
Amint mindannyian belépünk a COVID-19 járvány harmadik hónapjába, és új projekteket keresünk, amelyekkel leköthetjük magunkat (értsd: épelméjűek), érdekelne, hogy megtanuljuk a számítógépes tárolás alapjait? Idén tavasszal csendben már átvettünk néhány szükséges alapismeretet, például azt, hogyan teszteljük a lemezek sebességét, és mi a fene az a RAID. A második ilyen történetben még egy folytatást is ígértünk, amelyben a különböző többlemezes topológiák teljesítményét vizsgáljuk a ZFS-ben, a következő generációs fájlrendszerben, amelyről már hallottatok, mivel az Apple-től az Ubuntu-ig mindenhol megjelenik.
Nos, ma eljött a nap, hogy felfedezzétek, ZFS-kíváncsi olvasók. Csak tudjátok előre, hogy az OpenZFS fejlesztőjének, Matt Ahrensnek a visszafogott szavaival élve: “ez nagyon bonyolult.”
De mielőtt rátérnénk a számokra – és jönnek, ígérem!-a nyolc lemeznyi ZFS alakításának minden módjáról, beszélnünk kell arról, hogy a ZFS egyáltalán hogyan tárolja az adatokat a lemezen.
Zpoolok, vdev-k és eszközök
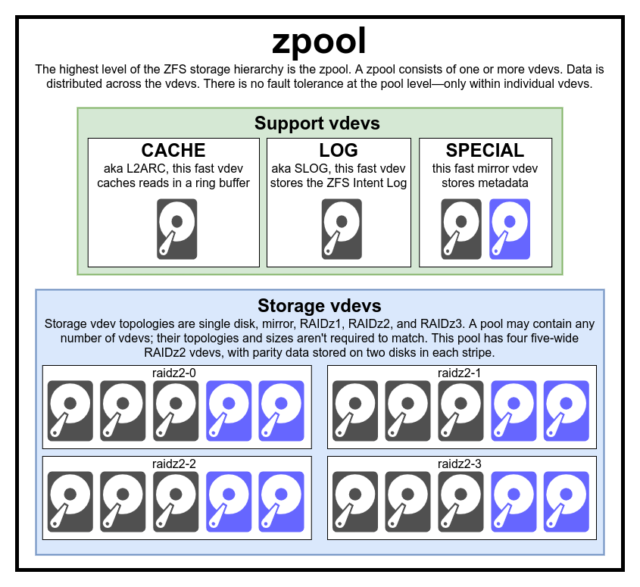

Hogy igazán megértsük a ZFS-t, valódi figyelmet kell fordítanunk a tényleges felépítésére. A ZFS egyesíti a hagyományos kötetkezelő és fájlrendszer rétegeket, és copy-on-write tranzakciós mechanizmust használ – mindkettő azt jelenti, hogy a rendszer szerkezetileg nagyon különbözik a hagyományos fájlrendszerektől és RAID tömböktől. Az első főbb építőelemek, amelyeket meg kell értenünk, a zpools, vdevs és devices.
zpool
A zpool a legfelső ZFS-struktúra. A zpool egy vagy több vdevs-t tartalmaz, amelyek mindegyike viszont egy vagy több devices-t tartalmaz. A zpoolok önálló egységek – egy fizikai számítógépen két vagy több különálló zpool is lehet, de mindegyik teljesen független a többitől. A zpoolok nem oszthatnak meg egymással vdevs-at.
A ZFS redundancia a vdev szinten van, nem a zpool szinten. A zpool szintjén egyáltalán nincs redundancia – ha bármelyik tároló vdev vagy SPECIAL vdev elveszik, az egész zpool elveszik vele együtt.
A modern zpoolok túlélik egy CACHE vagy LOG vdev elvesztését – bár egy kis mennyiségű piszkos adatot elveszíthetnek, ha egy LOG vdev áramkimaradás vagy rendszerösszeomlás során elveszik.
Egy gyakori tévhit, hogy a ZFS “csíkozza” az írásokat a poolon keresztül – de ez pontatlan. A zpool nem egy viccesen kinéző RAID0 – hanem egy viccesen kinéző JBOD, egy összetett elosztási mechanizmussal, amely változhat.
A legtöbb esetben az írások a rendelkezésre álló vdev-k között a rendelkezésre álló szabad helyüknek megfelelően kerülnek elosztásra, így elméletileg minden vdev egyszerre fog megtelni. A ZFS újabb verzióiban a vdev-kihasználtságot is figyelembe lehet venni – ha az egyik vdev jelentősen elfoglaltabb, mint a másik (pl.: olvasási terhelés miatt), akkor átmenetileg kihagyható az íráshoz, annak ellenére, hogy a legnagyobb arányban áll rendelkezésre szabad hely.
A modern ZFS írási elosztási módszerekbe épített kihasználtsági tudatossági mechanizmus csökkentheti a késleltetést és növelheti az átviteli sebességet a szokatlanul nagy terhelés időszakaiban – de nem szabad összekeverni azzal a szabadkártyával, hogy a lassú rozsdás lemezeket és a gyors SSD-ket akarva-akaratlanul keverjük ugyanabban a poolban. Egy ilyen össze nem illő pool általában még mindig úgy fog teljesíteni, mintha teljes egészében a jelenlévő leglassabb eszközből állna.
vdev
Minden zpool egy vagy több vdevs(a virtuális eszköz rövidítése) eszközből áll. Minden vdev viszont egy vagy több valós devices-ből áll. A legtöbb vdev egyszerű tárolásra szolgál, de számos speciális támogatási osztálya is létezik a vdev-nek – köztük a CACHE, LOG és SPECIAL. Mindegyik vdev-típus öt topológia egyikét kínálhatja – egy eszköz, RAIDz1, RAIDz2, RAIDz3 vagy tükör.
A RAIDz1, RAIDz2 és RAIDz3 a tárolási szürkeállományok által “diagonális paritású RAID”-nek nevezett speciális változatai. Az 1, 2 és 3 arra utal, hogy az egyes adatcsíkokhoz hány paritásblokk van hozzárendelve. Ahelyett, hogy teljes lemezeket dedikálnának a paritásnak, a RAIDz vdev-k a paritást félig egyenletesen osztják el a lemezek között. Egy RAIDz tömb annyi lemezt veszíthet el, ahány paritásblokkja van; ha még egyet elveszít, akkor meghibásodik, és magával viszi a zpool-t is.
A tükör vdev-k pontosan azok, aminek hangzanak – egy tükör vdev-ben minden blokk a vdev minden eszközén tárolódik. Bár a kétoldali tükrök a legelterjedtebbek, egy mirror vdev tetszőleges számú eszközt tartalmazhat – a nagyobb összeállításokban a nagyobb olvasási teljesítmény és a hibaállóság miatt gyakoriak a háromoldaliak. Egy tükrözött vdev bármilyen hibát túlélhet, amíg legalább egy eszköz a vdev-ben egészséges marad.
Az egyeszközös vdev-k is pontosan azok, aminek hangzanak – és eredendően veszélyesek. Az egyeszközös vdev nem képes túlélni semmilyen hibát – és ha tárolóként vagy SPECIAL vdev-ként használják, a hiba magával rántja az egész zpool vdev-et. Legyünk itt nagyon-nagyon óvatosak.
CACHE, LOG és SPECIAL vdev-ket a fenti topológiák bármelyikével létrehozhatunk – de ne feledjük, egy SPECIAL vdev elvesztése a pool elvesztését jelenti, ezért a redundáns topológia erősen ajánlott.
device
Ez talán a legkönnyebben érthető ZFS-hez kapcsolódó kifejezés – szó szerint csak egy véletlen hozzáférésű blokkeszköz. Ne feledjük, a vdevs egyedi eszközökből áll, a zpool pedig vdevs-ból.
A lemezek – akár rozsdásak, akár szilárdtestek – a leggyakrabban vdev építőelemként használt blokkeszközök. Bármi, aminek a /dev leírója lehetővé teszi a véletlenszerű hozzáférést, működni fog – így egész hardveres RAID tömbök használhatók (és néha használják is) egyedi eszközként.
Az egyszerű nyers fájl az egyik legfontosabb alternatív blokkeszköz, amiből egy vdev felépíthető. A sparse fájlokból készített tesztpoolok hihetetlenül kényelmes módja annak, hogy gyakoroljuk a zpool parancsokat, és megnézzük, mennyi hely áll rendelkezésre egy adott topológiájú poolon vagy vdev-n.

Tegyük fel, hogy egy nyolc rekeszes szerver építésén gondolkodik, és eléggé biztos benne, hogy 10 TB-os (~9300 GiB) lemezeket szeretne használni – de nem biztos benne, hogy milyen topológia felel meg leginkább az igényeinek. A fenti példában pillanatok alatt létrehozunk egy tesztpoolt ritka állományokból – és most már tudjuk, hogy egy nyolc 10 TB-os lemezből álló RAIDz2 vdev 50 TB hasznos kapacitást kínál.
A device-nek van egy speciális osztálya – az SPARE. A Hotspare eszközök a normál eszközökkel ellentétben a teljes poolhoz tartoznak, nem pedig egyetlen vdev-hoz. Ha a pool bármelyik vdev eszköze meghibásodik, és egy SPARE csatlakozik a poolhoz és elérhető, a SPARE automatikusan csatlakozik a meghibásodott vdev-hoz.
Amint csatlakozik a meghibásodott vdev-hoz, a SPARE elkezdi fogadni a hiányzó eszközön lévő adatok másolatait vagy rekonstrukcióit. A hagyományos RAID-ben ezt “újjáépítésnek” neveznénk – a ZFS-ben ezt “újraszerkesztésnek” hívják.”
Fontos megjegyezni, hogy az SPARE eszközök nem helyettesítik véglegesen a meghibásodott eszközöket. Ezek csak helytartók, amelyek célja, hogy minimalizálják azt az ablakot, amely alatt egy vdev degradáltan fut. Amint az admin lecserélte a vdev meghibásodott eszközét, és az új, állandó helyettesítő eszköz újraindul, az SPARE leválik a vdev-ről, és visszatér az egész poolra kiterjedő szolgálatba.
Adatkészletek, blokkok és szektorok
A következő építőelemek, amelyeket meg kell értenie a ZFS útja során, nem annyira a hardverhez, hanem magának az adatnak a szervezéséhez és tárolásához kapcsolódnak. Itt kihagyunk néhány szintet – például a metaszintet – annak érdekében, hogy a dolgok a lehető legegyszerűbbek legyenek, ugyanakkor az általános szerkezetet is megértsük.
Adatkészletek
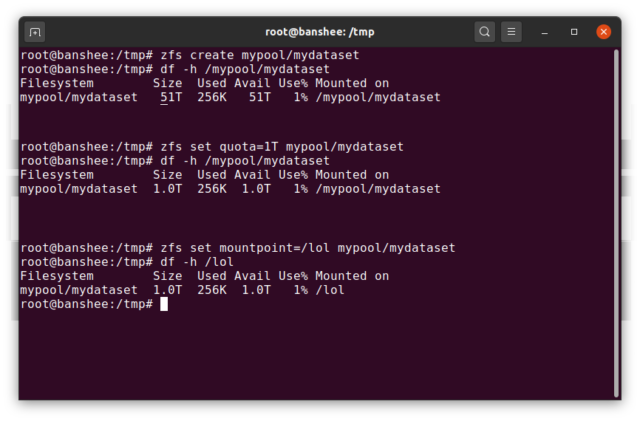

A ZFS dataset nagyjából analóg egy szabványos, felcsatolt fájlrendszerrel – mint egy hagyományos fájlrendszer, a felületes szemlélődés számára úgy tűnik, mintha “csak egy újabb mappa” lenne. De a hagyományos csatolt fájlrendszerekhez hasonlóan minden egyes ZFS dataset-nak saját mögöttes tulajdonságai vannak.
Először is, egy dataset-hoz hozzárendelhető kvóta. Ha zfs set quota=100G poolname/datasetname, akkor a rendszerbe szerelt /poolname/datasetname mappába
Észrevettük a fenti példában a vezető kötőjelek jelenlétét – és hiányát? Minden adatkészletnek megvan a helye mind a ZFS-hierarchiában, mind a rendszercsatlakoztatási hierarchiában. A ZFS-hierarchiában nincsenek vezető kötőjelek – a pool nevével kezdjük, majd az egyik adatkészlettől a másikig vezető útvonallal – pl. pool/parent/child egy child nevű adatkészlethez a parent szülő adatkészlet alatt, egy kreatívan pool nevű poolban.
Alapértelmezés szerint a dataset csatlakoztatási pontja megegyezik a ZFS hierarchikus nevével, egy vezető kötőjellel – a pool nevű pool a /pool, a parent adatkészlet a /pool/parent, a child gyermek adatkészlet pedig a /pool/parent/child címre van csatlakoztatva. Az adatkészlet rendszermountpontját azonban megváltoztathatjuk.
Ha zfs set mountpoint=/lol pool/parent/child lenne, akkor a pool/parent/child adatkészlet valójában /lol-ként lenne mountolva a rendszerbe.
Az adatkészleteken kívül meg kell említenünk a zvols-et is. A zvol nagyjából analóg a dataset-hoz, kivéve, hogy valójában nincs benne fájlrendszer – ez csak egy blokkeszköz. Létrehozhat például egy zvol-t mypool/myzvol néven, majd formázhatja az ext4 fájlrendszerrel, majd csatlakoztathatja ezt a fájlrendszert – most már van egy ext4 fájlrendszere, de a ZFS összes biztonsági funkciójával támogatva! Ez butaságnak tűnhet egy számítógépen – de sokkal több értelme van egy iSCSI-export háttértáraként.
Blocks
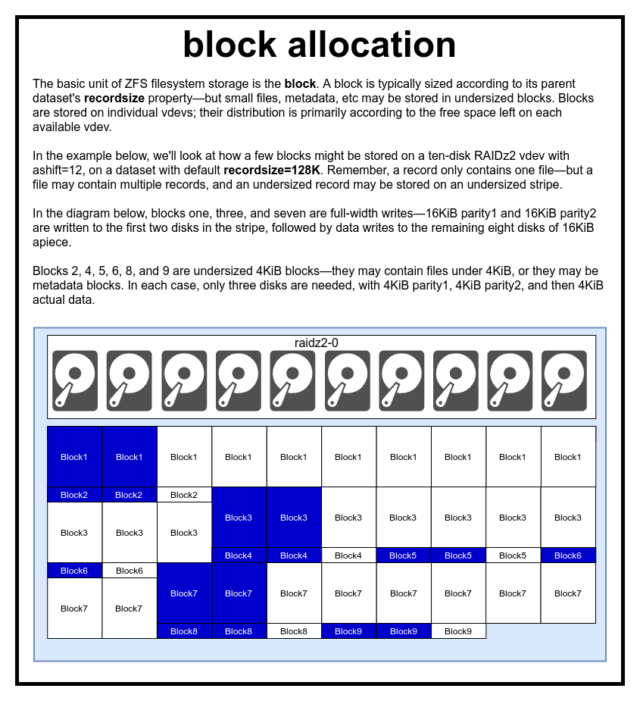

Egy ZFS-poolban minden adat – beleértve a metaadatokat is – a blocks-ben tárolódik. A block maximális mérete minden dataset esetében a recordsize tulajdonságban van meghatározva. A rekordméret változtatható, de a recordsize megváltoztatása nem változtatja meg az adatállományba már beírt blocks méretét vagy elrendezését – csak az új blokkok esetében, amikor azok beírásra kerülnek.
Ha nincs másként definiálva, a jelenlegi alapértelmezett recordsize 128KiB. Ez egyfajta kényelmetlen kompromisszumot jelent, amelyben a teljesítmény nem lesz ideális sok mindenhez, de nem is lesz szörnyű sok mindenhez. A Recordsize a 4K és 1M közötti bármely értékre beállítható. (A Recordsize további hangolással és kellő határozottsággal még nagyobbra is beállítható, de ez ritkán jó ötlet.)
Minden adott block csak egy fájl adataira hivatkozik – két különálló fájlt nem lehet egy block-be zsúfolni. Minden fájl egy vagy több blocks-ből áll, a mérettől függően. Ha egy fájl kisebb, mint recordsize, akkor egy alulméretezett blokkban lesz tárolva – például egy 2KiB-os fájlt tartalmazó block csak egyetlen 4KiB-os sector blokkot foglal el a lemezen.
Ha egy fájl elég nagy ahhoz, hogy több blocks-et igényeljen, akkor az azt tartalmazó összes rekord recordsize hosszúságú lesz – beleértve az utolsó rekordot is, amely többnyire üres hely lehet.
Zvols nem rendelkezik a recordsize tulajdonsággal – helyette volblocksize, ami nagyjából egyenértékű.
Sectors
Az utolsó tárgyalandó építőelem a szerény sector. A sector a legkisebb fizikai egység, amely a mögötte lévő device-be írható vagy onnan olvasható. Több évtizeden keresztül a legtöbb lemez 512 bájtos sectors-öt használt. Újabban a legtöbb lemez 4KiB sectors-t használ, és néhány – különösen az SSD-k – 8KiB sectors-t, vagy még nagyobbat.
A ZFS rendelkezik egy olyan tulajdonsággal, amely lehetővé teszi a sector méretének kézi beállítását, az úgynevezett ashift. Kissé zavaró módon a ashift valójában a bináris exponens, amely a szektor méretét jelöli – például a ashift=9 beállítása azt jelenti, hogy a sector mérete 2^9, azaz 512 bájt lesz.
A ZFS lekérdezi az operációs rendszert minden egyes device blokkról, amikor az egy új vdev-ba kerül, és elméletileg automatikusan megfelelően beállítja a ashift-t ezen információk alapján. Sajnos sok olyan lemez van, amelyik hazudik arról, hogy mekkora a sector mérete, hogy kompatibilis maradjon a Windows XP-vel (amely képtelen volt megérteni a más sector méretű lemezeket).
Ez azt jelenti, hogy a ZFS adminisztrátornak erősen ajánlott tisztában lennie a devices tényleges sector méretével, és manuálisan beállítani a ashift-t ennek megfelelően. Ha a ashift túl alacsonyan van beállítva, csillagászati olvasási/írási erősítési büntetés keletkezik – egy 512 bájtos “szektor” írása egy 4KiB valós sector-be azt jelenti, hogy ki kell írni az első “szektort”, majd ki kell olvasni a 4KiB sector-t, módosítani a második 512 bájtos “szektorral”, vissza kell írni egy *új* 4KiB sector-be, és így tovább, minden egyes írásnál.
A való világban ez az erősítési büntetés elég keményen sújt egy Samsung EVO SSD-t – amelynek ashift=13-nak kellene lennie, de hazudik a szektorméretéről, és ezért alapértelmezés szerint ashift=9, ha egy okos admin nem írja felül – ahhoz, hogy lassabbnak tűnjön, mint egy hagyományos rozsdás lemez.
Ezzel szemben a ashift túl magas beállítása gyakorlatilag nem jár büntetéssel. Nincs valódi teljesítménybüntetés, és a slack space növekedése végtelenül kicsi (vagy nulla, ha a tömörítés be van kapcsolva). Erősen javasoljuk, hogy még az 512 bájtos szektorokat valóban használó lemezeknél is ashift=12 vagy akár ashift=13 legyen beállítva a jövőbiztosítás érdekében.
A ashift tulajdonság per-vdev – nem pedig pool-onként, ahogy azt általában és tévesen gondolják – és megváltoztathatatlan, ha egyszer be van állítva. Ha véletlenül elrontod a ashift-t, amikor egy új vdev-t adsz hozzá egy poolhoz, akkor visszavonhatatlanul megfertőzted a poolt egy drasztikusan alulteljesítő vdev-val, és általában nincs más lehetőséged, mint megsemmisíteni a poolt és újrakezdeni. Még a vdev eltávolítása sem menthet meg egy elrontott ashift-beállítástól!
Copy-on-Write szemantika




CoW-Copy on Write – a ZFS nagy részének alapvető alapja. Az alapkoncepció egyszerű – ha egy hagyományos fájlrendszert arra kérsz, hogy helyben módosítson egy fájlt, az pontosan azt teszi, amit kértél tőle. Ha megkérsz egy copy-on-write fájlrendszert, hogy ugyanezt tegye meg, azt mondja, hogy “oké” – de hazudik neked.
Ehelyett a copy-on-write fájlrendszer kiírja az általad módosított block új verzióját, majd frissíti a fájl metaadatait, hogy megszüntesse a régi block linkjét, és összekapcsolja az új block-t, amit most írtál.
A régi block összekapcsolása és az új összekapcsolása egyetlen műveletben történik, így nem lehet megszakítani – ha a művelet után lemerül a táp, akkor a fájl új verziója van meg, ha pedig előtte, akkor a régi verzió. Mindig fájlrendszer-konzisztens vagy, mindkét esetben.
A ZFS-ben a copy-on-write nem csak a fájlrendszer szintjén van, hanem a lemezkezelés szintjén is. Ez azt jelenti, hogy a RAID-lyuk – egy olyan állapot, amikor egy csíkot csak részben írnak ki, mielőtt a rendszer összeomlik, ami a tömböt inkonzisztenssé és az újraindítás után sérültté teszi – nem érinti a ZFS-t. A csíkok írása atomikus, a vdev mindig konzisztens, és Bob a nagybácsi.
ZIL – a ZFS Intent Log
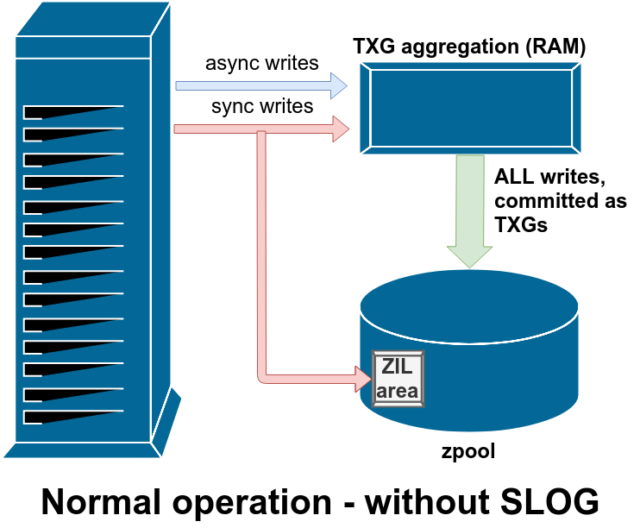

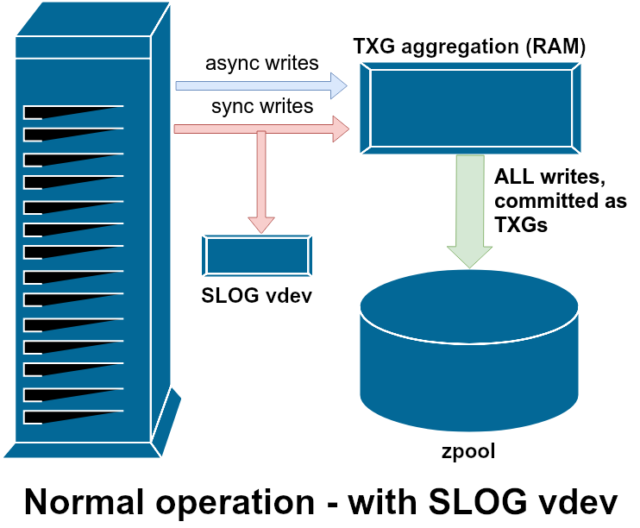

Az írási műveleteknek két fő kategóriája van – szinkron (sync) és aszinkron (async). A legtöbb munkaterhelés esetében az írási műveletek túlnyomó többsége aszinkron – a fájlrendszer összesítheti és kötegekben rögzítheti őket, csökkentve ezzel a töredezettséget és óriási mértékben növelve az átviteli sebességet.
A szinkronizált írások egy teljesen más állat – amikor egy alkalmazás szinkronizált írást kér, azt mondja a fájlrendszernek, hogy “ezt most kell rögzítened a nem illékony tárolóra, és amíg ezt nem teszed meg, addig nem tudok mást tenni”. A szinkronírásokat ezért azonnal le kell kötni a lemezre – és ha ez növeli a töredezettséget vagy csökkenti az átviteli sebességet, hát legyen.
A ZFS a szinkronírásokat a normál fájlrendszerektől eltérően kezeli – ahelyett, hogy a szinkronírásokat azonnal kiürítené a normál tárolóba, a ZFS a ZFS Intent Log vagy ZIL nevű speciális tárolási területre köti őket. A trükk itt az, hogy ezek az írások is a memóriában maradnak, a normál aszinkron írási kérésekkel együtt aggregálva, hogy később teljesen normális TXG-ként (Transaction Groups, tranzakciós csoportok) kiürüljenek a tárolóba.
A normál működés során a ZIL-be írnak, és soha többé nem olvasnak belőle. Amikor a ZIL-be mentett írásokat néhány pillanattal később normál TXG-kben a RAM-ból a főtárolóba commitolják, a ZIL-ről leválasztják őket. A ZIL-ből csak a pool importálásakor történik olvasás.
Ha a ZFS összeomlik – vagy az operációs rendszer összeomlik, vagy egy kezeletlen áramkimaradás történik -, miközben a ZIL-ben adatok vannak, akkor a következő pool importáláskor (pl. a lezuhant rendszer újraindításakor) az adatok kiolvasásra kerülnek. Ami a ZIL-ben van, az beolvasásra kerül, TXG-kbe aggregálódik, a főtárolóba kerül, majd az importálás során a ZIL-ből leválasztásra kerül.
A rendelkezésre álló vdev támogatási osztályok egyike a LOG– más néven SLOG vagy Secondary LOG eszköz. Az SLOG mindössze annyit tesz, hogy a pool számára egy külön – és remélhetőleg sokkal gyorsabb, nagyon nagy írási állóképességű – vdev-t biztosít a ZIL tárolására, ahelyett, hogy a ZIL-t a főtárolón tartaná vdevs. Minden tekintetben a ZIL ugyanúgy viselkedik, akár a főtárolón, akár egy LOG vdev-n van – de ha a LOG vdev nagyon nagy írási teljesítményű, akkor a szinkronizált írási visszatérések nagyon gyorsan megtörténnek.
Egy LOG vdev hozzáadása egy poolhoz egyáltalán nem tud és nem is fog közvetlenül javítani az aszinkron írási teljesítményen – még akkor sem, ha minden írást a ZIL-be kényszerítesz a zfs set sync=always használatával, akkor is ugyanúgy és ugyanolyan ütemben kerülnek a TXG-kben a főtárolóra, mint ahogyan a LOG nélkül is történne. Az egyetlen közvetlen teljesítményjavulás a szinkron írási késleltetésre vonatkozik (mivel a LOG nagyobb sebessége lehetővé teszi, hogy a sync hívás gyorsabban térjen vissza).
Egy olyan környezetben azonban, amely már sok szinkron írást igényel, a LOG vdev közvetve gyorsíthatja az aszinkron írásokat és a nem gyorsított olvasásokat is. A ZIL-írások külön LOG vdev-re való áthelyezése kevesebb versenyt jelent az IOPS-ért az elsődleges tárolón, ezáltal bizonyos mértékig növeli az összes olvasás és írás teljesítményét.
Snapshotok
A copy-on-write szemantika a ZFS atomi pillanatfelvételek és az inkrementális aszinkron replikáció szükséges alapját is képezi. Az élő fájlrendszer rendelkezik egy mutatófával, amely az összes records aktuális adatot tartalmazó records-t jelöli – amikor pillanatfelvételt készítünk, egyszerűen másolatot készítünk erről a mutatófáról.
Amikor egy rekordot felülírunk az élő fájlrendszerben, a ZFS először a block új verzióját írja a kihasználatlan helyre. Ezután eltávolítja a block régi verzióját az aktuális fájlrendszerből. De ha bármelyik snapshot hivatkozik a régi block-re, az továbbra is megváltoztathatatlan marad. A régi block valójában nem lesz visszavéve szabad helyként, amíg az összes snapshots, amely erre a block-re hivatkozik, meg nem semmisül!
Replikáció

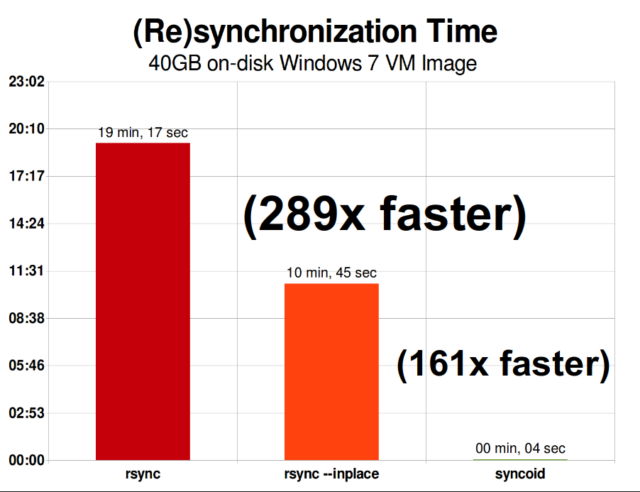
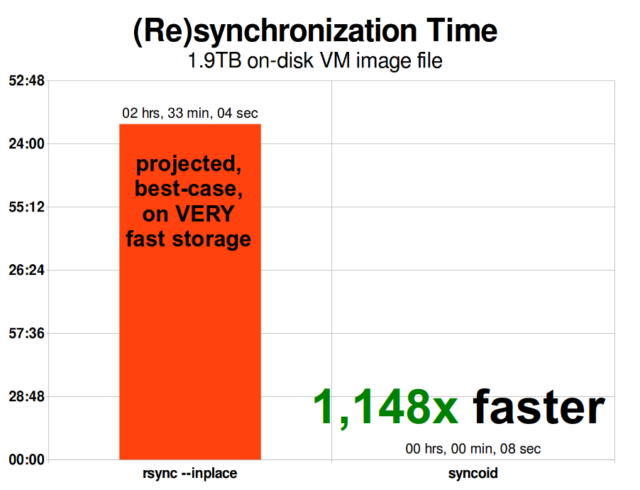 Ha megértetted, hogyan működnek a pillanatfelvételek, akkor a replikáció megértéséhez is jó helyen vagy. Mivel egy pillanatkép egyszerűen egy
Ha megértetted, hogyan működnek a pillanatfelvételek, akkor a replikáció megértéséhez is jó helyen vagy. Mivel egy pillanatkép egyszerűen egy records mutatókból álló fa, ebből következik, hogy ha zfs send egy pillanatképet készítünk, akkor elküldjük ezt a fát és a hozzá tartozó összes rekordot is. Amikor ezt a zfs send-t a célon lévő zfs receive-be csövezzük, az mind a tényleges block tartalmát, mind a blocks-re utaló mutatók fáját a céladatkészletbe írja.
A második zfs send-nél már érdekesebbé válnak a dolgok. Most, hogy már két rendszered van, amelyek mindegyike tartalmazza a poolname/datasetname@1 pillanatfelvételt, készíthetsz egy új, poolname/datasetname@2 pillanatfelvételt. Tehát a forráspoolon van datasetname@1 és datasetname@2, a célpoolon pedig eddig csak az első pillanatkép – datasetname@1.
Mivel van egy közös pillanatképünk a forrás és a cél között – datasetname@1 -, építhetünk rá egy inkrementális zfs send-et. Amikor megkérjük a rendszert, hogy zfs send -i poolname/datasetname@1 poolname/datasetname@2, összehasonlítja a két mutatófát. Minden olyan mutató, amely csak a @2-ben létezik, nyilvánvalóan az új blocks-re hivatkozik – így szükségünk lesz ezeknek a blocks-eknek a tartalmára is.
A távoli rendszeren az így kapott inkrementális send bepipálása hasonlóan egyszerű. Először kiírjuk az összes új records-t, amely a send folyamban szerepel, majd beillesztjük az ezekre a blocks-re mutató mutatókat. Presto, megvan a @2 az új rendszeren!
A ZFS aszinkron inkrementális replikáció óriási előrelépés a korábbi, nem pillanatfelvétel-alapú technikákhoz képest, mint például a rsync. Mindkét esetben csak a megváltozott adatokat kell átküldeni a vezetéken – de a rsync-nek először mindkét oldalon be kell olvasnia az összes adatot a lemezről az ellenőrző összegzéshez és az összehasonlításhoz. Ezzel szemben a ZFS replikációnak nem kell mást beolvasnia, csak a mutatófákat – és minden blocks, amit ez a mutatófa tartalmaz, és ami még nem volt jelen a közös pillanatfelvételben.
Inline tömörítés
A copy-on-write szemantika megkönnyíti az inline tömörítést is. Egy hagyományos fájlrendszerrel, amely helyben történő módosítást kínál, a tömörítés problematikus – a módosított adatok régi és új verziójának is pontosan ugyanarra a helyre kell beférnie.
Ha egy fájl közepén lévő adatdarabot tekintünk, amely 1MiB nullával kezdi életét –0x00000000 ad nauseam -, nagyon könnyen egyetlen lemezszektorba tömörülne. De mi történik, ha ezt az 1MiB nullát 1MiB tömöríthetetlen adatra cseréljük, például JPEG vagy pszeudo-véletlenszerű zajra? Hirtelen ennek az 1MiB adatnak 256 4KiB-os szektorra van szüksége, nem csak egyre – és a fájl közepén lévő lyuk csak egy szektor széles.
A ZFS-nek nincs ilyen problémája, mivel a módosított rekordok mindig a kihasználatlan helyre íródnak – az eredeti block csak egyetlen 4KiB sector-ot foglal el, az új rekord pedig 256-ot, de ez nem probléma – az újonnan módosított darabka a fájl “közepéről” a kihasználatlan helyre íródott volna, akár változott a mérete, akár nem, így a ZFS számára ez a “probléma” csak egy újabb nap az irodában.
A ZFS inline tömörítése alapértelmezés szerint ki van kapcsolva, és csatlakoztatható algoritmusokat kínál – jelenleg az LZ4, a gzip (1-9), az LZJB és a ZLE is.
- Az LZ4 egy stream algoritmus, amely rendkívül gyors tömörítést és kicsomagolást kínál, és a legtöbb felhasználási esetben – még nagyon vérszegény CPU-k esetén is – teljesítménygyőzelmet jelent.
- A GZIP a tiszteletre méltó algoritmus, amelyet minden Unix-szerű felhasználó ismer és szeret. Az 1-9. tömörítési szintekkel valósítható meg, a tömörítési arány és a CPU-használat a 9. szinthez közeledve növekszik. A Gzip előnyös lehet minden szöveges (vagy egyébként rendkívül tömöríthető) felhasználási esetben, de egyébként gyakran CPU-szűk keresztmetszetet eredményez – különösen a magasabb szinteken óvatosan használjuk.
- Az LZJB a ZFS által használt eredeti algoritmus. Elavult, és a továbbiakban nem szabad használni – a LZ4 minden szempontból jobb.
- A ZLE a Zero Level Encoding – a normál adatokat teljesen békén hagyja, de a nagy nullasorozatokat tömöríti. Hasznos a teljesen tömöríthetetlen adathalmazoknál (pl. JPEG, MP4 vagy más, már tömörített formátumok), mivel figyelmen kívül hagyja a tömöríthetetlen adatokat, de tömöríti a végső rekordok üres helyét.
Az LZ4 tömörítést szinte minden elképzelhető felhasználási esetre ajánljuk; a tömöríthetetlen adatokkal való találkozáskor a teljesítményveszteség nagyon kicsi, és a tipikus adatoknál a teljesítménynövekedés jelentős. Egy VM-kép másolása egy új Windows operációs rendszer telepítéséhez (csak a telepített Windows operációs rendszer, még nem voltak rajta adatok) 27%-kal gyorsabban ment a compression=lz4-vel, mint a compression=none-vel ebben a 2015-ös tesztben.
ARC-the Adaptive Replacement Cache
A ZFS az egyetlen általunk ismert modern fájlrendszer, amely saját olvasási gyorsítótár-mechanizmust használ, és nem az operációs rendszer lapozó gyorsítótárára támaszkodik, hogy a nemrég olvasott blokkok másolatait a RAM-ban tartsa számára.
Bár a külön cache-mechanizmusnak megvannak a maga problémái – a ZFS nem tud olyan azonnal reagálni az új memóriafoglalási kérésekre, mint a kernel, és ezért egy új mallocate()hívás sikertelen lehet, ha az ARC által éppen elfoglalt RAM-ra lenne szüksége -, jó okunk van, legalábbis egyelőre, hogy elviseljük.
Minden ismert modern operációs rendszer – beleértve a MacOS-t, a Windows-t, a Linuxot és a BSD-t – az LRU (Least Recently Used) algoritmust használja a lap gyorsítótár megvalósításához. Az LRU egy naiv algoritmus, amely a gyorsítótárban tárolt blokkot minden egyes olvasáskor a várólista “tetejére” emeli, és szükség szerint kiüríti a várólista “aljáról” a blokkokat, hogy a “tetejére” új gyorsítótár-kihagyások (olyan blokkok, amelyeket nem a gyorsítótárból, hanem a lemezről kellett olvasni) kerüljenek.”
Ez eddig rendben van, de a nagy munkaadat-halmazokkal rendelkező rendszerekben az LRU könnyen a “thrashing” végére juthat – a nagyon gyakran szükséges blokkok kiiktatása, hogy helyet csináljon olyan blokkoknak, amelyeket soha többé nem olvasnak a gyorsítótárból.
Az ARC egy sokkal kevésbé naiv algoritmus, amelyet “súlyozott” gyorsítótárként lehet elképzelni. Minden egyes alkalommal, amikor egy cache-blokkot olvasnak, az egy kicsit “nehezebbé” és nehezebben kilakoltathatóvá válik – és még a kilakoltatás után is egy ideig nyomon követhető a kilakoltatott blokk. Egy kilakoltatott blokk, amelyet aztán vissza kell olvasni a gyorsítótárba, szintén “nehezebbé” és nehezebben kilakoltathatóvá válik.
Mindennek a végeredménye egy olyan gyorsítótár, amelynek jellemzően sokkal nagyobb a találati aránya – a gyorsítótár találatai (a gyorsítótárból kiszolgált olvasások) és a gyorsítótár kihagyásai (a lemezről kiszolgált olvasások) közötti arány. Ez egy rendkívül fontos statisztika – nem csak maguk a cache-találatok kiszolgálása történik nagyságrendekkel gyorsabban, hanem a cache-kihagyások is gyorsabban kiszolgálhatók, mivel több cache-találat==kevesebb egyidejű kérés a lemezhez==kisebb késleltetés a lemezről kiszolgálandó hiányzásoknál.
Végkövetkeztetés
Most, hogy lefedtük a ZFS alapvető szemantikáját – hogyan működik az írás utáni másolás, valamint a poolok, vdev-k, blokkok, szektorok és fájlok közötti kapcsolatok – készen állunk arra, hogy a tényleges teljesítményről beszéljünk, valós számokkal.
Maradjanak velünk a tárolás alapjai sorozatunk következő részében, hogy megnézzük a tükrözött és RAIDz vdev-ket használó poolok tényleges teljesítményét, összehasonlítva mind egymással, mind a korábban vizsgált hagyományos Linux kernel RAID topológiákkal.
Először csak az alapokkal foglalkozunk – magukkal a ZFS topológiákkal -, de utána készen állunk arra, hogy beszéljünk a fejlettebb ZFS beállításról és hangolásról, beleértve az olyan támogató vdev típusok használatát, mint az L2ARC, SLOG és Special Allocation.