
COVID-19 パンデミックの 3 ヶ月目に入り、私たちを夢中にさせる(正気を保つ)新しいプロジェクトを探す中で、コンピュータ ストレージの基本を学ぶことに興味はありませんか? この春、私たちはすでにディスクの速度をテストする方法やRAIDとは何かなど、必要な基礎知識を静かに学んできました。 Apple から Ubuntu まで、あらゆるところに登場する次世代ファイルシステムである ZFS のさまざまな複数ディスク トポロジーのパフォーマンスについて、その続報をお届けすることをお約束しました。 OpenZFS 開発者の Matt Ahrens の控えめな言葉ですが、「本当に複雑なんだ」と前もって知っておいてください。-ZFS を本当に理解するには、その実際の構造に注意を払う必要があります。 ZFS は伝統的なボリューム管理とファイルシステムのレイヤーを統合し、コピーオンライトのトランザクションのメカニズムを使用しますが、これらは両方ともシステムが従来のファイルシステムや RAID アレイとは構造的に非常に異なることを意味します。 理解すべき主要な構成要素の最初のセットは、zpools、vdevs、および devices です。
zpool
zpool は最上位にある ZFS 構造です。 zpoolは1つまたは複数のvdevsを含み、それぞれが1つまたは複数のdevicesを順に含みます。 Zpoolは自己完結型のユニットで、物理コンピュータには2つ以上の別々のZpoolがありますが、各Zpoolは他のどのZpoolからも完全に独立しています。 Zpool は互いに vdevs を共有できません。
ZFS の冗長性は zpool レベルではなく、vdev レベルにあります。 zpool レベルでの冗長性はまったくなく、ストレージ vdev または SPECIAL vdev のいずれかが失われた場合、zpool 全体も一緒に失われます。
最近の zpool は、CACHE または LOG vdev の損失にも耐えられます-停電やシステムクラッシュ時に LOG vdev を失うと、少量のダーティデータを失う可能性はありますが。 zpool は、変更される可能性のある複雑な分散メカニズムを持つ、おかしな形の RAID0 ではなく、おかしな形の JBOD です。
ほとんどの場合、書き込みは、利用可能な空き領域に従って、利用可能な vdev に分散され、理論的にはすべての vdev が同時に満杯になります。 より最近のバージョンの ZFS では、vdev の使用率も考慮されるかもしれません – 1 つの vdev が他の vdev よりも著しく忙しい場合 (例: 読み込み負荷のため)、利用できる空き領域の比率が最も高くても、書き込み用に一時的にスキップされるかもしれません。
最近の ZFS 書込み分散方法に組み込まれた利用認識メカニズムは、異常に高い負荷の期間中に待ち時間を減らし、スループットを増加させますが、同じプール内に遅い錆ディスクと速い SSD を無差別に混合する白紙委任と勘違いしてはいけません。 このような不一致のプールは、一般に、現在最も遅いデバイスで完全に構成されているかのように動作します。
vdev
各zpoolは、1 つまたは複数の vdevs(仮想デバイスの略)で構成されています。 各vdevは順番に1つ以上の実devicesで構成されます。 これらの vdev タイプのそれぞれは、シングルデバイス、RAIDz1、RAIDz2、RAIDz3、またはミラーの 5 つのトポロジのうちの 1 つを提供することができます。 1、2、3 は、各データ ストライプに割り当てられるパリティ ブロックの数を表します。 ディスク全体をパリティ専用にするのではなく、RAIDz vdev はパリティをディスクに半 均的に分散させます。 RAIDz アレイはパリティブロックの数だけディスクを失う可能性がありますが、別のディスクを失うと失敗し、zpool を一緒に破壊してしまいます。 2幅のミラーが最も一般的ですが、ミラーvdevは任意の数のデバイスを含むことができ、より高い読み取り性能と耐障害性のために、より大きなセットアップで3幅が一般的です。 ミラー vdev は、vdev 内の少なくとも 1 つのデバイスが健全である限り、どのような障害にも耐えることができます。 単一デバイス vdev はいかなる障害にも耐えることができず、それがストレージまたは SPECIAL vdev として使用されている場合、その障害は zpool 全体を巻き込むことになります。
CACHE、LOG、および SPECIAL vdev は上記のどのトポロジーでも作成できますが、SPECIAL vdev の損失はプールの損失を意味しますので、冗長トポロジーを強くお勧めします。
device
これはおそらく、ZFS 関連の用語として最も理解しやすく、文字通りランダムアクセスブロックデバイスというだけのことです。 vdevs は個々のデバイスで構成され、zpool は vdevs で構成されることを覚えておいてください。
ディスク(ラストまたはソリッドステート)は、vdev 構成ブロックとして最も一般的に使用されるブロックデバイスです。 しかし、ランダムアクセスを許可する /dev の記述子を持つものなら何でも動作するため、ハードウェア RAID アレイ全体が個々のデバイスとして使用されることもあります (そして時にはそうなることもあります)。 スパース ファイルから作られたテスト プールは、zpool コマンドを練習したり、特定のトポロジーのプールまたは vdev で利用可能なスペースがどのくらいかを確認したりするのに非常に便利な方法です。
8 ベイ サーバーの構築を考えていて、10TB (~9300 GiB) ディスクの使用を確信しているが、ニーズに最も適したトポロジーが分からないとしましょう。 上の例では、スパースファイルからテストプールを数秒で構築し、8 つの 10TB ディスクで構成される RAIDz2 vdev が 50TiB の使用可能容量を提供することがわかりました。 Hotspare デバイスは、通常のデバイスとは異なり、単一の vdev ではなくプール全体に属します。 プール内の vdev のいずれかにデバイスの障害が発生し、SPARE がプールに接続されていて使用可能な場合、SPARE は自動的に劣化した vdev に接続されます。 従来の RAID では、これは「再構築」と呼ばれ、ZFS では「再銀化」と呼ばれます。
注意すべきは、SPARE デバイスが故障したデバイスを永久に置き換えるわけではないことです。 これは単なるプレースホルダーで、vdev がデグレードしている間のウィンドウを最小にすることを目的としています。 管理者が vdev の故障したデバイスを交換し、新しい永久的な交換デバイスが回復したら、SPARE は vdev から自身を切り離し、プール全体の任務に戻ります。
データセット、ブロック、セクタ
ZFS の旅で理解すべき次の構成要素は、ハードウェアではなく、データ自体がどのように整理されて保存されているかに関連しています。 ここでは、全体的な構造を理解しつつ、できるだけ物事をシンプルに保つために、メタスラブなどいくつかのレベルをスキップします。
データセット
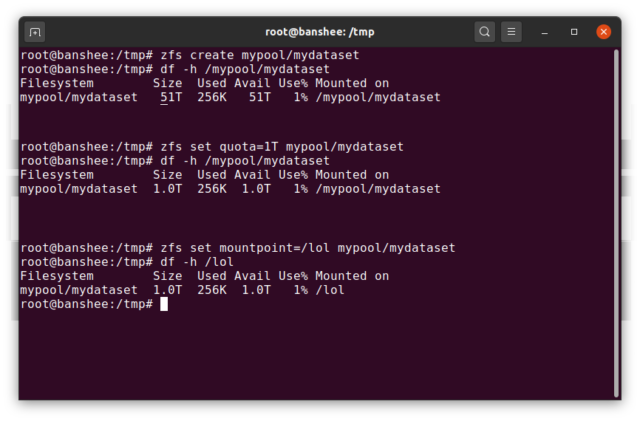

ZFS dataset は、標準マウント ファイルシステムに類似しています。 しかし、従来のマウントされたファイルシステムと同様に、各 ZFS dataset には、独自の一連の基本特性があります。
何よりもまず、dataset にはクォータが割り当てられることがあります。 zfs set quota=100G poolname/datasetname の場合、システムにマウントされたフォルダー /poolname/datasetname に 100GiB を超えるデータを入れることはできません。
上の例で、先頭のスラッシュがあることとないことに注目しましたか? 各データセットには、ZFS階層とシステムマウント階層の両方における位置があります。 ZFS 階層構造では、先頭のスラッシュはありません。プール名から始めて、あるデータセットから次のデータセットへのパスを記述します。たとえば、pool という名前のプール内の親データセット parent の下の child というデータセットには pool/parent/child というパスが設定されています。
デフォルトでは、dataset のマウントポイントはその ZFS 階層名と同じになり、先頭にスラッシュが付きます – pool というプールは /pool、データセット parent は /pool/parent、子データセット child は /pool/parent/child にマウントされます。 しかし、データセットのシステムマウントポイントは変更できる。
仮にzfs set mountpoint=/lol pool/parent/childとすると、データセットpool/parent/childは実際には/lolとしてシステムにマウントされる。
データセットに加え、zvolsについても触れておく。 zvol は dataset とほぼ同じですが、実際にはファイルシステムを持っておらず、単なるブロックデバイスである点が異なります。 例えば、mypool/myzvol という名前の zvol を作成し、ext4 ファイルシステムでフォーマットし、そのファイルシステムをマウントすることができます。 これは、1 台のコンピュータでは馬鹿げているように聞こえるかもしれませんが、iSCSI エクスポートのバックエンドとしては、もっと理にかなっています。 blockの最大サイズは、datasetごとにrecordsizeプロパティで定義されます。 Recordsize は変更可能ですが、recordsize を変更しても、既にデータセットに書き込まれた blocks のサイズやレイアウトは変更されません。 これは、パフォーマンスがあまり理想的でないものの、あまりひどいものでもないという、ある種の不安な妥協点を表しています。 Recordsize には 4K から 1M までの任意の値を設定することができます。 (Recordsize は、追加のチューニングと十分な決定があればさらに大きく設定することもできますが、それは良いアイデアではありません。)
与えられた block は1つのファイルからのデータのみを参照します-同じ block に2つの別々のファイルを押し込めることはできません。 各ファイルは、サイズに応じて 1 つ以上の blocks で構成される。 例えば、2KiB のファイルを保持する block は、ディスク上の単一の 4KiB sector を占有するだけです。
複数の blocks を必要とするほどファイルが大きい場合、そのファイルを含むすべてのレコードは、最後のレコードを含めて recordsize 長さとなり、これはほとんど余白となるかもしれません。
Zvols は recordsize の特性を持っておらず、代わりに volblocksize があり、これはほぼ同等です。
Sectors
最後の構成要素として、卑しい sector について説明しましょう。 sector は、その下にある device に書き込んだり、そこから読み出したりできる最小の物理単位です。 数十年の間、ほとんどのディスクは512バイトのsectorsを使用していました。 最近では、ほとんどのディスクは 4KiB sectors を使用し、特に SSD では 8KiB sectors、またはそれ以上を使用します。
ZFS には、ashift という sector サイズを手動で設定するためのプロパティが用意されています。 たとえば、ashift=9 を設定すると、sector サイズは 2^9、つまり 512 バイトになります。
ZFS は新しい vdev に追加される各ブロック device についての詳細をオペレーティング システムに対して問い合わせ、その情報に基づいて自動的に ashift を適切に設定すると理論上ではなっています。 残念ながら、Windows XP (他の sector サイズのディスクを理解することができない) との互換性を保つために、sector サイズが何であるかについて、歯を食いしばって嘘をつくディスクがたくさんあります。
これは、ZFS 管理者が自分の devices の実際の sector サイズを認識し、それに応じて ashift を手動で設定することが強く推奨される、ということです。 512 バイトの「セクタ」を 4KiB の実際の sector に書き込むことは、最初の「セクタ」を書き込み、次に 4KiB sector を読み取り、2 番目の 512 バイトの「セクタ」で修正し、書き込みごとに *新しい* 4KiB sector に書き戻し、といった具合に、天文学的な読み取り/書き込みの増幅ペナルティが発生することを意味しています。
現実の世界では、この増幅ペナルティは Samsung EVO SSD (ashift=13 があるはずですが、そのセクタ サイズは嘘なので、経験豊富な管理者が上書きしない限り ashift=9 がデフォルトとなり、従来の錆びたディスクより遅く見えるほど厳しいものでした) に当たります。 実際のパフォーマンス上のペナルティはなく、スラックスペースの増加はごくわずかです(圧縮を有効にした場合はゼロ)。 本当に 512 バイトのセクタを使用するディスクであっても、将来のために ashift=12 または ashift=13 に設定することを強くお勧めします。
ashift プロパティはプール単位ではなく、vdev 単位であり、一度設定すれば変更できません。 プールに新しい vdev を追加する際に誤って ashift を失敗した場合、そのプールを性能の著しく低い vdev で取り返しのつかないほど汚染したことになり、通常、プールを破棄してやり直す以外に方法はありません。 vdev の削除でさえ、誤った ashift 設定からあなたを救うことはできません!
Copy-on-Write セマンティクス




CoW – Copy on Write – は ZFS が素晴らしい理由のほとんどの根底にある、基本的な土台となるものです。 基本的なコンセプトは単純で、従来のファイルシステムにファイルをインプレースで変更するよう依頼すると、依頼したとおりに正確に実行されます。 その代わり、コピーオンライト ファイルシステムは、変更した block の新しいバージョンを書き出し、ファイルのメタデータを更新して古い block のリンクを解除し、今書き込んだ新しい block をリンクします。
古いblockのリンク解除と新しいリンクは1つの操作で達成されるので、中断することはありません。 ZFS のコピーオンライトは、ファイルシステム レベルだけでなく、ディスク管理レベルでも行われます。 これは、RAID ホール (システムがクラッシュする前にストライプが部分的にしか書き込まれず、アレイが一貫性を失い、再起動後に破損する状態) が ZFS に影響を与えないことを意味します。 ストライプの書き込みはアトミックであり、vdev は常に一貫しており、Bob はあなたのおじさんです。
ZIL-the ZFS Intent Log
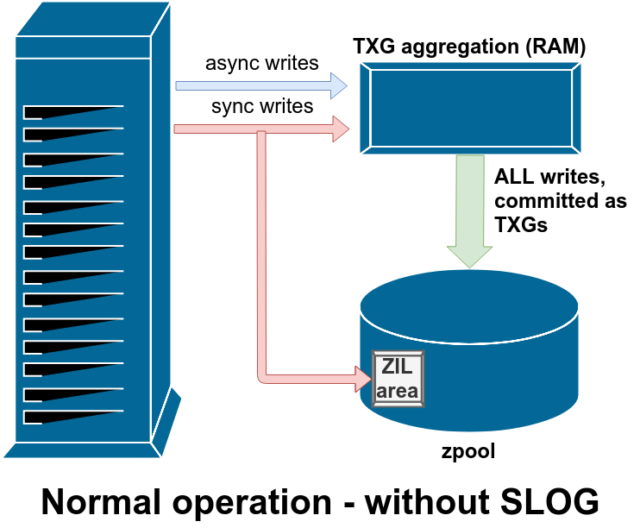


Write 操作には、同期 (sync) と非同期 (async) の 2 つの主要なカテゴリがあります。 ファイルシステムはそれらを集約してバッチでコミットすることができ、断片化を減らし、スループットを驚異的に向上させます。
同期書き込みはまったく別物です。 そのため、同期書き込みは直ちにディスクにコミットする必要があり、それによって断片化が進んだり、スループットが低下したりしても、それはそれで仕方がありません。 ここでのトリックは、これらの書き込みもメモリ内に残り、通常の非同期書き込み要求とともに集約され、後で完全に通常の TXG (Transaction Groups) としてストレージにフラッシュされることです。 ZIL に保存された書き込みが、数分後に通常の TXG で RAM からメイン ストレージにコミットされると、ZIL からアンリンクされます。 ZIL が読み出されるのは、プール インポート時のみです。
ZIL にデータがある間に ZFS がクラッシュした場合、またはオペレーティング システムがクラッシュした場合、または処理されない停電があった場合、そのデータは次のプール インポート時 (たとえば、クラッシュしたシステムが再起動したとき) に読み出されます。 ZIL にあるものはすべて読み込まれ、TXG に集約され、メイン ストレージにコミットされ、その後インポート プロセス中に ZIL からアンリンクされます。
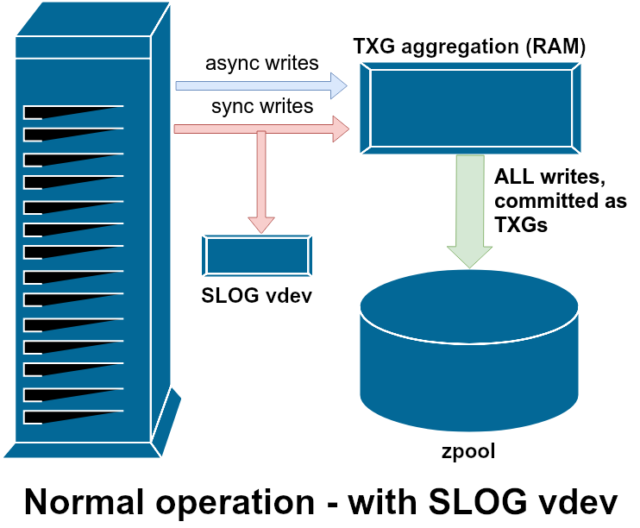
利用できるサポート vdev のクラスの 1 つに LOG– SLOG、または Secondary LOG デバイスとして知られているものがあります。 SLOG が行うことは、メイン ストレージ vdevs に ZIL を保持する代わりに、ZIL を格納するための独立した、できればはるかに高速で非常に高い書き込み耐久性を持つ vdev をプールに提供することだけです。 すべての点で、ZIL はメイン ストレージまたは LOG vdev のどちらにあっても同じ動作をしますが、LOG vdev が非常に高い書き込み性能を持つ場合、同期書き込みの復帰は非常に速く行われることになります。zfs set sync=always を使用してすべての書き込みを ZIL に強制した場合でも、LOG がなければ同じ方法、同じペースで、TXG のメイン ストレージにコミットされたままです。 しかし、すでに多くの同期書き込みを必要とする環境では、LOG vdev は間接的に非同期書き込みとキャッシュなし読み取りを高速化することができます。 ZIL ライトを別の LOG vdev にオフロードすることは、プライマリ ストレージでの IOPS の競合を減らし、それによってすべての読み取りと書き込みのパフォーマンスをある程度向上させることを意味します。 ライブ ファイルシステムには、現在のデータを含むすべての records をマークするポインタのツリーがあり、スナップショットを取るときは、単にそのポインタのツリーのコピーを作成します。
レコードがライブ ファイルシステムで上書きされると、ZFS は新しいバージョンの block を最初に未使用スペースに書き込みます。 その後、現在のファイルシステムから古いバージョンの block をアンリンクします。 しかし、いずれかの snapshot が古い block を参照している場合、それはまだ不変のままです。 古い block は、その block を参照しているすべての snapshots が破棄されるまで、実際には空き領域として取り戻されません!
レプリケーション

 スナップショットの仕組みを理解したら、レプリケーションを理解する良い機会になるでしょう。 スナップショットは単に
スナップショットの仕組みを理解したら、レプリケーションを理解する良い機会になるでしょう。 スナップショットは単に records へのポインタのツリーなので、スナップショットを zfs send した場合、そのツリーと関連するすべてのレコードの両方を送信することになります。 その zfs send をターゲットの zfs receive にパイプすると、実際の block のコンテンツと、blocks を参照するポインタのツリーの両方がターゲットのデータセットに書き込まれます。 2 つのシステムがあり、それぞれにスナップショット poolname/datasetname@1 が含まれているため、新しいスナップショット poolname/datasetname@2 を作成することができます。 ソース・プールには datasetname@1 と datasetname@2 があり、ターゲット・プールには今のところ最初のスナップショット datasetname@1 があります。 システムにzfs send -i poolname/datasetname@1 poolname/datasetname@2を要求すると、2つのポインタツリーが比較されます。 @2 にのみ存在するポインタは明らかに新しい blocks を参照しているので、それらの blocks の内容も必要になる。
リモートシステムにおいて、結果の増分 send に配管することも同様に簡単である。 まず、send ストリームに含まれるすべての新しい records を書き出し、次にそれらの blocks へのポインタを追加します。 その結果、新しいシステムで @2 が得られました。
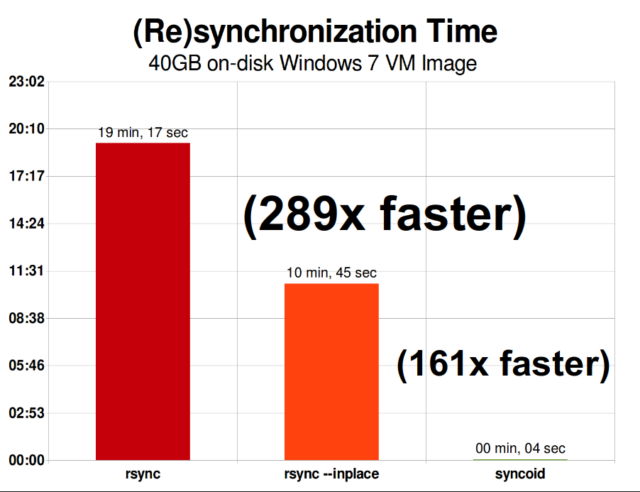
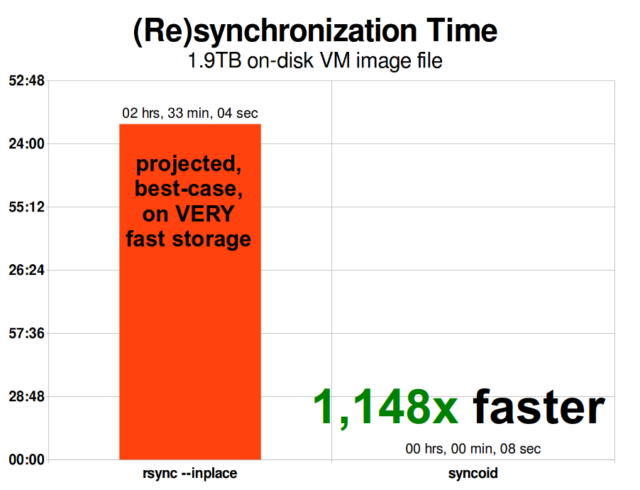
ZFS の非同期インクリメンタル レプリケーションは、rsync のようなスナップショット ベースではない以前の手法よりも大幅に改善されました。 どちらの場合も、変更されたデータのみをワイヤ上で送信する必要がありますが、rsync はチェックサムと比較を行うために、まず両側からすべてのデータをディスクから読み込む必要があります。 対照的に、ZFS レプリケーションでは、ポインター ツリーと、そのポインター ツリーが含む、共通のスナップショットにまだ存在しない blocks 以外は読み取る必要がありません。
インライン圧縮
Copy-on-write セマンティクスにより、インライン圧縮も容易に提供できるようになりました。 インプレース変更を提供する従来のファイルシステムでは、圧縮は問題です。変更されたデータの古いバージョンと新しいバージョンの両方が、まったく同じスペースに収まる必要があります。 しかし、この1ミリのゼロを1ミリの非圧縮データ、例えばJPEGや擬似ランダムノイズに置き換えたらどうなるだろうか。 突然、1MiBのデータは1セクタだけでなく256個の4KiBセクタを必要とし、ファイルの真ん中の穴は1セクタ幅だけになってしまうのです。
ZFS にはこの問題はありません。変更されたレコードは常に未使用領域に書き込まれるため、元の block は単一の 4KiB sector を占有するだけですが、新しいレコードはそのうちの 256 を占有するからです。
ZFS のインライン圧縮はデフォルトではオフで、プラグイン可能なアルゴリズムを提供しており、現在のところ LZ4、gzip (1-9)、LZJB、および ZLE が含まれています。 これは、圧縮レベル 1 ~ 9 で実装でき、レベルが 9 に近づくと圧縮比と CPU 使用率が増加します。 Gzip はすべてのテキスト (あるいは、極端に圧縮可能なもの) を使用する場合には有効ですが、そうでない場合にはしばしば CPU のボトルネックになります – 特に高いレベルでは注意して使用してください。 これは非推奨であり、もはや使用すべきではありません。
compression=none よりも compression=lz4 の方が 27% 速かったです。ARC-the Adaptive Replacement Cache
ZFS は、最近読んだブロックのコピーを RAM で保持するのに OS ページ キャッシュを利用せず、独自の読み取りキャッシュ機構を使用している唯一の最新ファイルシステムです。
別のキャッシュ機構には問題がありますが、ZFS はカーネルができるようにメモリを割り当てる新しい要求に即座に反応できないため、新しい mallocate() 呼び出しが ARC によって現在占有されている RAM を必要とする場合、失敗する可能性があります。
MacOS や Windows、Linux、BSD などのよく知られた最新のオペレーティング システムは、ページ キャッシュの実装に LRU (Least Recently Used) アルゴリズムを使用しています。 LRU は、キャッシュされたブロックが読み込まれるたびにキューの「先頭」に移動し、キューの「底」にあるブロックを必要に応じて退避させ、「先頭」に新しいキャッシュ ミス (キャッシュではなくディスクから読み込む必要があったブロック) を追加する、素朴なアルゴリズムです。「
これは、その限りでは良いのですが、大きな作業データ セットを持つシステムでは、LRU は簡単に「スラッシング」(二度とキャッシュから読み込まれないブロックのためのスペースを作るために、非常に頻繁に必要なブロックを退避させること)に終わる可能性があります。 キャッシュされたブロックが読み込まれるたびに、それは少し「重く」なり、立ち退きが難しくなります。立ち退き後も、立ち退いたブロックは一定期間追跡されます。 キャッシュから読み出されたブロックが再びキャッシュに読み込まれる場合も、「より重く」、より困難になります。
これらすべての最終結果は、通常、はるかに高いヒット率(キャッシュ ヒット(キャッシュからの読み取り)およびキャッシュ ミス(ディスクからの読み取り)間の比率)を有するキャッシュです。 キャッシュ ヒット数 = ディスクへの同時要求数 = ディスクから処理されなければならない残りのミスに対するレイテンシーが減少するためです。
結論
ここまでで、コピーオンライトの仕組みや、プール、vdev、ブロック、セクタ、ファイル間の関係など、ZFS の基本的なセマンティクスについて説明しましたが、次は実際のパフォーマンスについて、実際の数字を使って説明します。
最初は、ZFS トポロジーそのものという基本的なことを説明しますが、その後、L2ARC、SLOG、および特殊割り当てなどのサポート vdev タイプの使用など、より高度な ZFS セットアップとチューニングについて説明する準備が整うことでしょう。