
Kun me kaikki siirrymme COVID-19-pandemian kolmanteen kuukauteen ja etsimme uusia projekteja, jotka pitävät meidät mukana (lue: järjissämme), voisimmeko kiinnostaa sinua opettelemalla tietokoneiden tallennuksen perusteita? Hiljalleen tänä keväänä olemme jo käyneet läpi joitakin välttämättömiä perusasioita, kuten sen, miten levyjen nopeutta voi testata ja mikä ihmeen RAID on. Toisessa noista jutuista lupasimme jopa jatkoa, jossa tutkimme erilaisten monilevyisten topologioiden suorituskykyä ZFS:ssä, seuraavan sukupolven tiedostojärjestelmässä, josta olet kuullut, koska se esiintyy kaikkialla Applelta Ubuntuun.
Nyt, tänään on se päivä, jolloin voitte tutkia, ZFS:stä uteliaat lukijat. Tietäkää vain etukäteen, että OpenZFS-kehittäjä Matt Ahrensin vähättelevien sanojen mukaan ”se on todella monimutkaista.”
Mutta ennen kuin pääsemme numeroihin – ja niitä on tulossa, lupaan sen!-kaikkiin tapoihin, joilla voit muokata kahdeksan levyn verran ZFS:ää, meidän on puhuttava siitä, miten ZFS ylipäätään tallentaa tietosi levylle.
Zpoolit, vdev:t ja laitteet
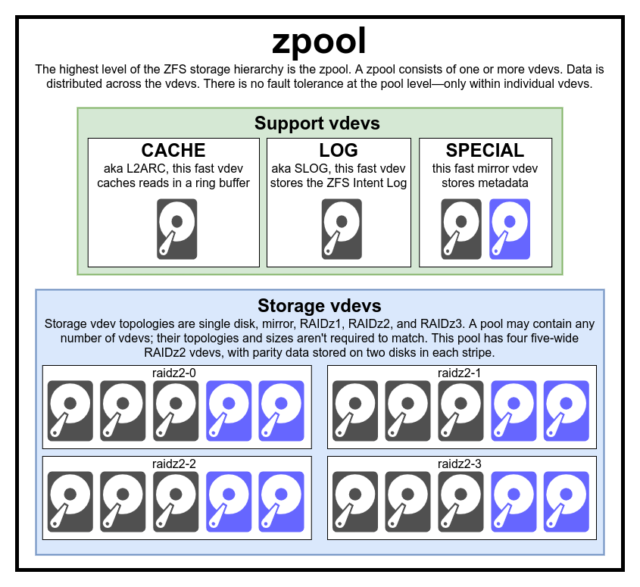

Voidaksesi todella ymmärtää ZFS:ää, sinun on kiinnitettävä todellista huomiota sen varsinaiseen rakenteeseen. ZFS sulauttaa yhteen perinteiset tietueiden hallinta- ja tiedostojärjestelmäkerrokset, ja se käyttää copy-on-write-tapahtumamekanismia – molemmat näistä tarkoittavat, että järjestelmä eroaa rakenteellisesti hyvin paljon perinteisistä tiedostojärjestelmistä ja RAID-matriiseista. Ensimmäiset tärkeät rakennuspalikat, jotka on ymmärrettävä, ovat zpools, vdevs ja devices.
zpool
zpool on ZFS:n ylin rakenne. Zpool sisältää yhden tai useamman vdevs, joista kukin puolestaan sisältää yhden tai useamman devices. Zpoolit ovat itsenäisiä yksiköitä – yhdellä fyysisellä tietokoneella voi olla kaksi tai useampia erillisiä zpooleja, mutta jokainen niistä on täysin riippumaton muista. Zpoolit eivät voi jakaa vdevs keskenään.
ZFS-redundanssi on vdev-tasolla, ei zpool-tasolla. Zpool-tasolla ei ole minkäänlaista redundanssia – jos jokin tallennus vdev tai SPECIAL vdev menetetään, koko zpool menetetään sen mukana.
Nykyaikaiset zpoolit selviävät CACHE tai LOG vdev:n menetyksestä – vaikka ne saattavat menettää pienen määrän likaista dataa, jos ne menettävät LOG vdev:n sähkökatkon tai järjestelmän kaatumisen aikana.
Yleinen harhaluulo on, että ZFS ”raidoittaa” kirjoitukset pooliin – mutta tämä ei pidä paikkaansa. Zpool ei ole hassun näköinen RAID0 – se on hassun näköinen JBOD, jossa on monimutkainen jakomekanismi, joka voi muuttua.
Suurimmaksi osaksi kirjoitukset jaetaan käytettävissä oleville vdev:ille niiden käytettävissä olevan vapaan tilan mukaan, joten kaikki vdev:t tulevat teoriassa täyteen samaan aikaan. ZFS:n uudemmissa versioissa vdev:n käyttöaste saatetaan myös ottaa huomioon – jos jokin vdev on huomattavasti kiireisempi kuin toinen (esim. lukukuormituksen vuoksi), se saatetaan ohittaa tilapäisesti kirjoitusta varten, vaikka sillä on eniten vapaata tilaa käytettävissä.
Nykyaikaisiin ZFS:n kirjoitusjakelumenetelmiin sisäänrakennettu käyttöasteen huomiointimekanismi voi pienentää latenssia ja kasvattaa läpäisykykyä epätavallisen suuren kuorman aikana – mutta sitä ei pidä erehtyä luulemaan vapaaksi valtakirjaksi sekoitella hitaita ruoste-levyjä ja nopeita SSD-levyjä mielivaltaisesti samassa pooliin. Tällainen väärin sovitettu pooli toimii silti yleensä ikään kuin se koostuisi kokonaan läsnä olevasta hitaimmasta laitteesta.
vdev
Jokainen zpool koostuu yhdestä tai useammasta vdevs(lyhenne sanoista virtual device). Jokainen vdev puolestaan koostuu yhdestä tai useammasta todellisesta devices. Useimpia vdev-tyyppejä käytetään tavalliseen tallennukseen, mutta on olemassa myös useita erityisiä vdev-tukiluokkia, kuten CACHE, LOG ja SPECIAL. Kukin näistä vdev-tyypeistä voi tarjota yhden viidestä topologiasta – yhden laitteen, RAIDz1:n, RAIDz1:n, RAIDz2:n, RAIDz3:n tai peilauksen.
RAIDz1-, RAIDz2- ja RAIDz3-topologiat ovat erikoisvariaatioita siitä, mitä tallennuksen harmaapartaat kutsuvat nimellä ”diagonaalinen pariteettirakenne RAID”. Numerot 1, 2 ja 3 viittaavat siihen, kuinka monta pariteettilohkoa kullekin dataliuskalle on varattu. Sen sijaan, että kokonaisia levyjä olisi varattu pariteetille, RAIDz-levyt jakavat pariteetin puoliksi tasaisesti levyille. RAIDz-määritys voi menettää niin monta levyä kuin siinä on pariteettilohkoja; jos se menettää toisenkin, se kaatuu ja vie zpool mukanaan.
Peilivdev:t ovat juuri sitä, miltä ne kuulostavatkin – peilivdev:ssä kukin lohko tallentuu vdev:n jokaiseen laitteeseen. Vaikka kaksileveät peilit ovat yleisimpiä, mirror vdev voi sisältää minkä tahansa määrän laitteita – kolmitiepeilit ovat yleisiä suuremmissa kokoonpanoissa paremman lukusuorituskyvyn ja vikasietoisuuden vuoksi. Peilattu vdev kestää minkä tahansa vian, kunhan vähintään yksi vdev:n laite pysyy terveenä.
Yksittäisen laitteen vdev:t ovat myös juuri sitä, miltä ne kuulostavat – ja ne ovat luonnostaan vaarallisia. Yhden laitteen vdev ei selviä mistään vikaantumisesta – ja jos sitä käytetään tallennus- tai SPECIAL vdev:nä, sen vikaantuminen vie koko zpool vdev:n mukanaan. Ole tässä hyvin, hyvin varovainen.
CACHE, LOG ja SPECIAL vdev:t voidaan luoda millä tahansa edellä mainituista topologioista – mutta muista, että SPECIAL vdev:n menetys tarkoittaa poolin menetystä, joten redundanttia topologiaa suositellaan lämpimästi.
device
Tämä on luultavasti ZFS:ään liittyvä termi, jonka ymmärtäminen lienee helpointa – kirjaimellisesti kyse on pelkkä satunnaiskäytössä oleva lohko- eli random-access-lohkokoontumislaite. Muista, että vdevs muodostuu yksittäisistä laitteista, ja zpool muodostuu vdevs:sta.
Kiekot – joko ruosteiset tai kiinteät – ovat yleisimpiä lohkolaitteita, joita käytetään vdev-rakennuspalikoina. Mikä tahansa, jonka kuvaaja on /dev:ssä ja joka sallii satunnaiskäytön, toimii kuitenkin – kokonaisia laitteiston RAID-joukkoja voidaan käyttää (ja joskus käytetäänkin) yksittäisinä laitteina.
Yksinkertainen raakatiedosto on yksi tärkeimmistä vaihtoehtoisista lohkolaitteista, joista vdev voidaan rakentaa. Karkeista tiedostoista tehdyt testipoolit ovat uskomattoman kätevä tapa harjoitella zpool-komentoja ja nähdä, kuinka paljon tilaa tietyn topologian poolissa tai vdev:ssä on käytettävissä.

Asettakaamme, että harkitset kahdeksanväyläisen palvelimen rakentamista ja olet melko varma, että haluat käyttää 10 Tt:n (~9300 GiB) levyjä – mutta et ole varma, mikä topologia sopii parhaiten tarpeisiisi. Yllä olevassa esimerkissä rakensimme testipoolin harvoista tiedostoista muutamassa sekunnissa – ja nyt tiedämme, että kahdeksasta 10TB:n levystä koostuva RAIDz2-vdev tarjoaa 50TiB:n käyttökapasiteetin.
On olemassa yksi erityinen device-luokka – SPARE. Hotspare-laitteet, toisin kuin tavalliset laitteet, kuuluvat koko pooliin, eivät yksittäiseen vdev. Jos johonkin poolin vdev-laitteeseen tulee laitevika ja SPARE on liitetty pooliin ja käytettävissä, SPARE liitetään automaattisesti hajonneeseen vdev-laitteeseen.
Kun SPARE on liitetty hajonneeseen vdev-laitteeseen, SPARE-yksikkö alkaa vastaanottaa kopioita tai rekonstruktioita tiedoista, joiden pitäisi olla puuttuvassa laitteessa. Perinteisessä RAID-järjestelmässä tätä kutsuttaisiin ”uudelleenrakentamiseksi” – ZFS:ssä sitä kutsutaan ”resilveroinniksi”.
On tärkeää huomata, että SPARE-laitteet eivät korvaa pysyvästi vikaantuneita laitteita. Ne ovat vain paikanpitäjiä, joiden tarkoituksena on minimoida ikkuna, jonka aikana vdev toimii heikentyneenä. Kun ylläpitäjä on korvannut vdev:n vikaantuneen laitteen ja uusi, pysyvä korvaava laite palautuu, SPARE irrottaa itsensä vdev:stä ja palaa poolin laajuisiin tehtäviin.
Datasarjat, lohkot ja sektorit
Seuraavat rakennuspalikat, jotka sinun on ymmärrettävä ZFS-matkallasi, eivät liity niinkään laitteistoon vaan siihen, miten data itsessään on järjestetty ja tallennettu. Ohitamme tässä muutamia tasoja – kuten metalaboratorion – jotta asiat pysyisivät mahdollisimman yksinkertaisina, mutta ymmärtäisimme silti kokonaisrakenteen.
Datasarjat

ZFS dataset on karkeasti ottaen analoginen tavallisen, asennetun tiedostojärjestelmän kanssa – kuten tavanomainen tiedostojärjestelmä, se näyttää satunnaisen tarkastelun perusteella siltä, että se on ”vain yksi kansio lisää”. Mutta kuten tavanomaisilla asennetuilla tiedostojärjestelmillä, myös jokaisella ZFS dataset:llä on omat ominaisuutensa.
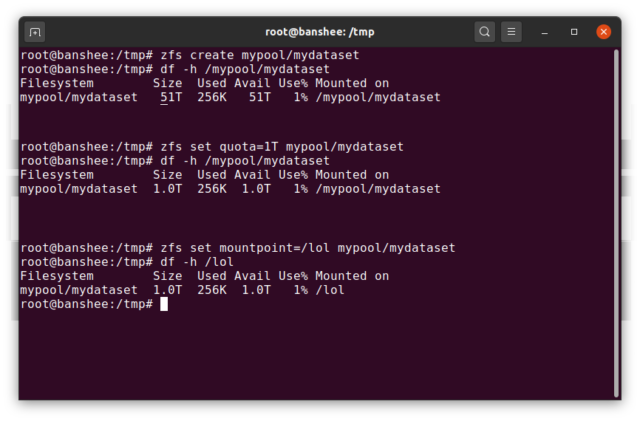
Ensisijaisesti dataset:lle voi olla määritetty kiintiö. Jos zfs set quota=100G poolname/datasetname, et voi laittaa yli 100GiB dataa järjestelmään asennettuun kansioon /poolname/datasetname.
Havaitsitko edellä olevassa esimerkissä johtavien vinoviivojen läsnäolon – ja niiden puuttumisen? Jokaisella tietokokonaisuudella on oma paikkansa sekä ZFS-hierarkiassa että järjestelmän kiinnityshierarkiassa. ZFS-hierarkiassa ei ole etumaisia vinoviivoja – aloitetaan poolin nimellä ja sitten polku datasetista toiseen – esim. pool/parent/child datasetille nimeltä child vanhemman datasetin parent alla poolissa, jonka nimi on pool.
Oletusarvoisesti dataset:n kiinnityspiste vastaa sen ZFS-hierarkkista nimeä, jossa on etummainen vinoviiva – allas nimeltä pool on kiinnitetty osoitteeseen /pool, dataset parent on kiinnitetty osoitteeseen /pool/parent ja tytärdataset child on kiinnitetty osoitteeseen /pool/parent/child. Tietokokonaisuuden järjestelmän kiinnityspistettä voidaan kuitenkin muuttaa.
Jos olisimme zfs set mountpoint=/lol pool/parent/child, tietokokonaisuus pool/parent/child olisi todellisuudessa kiinnitetty järjestelmään nimellä /lol.
Tietokokonaisuuksien lisäksi mainittakoon vielä zvols. zvol on suurin piirtein analoginen dataset:n kanssa, paitsi että siinä ei oikeastaan ole tiedostojärjestelmää – se on vain lohkolaite. Voit esimerkiksi luoda zvol:n nimeltä mypool/myzvol, alustaa sen ext4-tiedostojärjestelmällä ja liittää sen tiedostojärjestelmän – sinulla on nyt ext4-tiedostojärjestelmä, mutta sen tukena ovat kaikki ZFS:n turvaominaisuudet! Tämä saattaa kuulostaa hölmöltä yksittäisessä tietokoneessa – mutta se on paljon järkevämpää iSCSI-vientitiedoston taustapäätteenä.
Blocks
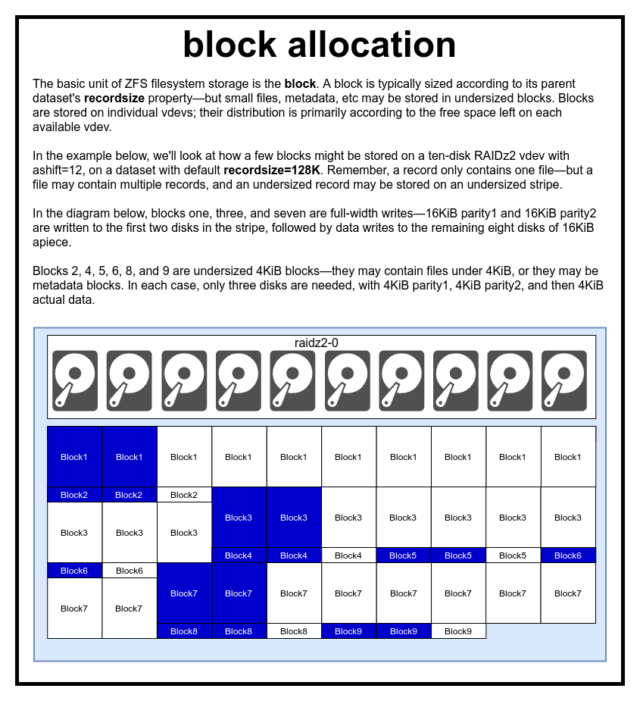

ZFS-poolissa kaikki data – myös metadata – tallennetaan blocks:een. block:n enimmäiskoko määritellään kullekin dataset:lle recordsize-ominaisuudessa. Recordsize on muuttuva, mutta recordsize:n muuttaminen ei muuta jo tietokokonaisuuteen kirjoitettujen blocks:n kokoa tai asettelua – ainoastaan uusien lohkojen kokoa tai asettelua sitä mukaa, kun niitä kirjoitetaan.
Jos ei ole toisin määritelty, nykyinen oletusarvo recordsize on 128KiB. Tämä edustaa eräänlaista epämiellyttävää kompromissia, jossa suorituskyky ei ole ihanteellinen juuri missään, mutta ei myöskään kauhea juuri missään. Recordsize voidaan asettaa mihin tahansa arvoon 4K:n ja 1M:n välillä. (Recordsize voidaan asettaa vieläkin suuremmaksi lisävirityksillä ja riittävällä määrätietoisuudella, mutta se on harvoin hyvä ajatus.)
Mikä tahansa block viittaa dataan vain yhdestä tiedostosta – et voi ahtaa kahta erillistä tiedostoa samaan block:een. Kukin tiedosto koostuu yhdestä tai useammasta blocks:stä, koosta riippuen. Jos tiedosto on pienempi kuin recordsize, se tallennetaan alimitoitettuun lohkoon – esimerkiksi block, joka sisältää 2KiB:n tiedoston, vie vain yhden 4KiB:n sector:n
Jos tiedosto on niin suuri, että se vaatii useita blocks:iä, kaikki kyseistä tiedostoa sisältävät tietueet ovat recordsize:n pituisia – viimeinen tietue mukaanlukien, joka voi olla suurimmaksi osaksi vapaata tilaa.
Zvols:llä ei ole recordsize-ominaisuutta – sen sijaan niillä on volblocksize-ominaisuus, joka on suurin piirtein vastaava.
Sektorit
Viimeinen rakennuspalikka, josta keskustelemme, on vaatimaton sector. sector on pienin fyysinen yksikkö, johon voidaan kirjoittaa tai josta voidaan lukea sen taustalla oleva device. Useimpien vuosikymmenien ajan useimmat levyt käyttivät 512 tavun sectors-yksikköä. Viime aikoina useimmat levyt käyttävät 4KiB sectors:tä, ja jotkut – erityisesti SSD-levyt – käyttävät 8KiB sectors:tä tai jopa suurempia.
ZFS:ssä on ominaisuus, jonka avulla sector:n koon voi asettaa manuaalisesti, nimeltään ashift. Hieman hämmentävästi ashift on itse asiassa binäärinen eksponentti, joka edustaa sektorikokoa – esimerkiksi asettamalla ashift=9 sector-koko on 2^9 eli 512 tavua.
ZFS kysyy käyttöjärjestelmältä tietoja jokaisesta lohkosta device, kun se lisätään uuteen vdev:een, ja teoriassa asettaa ashift:n kunnolla oikein näiden tietojen perusteella. Valitettavasti on monia levyjä, jotka valehtelevat hampaat irvessä siitä, mikä niiden sector-koko on, jotta ne pysyisivät yhteensopivina Windows XP:n kanssa (joka ei kyennyt ymmärtämään levyjä, joilla oli jokin muu sector-koko).
Tämä tarkoittaa, että ZFS:n ylläpitäjän on erittäin suositeltavaa olla tietoinen devices-levynsä todellisesta sector-koosta ja asettaa ashift-arvo sen mukaan manuaalisesti. Jos ashift on asetettu liian pieneksi, syntyy tähtitieteellinen luku-/kirjoitusvahvistus – 512 tavun ”sektorin” kirjoittaminen 4KiB:n todelliseen sector tarkoittaa, että ensimmäinen ”sektori” on kirjoitettava, sitten luettava 4KiB:n sector, muutettava sitä toisella 512 tavun ”sektorilla”, kirjoitettava se takaisin *uusi* 4KiB:n sector:ksi, ja niin edelleen, jokaista yksittäistä kirjoitusta varten.
Reaalimaailmassa tämä vahvistusrangaistus iskee Samsung EVO SSD:hen – jonka pitäisi olla ashift=13, mutta valehtelee sektorikoonsa suhteen ja siksi oletusarvo on ashift=9, jos fiksu ylläpitäjä ei ohita sitä – niin kovaa, että se vaikuttaa hitaammalta kuin perinteinen ruoste-levy.
Vastakohtana on se, että jos asetat liian korkeaksi arvon ashift, siitä ei seuraa käytännössä mitään seuraamuksia. Todellista suorituskykysakkoa ei ole, ja löysän tilan lisäys on äärettömän pieni (tai nolla, kun pakkaus on käytössä). Suosittelemme vahvasti, että jopa levyille, jotka todella käyttävät 512 tavun sektoreita, asetetaan ashift=12 tai jopa ashift=13 tulevaisuuden varalta.
ashift-ominaisuus on vdev-kohtainen – ei poolikohtainen, kuten yleisesti ja virheellisesti luullaan – ja se on muuttumaton, kun se on asetettu. Jos vahingossa mokaat ashift:n, kun lisäät uuden vdev:n pooliin, olet peruuttamattomasti saastuttanut poolin dramaattisesti alisuorituskykyisellä vdev:llä, eikä sinulla yleensä ole muuta keinoa kuin tuhota pool ja aloittaa alusta. Edes vdev:n poistaminen ei voi pelastaa sinua epäonnistuneelta ashift-asetukselta!
Copy-on-Write-semantiikka




CoW-Copy-on-Write on perustavanlaatuinen tukipilari suurimman osan ZFS:n mahtavuuden taustalla. Peruskonsepti on yksinkertainen – jos pyydät perinteistä tiedostojärjestelmää muuttamaan tiedostoa paikan päällä, se tekee juuri sen, mitä pyydät. Jos pyydät copy-on-write-tiedostojärjestelmää tekemään saman asian, se sanoo ”okei” – mutta se valehtelee sinulle.
Sen sijaan copy-on-write-tiedostojärjestelmä kirjoittaa uuden version muokkaamastasi block-tiedostosta ja päivittää sitten tiedoston metatiedot niin, että vanhan block-tiedon linkki poistuu ja linkittää juuri kirjoittamasi uuden block-tiedoston.
Vanhan block linkittäminen ja uuden linkittäminen tapahtuu yhdellä kertaa, joten sitä ei voi keskeyttää – jos poistat virran sen jälkeen, sinulla on tiedoston uusi versio, ja jos poistat virran ennen sitä, sinulla on vanha versio. Olet aina tiedostojärjestelmäkonsistentti, kummallakin tavalla.
Copy-on-write ZFS:ssä ei ole vain tiedostojärjestelmätasolla, vaan myös levynhallintatasolla. Tämä tarkoittaa, että RAID-aukko – tila, jossa raita kirjoitetaan vain osittain ennen järjestelmän kaatumista, mikä tekee joukosta epäjohdonmukaisen ja korruptoituneen uudelleenkäynnistyksen jälkeen – ei vaikuta ZFS:ään. Stripe-kirjoitukset ovat atomisia, vdev on aina johdonmukainen, ja Bob on setäsi.
ZIL-the ZFS Intent Log

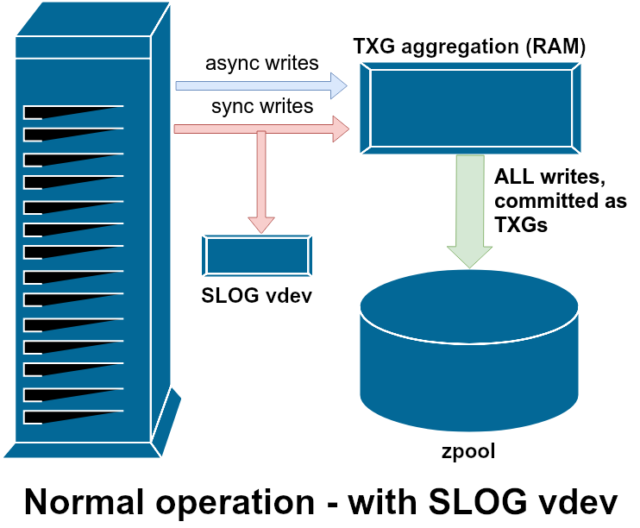

Kirjoitusoperaatioissa on kaksi pääluokkaa – synkroniset (sync) ja asynkroniset (async). Useimmissa työkuormissa valtaosa kirjoitusoperaatioista on asynkronisia – tiedostojärjestelmä saa koota ne yhteen ja sitoa ne erissä, mikä vähentää pirstaloitumista ja lisää läpäisykykyä valtavasti.
Synkronoidut kirjoitusoperaatiot ovat täysin eri asia – kun sovellus pyytää synkronoitua kirjoitusoperaatiota, se kertoo tiedostojärjestelmälle: ”Sinun on nyt sitouduttava haihtumattomaan tallennustilaan, ja ennen kuin teet sen, en voi tehdä mitään muuta”. Synkronointikirjoitukset on siis siirrettävä levylle välittömästi – ja jos se lisää pirstaloitumista tai vähentää läpäisykykyä, niin olkoon.
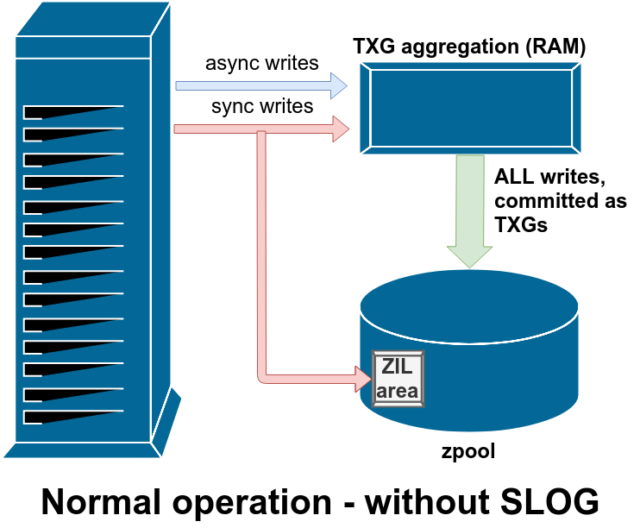
ZFS käsittelee synkronointikirjoituksia eri tavalla kuin tavalliset tiedostojärjestelmät – sen sijaan, että synkronointikirjoitukset huuhdottaisiin välittömästi pois tavalliseen tallennustilaan, ZFS siirtää ne erityiselle tallennustilalle, jota kutsutaan nimellä ZFS:n aikomusloki (ZFS Intent Log) eli ZIL. Juju tässä on se, että nämä kirjoitukset jäävät myös muistiin, ja ne kootaan yhteen normaalien asynkronisten kirjoituspyyntöjen kanssa, jotta ne voidaan myöhemmin huuhtoa ulos tallennustilaan täysin normaaleina TXG:nä (Transaction Groups).
Normaalissa toiminnassa ZIL:iin kirjoitetaan, eikä sitä enää koskaan lueta. Kun ZIL:iin tallennetut kirjoitukset siirretään RAM-muistista päävarastoon normaaleina TXG:nä muutamaa hetkeä myöhemmin, ne irrotetaan ZIL:stä. Ainoa kerta, kun ZIL:stä luetaan, on poolin tuonnin yhteydessä.
Jos ZFS kaatuu – tai käyttöjärjestelmä kaatuu tai tapahtuu käsittelemätön sähkökatkos – sillä aikaa, kun ZIL:ssä on dataa, se luetaan seuraavassa poolin tuonnissa (esim. kun kaatunut järjestelmä käynnistetään uudelleen). Se, mitä ZIL:ssä on, luetaan sisään, kootaan TXG:ksi, siirretään päätallennustilaan ja irrotetaan sitten ZIL:stä tuontiprosessin aikana.
Yksi käytettävissä olevista tukiluokista vdev on LOG – tunnetaan myös nimellä SLOG eli Secondary LOG device. Kaikki mitä SLOG tekee, on tarjota pooliin erillinen – ja toivottavasti paljon nopeampi ja erittäin korkean kirjoituskestävyyden omaava – vdev, johon ZIL voidaan tallentaa sen sijaan, että ZIL säilytettäisiin vdevs päätallennustilassa. Kaikissa suhteissa ZIL käyttäytyy samalla tavalla riippumatta siitä, onko se päätallennustilassa vai LOG-vdev:ssä – mutta jos LOG-vdev:llä on erittäin korkea kirjoitussuorituskyky, synkronoitujen kirjoitusten palautukset tapahtuvat hyvin nopeasti.
LOG vdev:n lisääminen pooliin ei missään nimessä voi eikä suoranaisesti paranna asynkronista kirjoitussuorituskykyä – vaikka pakottaisit kaikki kirjoitukset ZIL:iin zfs set sync=always:n avulla, ne silti sitoutuvat päävarastoon TXG:ssä samalla tavalla ja samalla tahdilla kuin ne olisivat sitoutuneet ilman LOG:tä. Ainoat suorat suorituskykyparannukset koskevat synkronisten kirjoitusten latenssia (koska LOG:n suurempi nopeus mahdollistaa sen, että sync-kutsu palaa nopeammin).
Ympäristössä, joka vaatii jo nyt paljon synkronisia kirjoituksia, LOG-vdev voi kuitenkin epäsuorasti nopeuttaa myös asynkronisia kirjoituksia ja välimuistiin tallentamattomia lukuja. ZIL-kirjoitusten siirtäminen erilliselle LOG vdev:lle merkitsee vähemmän kilpailua IOPS:istä ensisijaisen tallennustilan kanssa, jolloin kaikkien lukujen ja kirjoitusten suorituskyky paranee jonkin verran.
Tilannekuvat
Copy-on-write-semantiikka on myös välttämätön perusta ZFS:n atomaarisille tilannekuville (atomic snapshots) ja inkrementaaliselle epäsynkroniselle replikoinnille. Elävässä tiedostojärjestelmässä on osoitinpuu, joka merkitsee kaikki records, jotka sisältävät nykyistä dataa – kun otat tilannekuvan, teet yksinkertaisesti kopion tästä osoitinpuusta.
Kun tietue ylikirjoitetaan elävässä tiedostojärjestelmässä, ZFS kirjoittaa ensin block:n uuden version käyttämättömään tilaan. Sitten se poistaa block:n vanhan version linkit nykyisestä tiedostojärjestelmästä. Mutta jos jokin snapshot viittaa vanhaan block, se pysyy silti muuttumattomana. Vanha block ei todellisuudessa oteta takaisin vapaaksi tilaksi ennen kuin kaikki snapshots, jotka viittaavat kyseiseen block, on tuhottu!
Replikointi

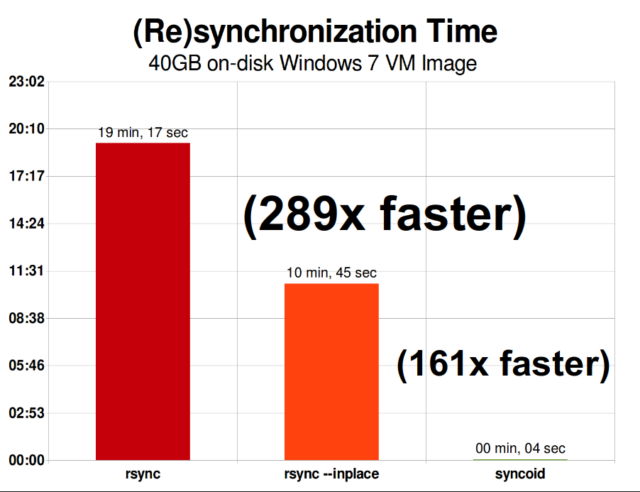
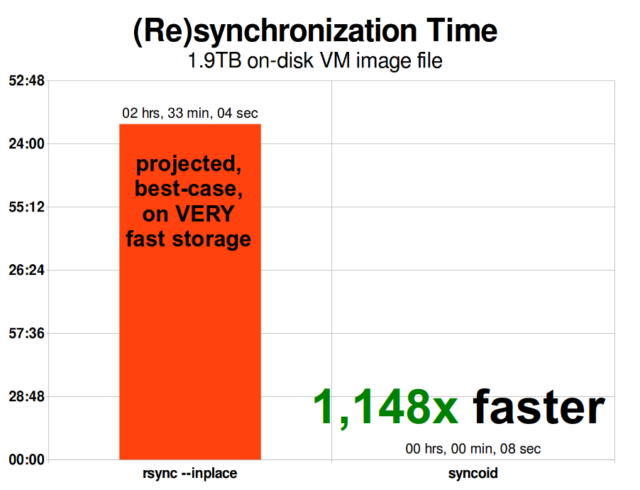 Kun olet ymmärtänyt, miten tilannekuvat toimivat, olet hyvässä asemassa ymmärtämään replikointia. Koska tilannekuva on yksinkertaisesti
Kun olet ymmärtänyt, miten tilannekuvat toimivat, olet hyvässä asemassa ymmärtämään replikointia. Koska tilannekuva on yksinkertaisesti records osoittimien puu, siitä seuraa, että jos zfs send lähetämme tilannekuvan, lähetämme sekä tuon puun että kaikki siihen liittyvät tietueet. Kun putkitamme tuon zfs send kohteen zfs receive:een, se kirjoittaa kohdetietokantaan sekä varsinaisen block:n sisällön että blocks:een viittaavien osoittimien puun.
Toisen zfs send:n kohdalla asiat muuttuvat mielenkiintoisemmiksi. Nyt kun sinulla on kaksi järjestelmää, joista kumpikin sisältää tilannekuvan poolname/datasetname@1, voit ottaa uuden tilannekuvan poolname/datasetname@2. Lähdepoolissa on siis datasetname@1 ja datasetname@2, ja kohdepoolissa on toistaiseksi vain ensimmäinen tilannekuva – datasetname@1.
Koska meillä on yhteinen tilannekuva lähde- ja kohdepoolissa – datasetname@1 – voimme rakentaa inkrementaalisen zfs send sen päälle. Kun pyydämme järjestelmää zfs send -i poolname/datasetname@1 poolname/datasetname@2, se vertaa kahta osoitinpuuta. Kaikki osoittimet, jotka ovat olemassa vain @2:ssä, viittaavat ilmeisesti uuteen blocks:een, joten tarvitsemme myös näiden blocks:ien sisällön.
Edäjärjestelmässä tuloksena syntyvän inkrementaalisen send:n syöttäminen putkella on yhtä helppoa. Ensin kirjoitetaan kaikki uudet records, jotka sisältyvät send-virtaan, ja sitten lisätään osoittimet näihin blocks. Presto, meillä on @2 uudessa järjestelmässä!
ZFS:n asynkroninen inkrementaalinen replikointi on valtava parannus aikaisempiin, ei-snapshot-pohjaisiin tekniikoihin, kuten rsync. Molemmissa tapauksissa vain muuttuneet tiedot on lähetettävä langan yli, mutta rsync:n on ensin luettava kaikki tiedot levyltä molemmilla puolilla, jotta ne voidaan tarkistaa ja verrata. Sitä vastoin ZFS-replikoinnin ei tarvitse lukea muuta kuin osoitinpuut – ja kaikki blocks, joita osoitinpuu sisältää ja joita ei ollut jo yhteisessä tilannekuvassa.
Inline-pakkaus
Copy-on-write-semantiikka helpottaa myös inline-pakkauksen tarjoamista. Perinteisessä tiedostojärjestelmässä, joka tarjoaa paikan päällä tapahtuvaa muokkausta, pakkaaminen on ongelmallista – sekä vanhan version että uuden version muokatusta datasta on mahduttava täsmälleen samaan tilaan.
Jos tarkastelemme tiedoston keskellä olevaa dataa, joka aloittaa elämänsä 1MiB:n kokoisena nollia –0x00000000 ad nauseam – se pakkautuisi hyvin helposti yhteen levysektoriin. Mutta mitä tapahtuu, jos korvaamme tuon 1MiB nollia 1MiB:llä pakkautumatonta dataa, kuten JPEG tai pseudosattumanvaraista kohinaa? Yhtäkkiä tuo 1MiB dataa tarvitsee 256 4KiB:n sektoria, ei vain yhtä – ja tiedoston keskellä oleva aukko on vain yhden sektorin levyinen.
ZFS:llä ei ole tätä ongelmaa, koska modifioidut tietueet kirjoitetaan aina käyttämättömään tilaan – alkuperäinen block vie vain yhden 4KiB:n sector, ja uusi tietue vie 256:aa niistä, mutta se ei ole ongelma – juuri modifioitu kappale tiedoston ”keskeltä” olisi kirjoitettu käyttämättömään tilaan riippumatta siitä, muuttuiko sen koko vai ei, joten ZFS:n kohdalla tämä ”ongelma” on pelkkä arkipäivä.
ZFS:n rivipakkaus on oletusarvoisesti pois päältä, ja se tarjoaa liitettävissä olevia algoritmeja – tällä hetkellä LZ4, gzip (1-9), LZJB ja ZLE.
- LZ4 on virta-algoritmi, joka tarjoaa erittäin nopean pakkauksen ja purkamisen, ja se on suorituskyvyn voitto suurimmassa osassa käyttötapauksia – jopa hyvin aneemisilla suorittimilla.
- GZIP on kunnioitettava algoritmi, jonka kaikki Unixin kaltaiset käyttäjät tuntevat ja rakastavat. Se voidaan toteuttaa pakkaustasoilla 1-9, ja pakkaussuhde ja suorittimen käyttö lisääntyvät, kun tasot lähestyvät tasoa 9. Gzip voi olla voitto kaiken tekstin (tai muuten erittäin hyvin pakattavissa) käyttötapauksissa, mutta johtaa usein prosessorin pullonkauloihin muuten – käytä varoen, erityisesti korkeammilla tasoilla.
- LZJB on alkuperäinen ZFS:n käyttämä algoritmi. Se on vanhentunut, eikä sitä pitäisi enää käyttää – LZ4 on ylivoimainen kaikilla mittareilla.
- ZLE on Zero Level Encoding (nollatason koodaus) – se jättää normaalin datan kokonaan rauhaan, mutta pakkaa suuret nollasarjat. Hyödyllinen täysin pakkaamattomille tietokokonaisuuksille (esim. JPEG, MP4 tai muut jo pakatut formaatit), koska se ei huomioi pakkaamatonta dataa, mutta pakkaa lopullisten tietueiden löysän tilan.
Suosittelemme LZ4-pakkausta lähes kaikkiin kuviteltavissa oleviin käyttötapauksiin; suorituskyvyn heikkeneminen, kun se kohtaa pakkaamatonta dataa, on hyvin pientä ja suorituskyvyn paraneminen tyypillisessä datassa on merkittävää. VM-kuvan kopiointi uuden Windows-käyttöjärjestelmän asennusta varten (vain asennettu Windows-käyttöjärjestelmä, ei vielä dataa) sujui 27 % nopeammin compression=lz4:llä kuin compression=none:llä tässä vuoden 2015 testissä.
ARC-the Adaptive Replacement Cache
ZFS on ainoa tuntemamme nykyaikainen tiedostojärjestelmä, joka käyttää omaa lukuvälimuistimekanismia sen sijaan, että se luottaisi käyttöjärjestelmänsä sivuvälimuistiin pitämään kopioita hiljattain luetuista lukulohkoista RAM-muistissa itselleen.
Vaikka erillisessä välimuistimekanismissa on ongelmansa – ZFS ei voi reagoida uusiin pyyntöihin varata muistia yhtä välittömästi kuin ydin voi, ja siksi uusi mallocate()kutsu voi epäonnistua, jos se tarvitsisi ARC:n tällä hetkellä varattua RAM-muistia – on ainakin toistaiseksi hyvä syy sietää sitä.
Jokainen tunnettu nykyaikainen käyttöjärjestelmä – mukaan lukien MacOS, Windows, Linux ja BSD – käyttää LRU-algoritmia (Least Recently Used) sivuvälimuistin toteutuksessa. LRU on naiivi algoritmi, joka nostaa välimuistissa olevan lohkon jonon ”yläpäähän” joka kerta, kun se luetaan, ja häätää lohkoja jonon ”alapäästä” tarpeen mukaan, jotta ”yläpäähän” saadaan lisättyä uusia välimuistista puuttuvia lohkoja (lohkoja, jotka jouduttiin lukemaan levyltä eikä välimuistista).”
Tämä on sikäli hyvä, että se toimii, mutta järjestelmissä, joissa on suuria työtietoaineistoja, LRU voi helposti päätyä ”thrashingiin” eli hyvin usein tarvittavien lohkojen poistamiseen, jotta saadaan tilaa lohkoille, joita ei enää koskaan lueta välimuistista.
ARC on paljon vähemmän naiivi algoritmi, jota voidaan ajatella ”painotettuna” välimuistina. Joka kerta, kun välimuistissa oleva lohko luetaan, siitä tulee hieman ”raskaampi” ja vaikeampi häätää – ja häädön jälkeenkin häädettyä lohkoa seurataan jonkin aikaa. Lohko, joka on häädetty, mutta joka on sen jälkeen luettava takaisin välimuistiin, muuttuu myös ”raskaammaksi” ja vaikeammaksi häätää.
Lopputuloksena tästä kaikesta on välimuisti, jolla on tyypillisesti paljon suuremmat osumissuhteet – välimuistin osumien eli välimuistitapahtumien (välimuistista suoritettujen lukukertojen) ja välimuistitapahtumiin kohdistuvien hukattujen lukukertojen (levyltä suoritettujen lukukertojen) suhde. Tämä on erittäin tärkeä tilasto – paitsi että välimuistin osumat palvellaan suuruusluokkaa nopeammin, myös välimuistin missejä voidaan palvella nopeammin, koska enemmän osumia välimuistissa = vähemmän samanaikaisia pyyntöjä levylle = pienempi viive niille jäljelle jääville misseille, jotka on palveltava levyltä.
Johtopäätös
Nyt kun olemme käsitelleet ZFS:n perussemantiikkaa – kuinka copy-on-write toimii ja poolien, vdev:iden, lohkojen, sektoreiden ja tiedostojen väliset suhteet – olemme valmiita puhumaan todellisesta suorituskyvystä oikeiden numeroiden avulla.
Olkaa kuulolla tallennuksen perusteet -sarjamme seuraavassa osassa, jossa tarkastelemme peili- ja RAIDz-vdev:tä käyttävien poolien todellista suorituskykyä verrattuna toisiinsa ja perinteisiin Linux-ytimen RAID-topologioihin, joita tarkastelimme aiemmin.
Aluksi käsittelemme vain perusasioita – itse ZFS-topologioita – mutta sen jälkeen olemme valmiita puhumaan edistyneemmistä ZFS-asetuksista ja -virityksistä, mukaan lukien tukivevien vdev-tyyppien, kuten L2ARC:n, SLOG:n ja erikoisallokaation, käytöstä.