för sin implementering av page cache. LRU är en naiv algoritm som flyttar upp ett block i cachen till toppen av kön varje gång det läses, och som vid behov avlägsnar block från botten av kön för att lägga till nya cachemissar (block som måste läsas från disken i stället för från cacheminnet) i toppen.”
Detta är bra så långt det går, men i system med stora arbetsdatamängder kan LRU lätt hamna i ”thrashing”, dvs. att block som behövs mycket ofta avlägsnas för att ge plats åt block som aldrig kommer att läsas från cacheminnet igen.
ARC är en mycket mindre naiv algoritm, som kan ses som en ”viktad” cache. Varje gång ett block i cachen läses blir det lite ”tyngre” och svårare att evakuera – och även efter en evakuering spåras det evakuerade blocket under en viss tid. Ett block som har utvisats men som sedan måste läsas tillbaka till cacheminnet blir också ”tyngre” och svårare att utvisa.
Slutresultatet av allt detta är ett cacheminnet med vanligtvis mycket högre träffprocent – förhållandet mellan cacheträffar (läsningar som serveras från cacheminnet) och cachemissar (läsningar som serveras från disken). Detta är en ytterst viktig statistik – inte bara är cacheträffarna i sig själva serverade i storleksordningar snabbare, utan cachemissarna kan också serveras snabbare, eftersom fler cacheträffar = färre samtidiga förfrågningar till disken = lägre latenstid för de återstående missarna som måste betjänas från disken.
Slutsats
Nu när vi har behandlat den grundläggande semantiken i ZFS – hur copy-on-write fungerar och förhållandet mellan pooler, vdevs, block, sektorer och filer – är vi redo att tala om verklig prestanda, med riktiga siffror.
Håll utkik efter nästa avsnitt i vår serie om grunderna för lagring för att se den faktiska prestandan i pooler som använder spegel- och RAIDz-vdevs, jämfört med både varandra och de traditionella RAID-topologierna i Linuxkärnan som vi utforskade tidigare.
Inledningsvis kommer vi bara att täcka grunderna – själva ZFS-topologierna – men efter det kommer vi att vara redo att prata om mer avancerad ZFS-inställning och -inställning, inklusive användningen av stödvdevd-typer som L2ARC, SLOG och Special Allocation.