
Terwijl we de derde maand van de COVID-19 pandemie ingaan en op zoek zijn naar nieuwe projecten om ons bezig te houden (lees: gezond te houden), kunnen we u interesseren in het leren van de basisprincipes van computeropslag? Rustig dit voorjaar, hebben we al een aantal noodzakelijke basisprincipes besproken, zoals hoe je de snelheid van je schijven test en wat RAID in hemelsnaam is. In het tweede van die verhalen beloofden we zelfs een vervolg waarin we de prestaties van verschillende meervoudige-schijf topologieën in ZFS onderzochten, het next-gen bestandssysteem waar je over gehoord hebt omdat het overal opduikt, van Apple tot Ubuntu.
Wel, vandaag is de dag om op onderzoek uit te gaan, ZFS-lezers nieuwsgierig. Maar weet van tevoren dat het, in de bescheiden woorden van OpenZFS-ontwikkelaar Matt Ahrens, “erg ingewikkeld is.”
Maar voordat we aan de cijfers toekomen – en die komen eraan, dat beloof ik!-voor alle manieren waarop u ZFS met acht schijven vorm kunt geven, moeten we het hebben over hoe ZFS uw gegevens überhaupt op de schijf opslaat.
Zpools, vdevs, en apparaten
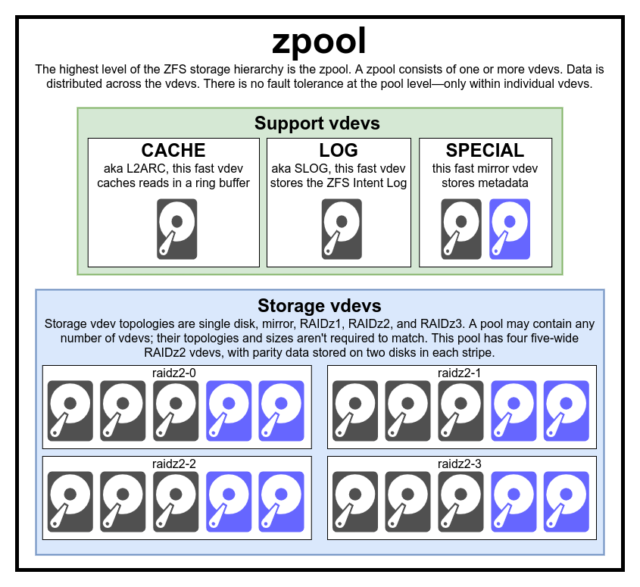

Om ZFS echt te begrijpen, moet u echt aandacht besteden aan de werkelijke structuur ervan. ZFS voegt de traditionele lagen voor volumebeheer en bestandssystemen samen en maakt gebruik van een transactiemechanisme voor kopiëren-opschrijven – beide betekenen dat het systeem structureel heel anders is dan conventionele bestandssystemen en RAID-arrays. De eerste set van belangrijke bouwstenen om te begrijpen zijn zpools, vdevs, en devices.
zpool
De zpool is de bovenliggende ZFS structuur. Een zpool bevat een of meer vdevs, die elk op hun beurt een of meer devices bevatten. Zpool’s zijn op zichzelf staande eenheden-één fysieke computer kan twee of meer aparte zpool’s bevatten, maar elke is volledig onafhankelijk van de andere. Zpools kunnen geen vdevs met elkaar delen.
ZFS redundantie is op het vdev niveau, niet op het zpool niveau. Er is absoluut geen redundantie op het zpool niveau-als een opslag vdev of SPECIAL vdev verloren gaat, gaat de hele zpool mee verloren.
Moderne zpools kunnen het verlies van een CACHE of LOG vdev overleven- hoewel ze een kleine hoeveelheid vuile gegevens kunnen verliezen, als ze een LOG vdev verliezen tijdens een stroomstoring of systeemcrash.
Het is een veel voorkomende misvatting dat ZFS “stripes” schrijft over de pool-maar dit is onjuist. Een zpool is geen grappig uitziende RAID0-het is een grappig uitziende JBOD, met een complex verdelingsmechanisme dat aan verandering onderhevig is.
Voor het grootste deel worden de schrijfacties verdeeld over de beschikbare vdev’s in overeenstemming met hun beschikbare vrije ruimte, zodat alle vdev’s theoretisch op hetzelfde moment vol zullen raken. In recentere versies van ZFS kan ook rekening worden gehouden met het gebruik van vdev’s – als een vdev beduidend drukker is dan een andere (bijv. door leesbelasting), kan deze tijdelijk worden overgeslagen om te schrijven, ook al heeft deze de hoogste verhouding vrije ruimte beschikbaar.
Het mechanisme van gebruiksbewustzijn dat is ingebouwd in moderne ZFS-schrijfdistributiemethoden kan latency verminderen en doorvoer verhogen tijdens perioden van ongewoon hoge belasting-maar het moet niet worden verward met carte blanche om langzame roestschijven en snelle SSD’s willens en wetens in dezelfde pool te mixen. Zo’n verkeerd samengestelde pool zal over het algemeen nog steeds presteren alsof hij volledig was samengesteld uit het langzaamste aanwezige apparaat.
vdev
Elke zpool bestaat uit een of meer vdevs (kort voor virtueel apparaat). Elke vdev bestaat op zijn beurt weer uit een of meer echte devices. De meeste vdev’s worden gebruikt voor gewone opslag, maar er bestaan ook verschillende speciale ondersteunende klassen van vdev’s, waaronder CACHE, LOG, en SPECIAL. Elk van deze vdev-types kan een van de vijf topologieën bieden-één-device, RAIDz1, RAIDz2, RAIDz3, of mirror.
RAIDz1, RAIDz2, en RAIDz3 zijn speciale variëteiten van wat opslag grijsaards “diagonale pariteit RAID” noemen. De 1, 2, en 3 verwijzen naar het aantal pariteitsblokken dat aan elke gegevensstrip wordt toegewezen. In plaats van volledige schijven te wijden aan pariteit, verdelen RAIDz vdevs die pariteit semi-gelijkmatig over de schijven. Een RAIDz array kan net zoveel schijven verliezen als het pariteitsblokken heeft; als het een andere verliest, faalt het, en neemt het zpool mee naar beneden.
Mirror vdevs zijn precies wat ze klinken als-in een mirror vdev, wordt elk blok opgeslagen op elk apparaat in de vdev. Hoewel twee-brede spiegels de meest voorkomende zijn, kan een mirror vdev een willekeurig aantal apparaten bevatten- drie-weg zijn gebruikelijk in grotere setups voor de hogere leesprestatie en foutbestendigheid. Een mirror vdev kan ieder falen overleven, zolang tenminste één apparaat in de vdev gezond blijft.
Single-device vdevs zijn ook precies waar ze op lijken-en ze zijn inherent gevaarlijk. Een single-device vdev kan geen enkele storing overleven- en als het wordt gebruikt als een opslag of SPECIAL vdev, zal het falen ervan de hele zpool mee naar beneden nemen. Wees zeer, zeer voorzichtig hier.
CACHE, LOG, en SPECIAL vdevs kunnen worden aangemaakt met behulp van elk van de bovenstaande topologieën-maar onthoud, verlies van een SPECIAL vdev betekent verlies van de pool, dus redundante topologie wordt sterk aangemoedigd.
device
Dit is waarschijnlijk de gemakkelijkste ZFS-gerelateerde term om te begrijpen-het is letterlijk gewoon een willekeurig-toegankelijk blok-apparaat. Onthoud, vdevs zijn gemaakt van individuele apparaten, en de zpool is gemaakt van vdevs.
Disks – roest of solid-state – zijn de meest voorkomende blok apparaten die worden gebruikt als vdev bouwstenen. Alles met een descriptor in /dev dat willekeurige toegang toestaat zal werken, hoewel-dus hele hardware RAID arrays kunnen (en worden soms) gebruikt als individuele apparaten.
Het eenvoudige ruwe bestand is een van de belangrijkste alternatieve blok apparaten waarvan een vdev kan worden gebouwd. Test pools gemaakt van sparse bestanden zijn een ongelooflijk handige manier om zpool commando’s te oefenen, en te zien hoeveel ruimte er beschikbaar is op een pool of vdev van een gegeven topologie.

Stel dat je erover denkt om een server met acht schijven te bouwen, en er vrij zeker van bent dat je schijven van 10 TB (~9300 GiB) wilt gebruiken, maar je weet niet zeker welke topologie het beste bij je behoeften past. In het bovenstaande voorbeeld bouwen we een testpool van sparse bestanden in seconden-en nu weten we dat een RAIDz2 vdev gemaakt van acht 10TB schijven 50TiB aan bruikbare capaciteit biedt.
Er is een speciale klasse van device-de SPARE. Hotspare apparaten, in tegenstelling tot normale apparaten, behoren tot de gehele pool, niet een enkele vdev. Als een vdev in de pool lijdt aan een apparaatdefect, en een SPARE is gekoppeld aan de pool en beschikbaar, zal de SPARE zichzelf automatisch koppelen aan de gedegradeerde vdev.
Eenmaal gekoppeld aan de gedegradeerde vdev, begint de SPARE kopieën of reconstructies te ontvangen van de gegevens die op het ontbrekende apparaat zouden moeten staan. In traditionele RAID, zou dit worden genoemd “rebuilding”-in ZFS, heet het “resilvering.”
Het is belangrijk op te merken dat SPARE apparaten niet permanent defecte apparaten vervangen. Het zijn slechts plaatshouders, bedoeld om het venster te minimaliseren waarin een vdev defect raakt. Zodra de beheerder het defecte apparaat van de vdev heeft vervangen en het nieuwe, permanente vervangingsapparaat opnieuw draait, maakt de SPARE zich los van de vdev, en keert terug naar de pool-brede taak.
Datasets, blokken, en sectoren
De volgende reeks bouwstenen die u moet begrijpen op uw ZFS reis hebben niet zozeer betrekking op de hardware, maar hoe de gegevens zelf worden georganiseerd en opgeslagen. We slaan hier een paar niveaus over, zoals het metaslab, om de zaken zo eenvoudig mogelijk te houden en toch de algemene structuur te begrijpen.
Datasets
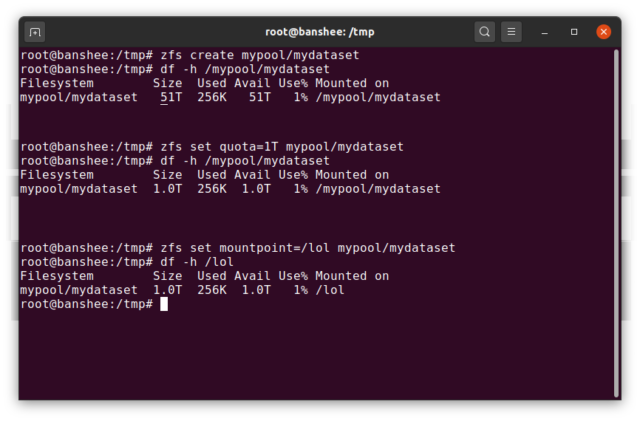

Een ZFS dataset is ruwweg analoog aan een standaard, aangekoppeld bestandssysteem-zoals een conventioneel bestandssysteem, lijkt het bij toevallige inspectie alsof het “gewoon een andere map” is. Maar net als conventionele gekoppelde bestandssystemen, heeft elke ZFS dataset zijn eigen set van onderliggende eigenschappen.
In de eerste plaats, kan een dataset een quotum toegewezen hebben gekregen. Als u zfs set quota=100G poolname/datasetname, zult u niet in staat zijn om meer dan 100GiB van gegevens in de systeem gekoppelde map /poolname/datasetname.
Opgemerkt de aanwezigheid-en afwezigheid-van leidende schuine strepen in het bovenstaande voorbeeld? Elke dataset heeft zijn plaats in zowel de ZFS hiërarchie, als de systeem mount hiërarchie. In de ZFS hiërarchie zijn er geen voorloop slashes-je begint met de naam van de pool, en dan het pad van de ene dataset naar de volgende-eg pool/parent/child voor een dataset genaamd child onder de bovenliggende dataset parent, in een pool met de creatieve naam pool.
Het koppelpunt van een dataset zal standaard gelijk zijn aan zijn ZFS hiërarchische naam, met een voorloopschuine streep – de pool met de naam pool is gekoppeld op /pool, dataset parent is gekoppeld op /pool/parent, en kind-dataset child is gekoppeld op /pool/parent/child. Het systeem mountpoint van een dataset kan echter worden gewijzigd.
Als we zfs set mountpoint=/lol pool/parent/child zouden gebruiken, zou de dataset pool/parent/child feitelijk op het systeem zijn aangekoppeld als /lol.
Naast datasets, moeten we zvols vermelden. Een zvol is ruwweg analoog aan een dataset, behalve dat het niet echt een bestandssysteem in zich heeft-het is gewoon een blok apparaat. U zou bijvoorbeeld een zvol kunnen aanmaken met de naam mypool/myzvol, deze dan formatteren met het ext4 bestandssysteem, en dan dat bestandssysteem mounten-u hebt nu een ext4 bestandssysteem, maar ondersteund met alle veiligheidskenmerken van ZFS! Dit klinkt misschien dom op een enkele computer, maar het is veel zinvoller als back-end voor een iSCSI-export.
Blocks
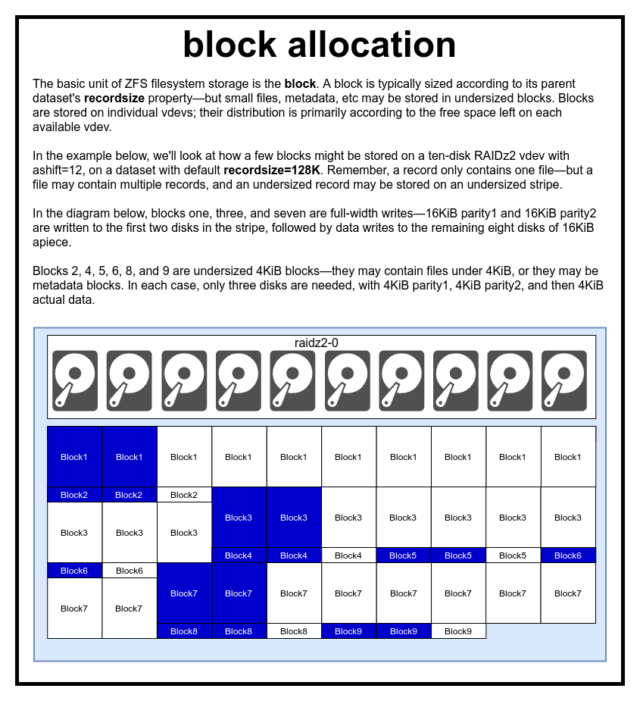

In een ZFS pool worden alle gegevens, inclusief metadata, opgeslagen in blocks. De maximale grootte van een block wordt voor elke dataset gedefinieerd in de eigenschap recordsize. Recordsize is veranderlijk, maar het veranderen van recordsize verandert niets aan de grootte of layout van blocks die al naar de dataset zijn geschreven – alleen voor nieuwe blokken als ze worden geschreven.
Indien niet anders gedefinieerd, is de huidige standaard recordsize 128KiB. Dit vertegenwoordigt een soort ongemakkelijk compromis waarin de prestaties niet ideaal zullen zijn voor veel van wat dan ook, maar ook niet verschrikkelijk voor veel van wat dan ook. Recordsize kan worden ingesteld op elke waarde van 4K tot 1M. (Recordsize kan zelfs groter worden ingesteld met extra afstemming en voldoende vastberadenheid, maar dat is zelden een goed idee.)
Elk gegeven block verwijst naar gegevens van slechts één bestand-je kunt niet twee afzonderlijke bestanden in dezelfde block proppen. Elk bestand zal worden samengesteld uit een of meer blocks, afhankelijk van de grootte. Als een bestand kleiner is dan recordsize, zal het worden opgeslagen in een te klein blok-bijvoorbeeld, een block die een 2KiB bestand bevat zal slechts een enkele 4KiB sector op schijf innemen.
Als een bestand groot genoeg is om meerdere blocks te vereisen, zullen alle records die dat bestand bevatten recordsize in lengte zijn- inclusief de laatste record, die grotendeels vrije ruimte kan zijn.
Zvols hebben niet de recordsize eigenschap-in plaats daarvan hebben ze volblocksize, wat ruwweg gelijkwaardig is.
Sectors
De laatste bouwsteen om te bespreken is de nederige sector. Een sector is de kleinste fysieke eenheid die kan worden geschreven naar of gelezen van de onderliggende device. Gedurende enkele decennia gebruikten de meeste schijven 512 byte sectors. Meer recent gebruiken de meeste schijven 4KiB sectors, en sommige – met name SSD’s – gebruiken 8KiB sectors, of zelfs groter.
ZFS heeft een eigenschap waarmee u handmatig de sector grootte kunt instellen, genaamd ashift. Enigszins verwarrend, ashift is eigenlijk de binaire exponent die de sectorgrootte vertegenwoordigt-bijvoorbeeld, het instellen van ashift=9 betekent dat uw sector grootte 2^9 zal zijn, of 512 bytes.
ZFS vraagt het besturingssysteem om details over elk blok device als het wordt toegevoegd aan een nieuwe vdev, en zal in theorie automatisch ashift goed instellen op basis van die informatie. Helaas zijn er veel schijven die liegen over wat hun sector grootte is, om compatibel te blijven met Windows XP (die niet in staat was om schijven met een andere sector grootte te begrijpen).
Dit betekent dat een ZFS admin sterk wordt aangeraden om zich bewust te zijn van de werkelijke sector grootte van zijn of haar devices, en ashift dienovereenkomstig handmatig in te stellen. Als ashift te laag is ingesteld, wordt een astronomische lees/schrijf amplificatie straf opgelopen – het schrijven van een 512 byte “sector” naar een 4KiB echte sector betekent dat de eerste “sector” moet worden geschreven, dan de 4KiB sector moet worden gelezen, moet worden gewijzigd met de tweede 512 byte “sector”, terug moet worden geschreven naar een *nieuwe* 4KiB sector, enzovoort, voor elke enkele schrijf.
In de echte wereld raakt deze versterkingsstraf een Samsung EVO SSD – die ashift=13 zou moeten hebben, maar liegt over zijn sectorgrootte en daarom standaard ashift=9 indien niet opgeheven door een slimme admin – hard genoeg om het langzamer te laten lijken dan een conventionele roestschijf.
In tegenstelling daarmee is er vrijwel geen straf voor het te hoog instellen van ashift. Er is geen echt prestatieverlies, en de toename van vrije ruimte is oneindig (of nul, als compressie is ingeschakeld). We raden sterk aan om zelfs schijven die echt 512 byte sectoren gebruiken ashift=12 of zelfs ashift=13 in te stellen voor toekomstbestendigheid.
De ashift eigenschap is per-vdev-niet per pool, zoals vaak en ten onrechte wordt gedacht!-en is onveranderlijk, eenmaal ingesteld. Als u per ongeluk ashift verknoeit bij het toevoegen van een nieuwe vdev aan een pool, hebt u die pool onherroepelijk vervuild met een drastisch ondermaats presterende vdev, en hebt u in het algemeen geen andere mogelijkheid dan de pool te vernietigen en opnieuw te beginnen. Zelfs het verwijderen van vdev kan u niet redden van een flubbed ashift-instelling!
Copy-on-Write-semantiek




CoW-Copy on Write-is een fundamenteel fundament onder het meeste van wat ZFS geweldig maakt. Het basisconcept is eenvoudig: als u een traditioneel bestandssysteem vraagt om een bestand ter plaatse te wijzigen, doet het precies wat u vraagt. Als je een copy-on-write bestandssysteem vraagt om hetzelfde te doen, zegt het “okay”-maar het liegt tegen je.
In plaats daarvan schrijft het copy-on-write bestandssysteem een nieuwe versie van de block die je hebt gewijzigd, en werkt dan de metadata van het bestand bij om de oude block te ontkoppelen, en de nieuwe block die je zojuist hebt geschreven te koppelen.
Unlinking van de oude block en linking in de nieuwe wordt bereikt in een enkele operatie, dus het kan niet worden onderbroken-als je de stroom dumpt nadat het gebeurt is, heb je de nieuwe versie van het bestand, en als je de stroom dumpt voordat, dan heb je de oude versie. Je bent altijd bestandssysteem-consistent, hoe dan ook.
Copy-on-write in ZFS is niet alleen op het bestandssysteem niveau, het is ook op het schijfbeheer niveau. Dit betekent dat het RAID-gat – een toestand waarbij een strip slechts gedeeltelijk wordt geschreven voordat het systeem crasht, waardoor de array inconsistent wordt en corrupt na een herstart – geen invloed heeft op ZFS. Stripe-schrijfbewerkingen zijn atomair, de vdev is altijd consistent en Bob’s your uncle.
ZIL-de ZFS Intent Log
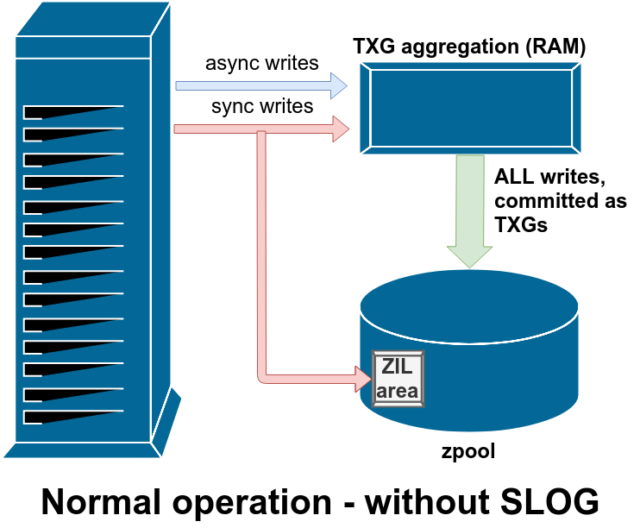

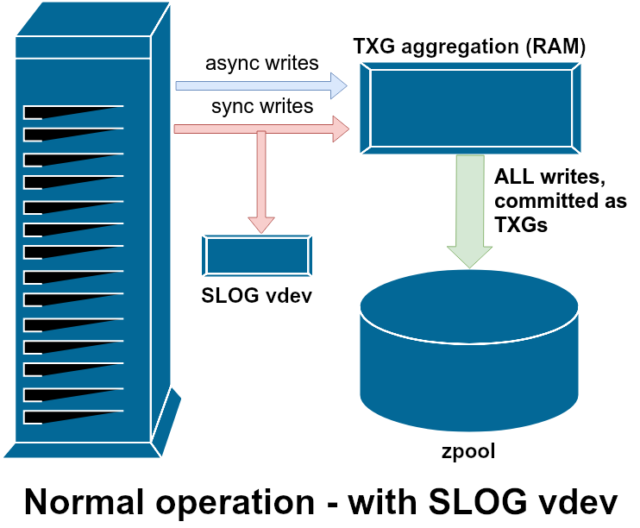

Er zijn twee hoofdcategorieën van schrijfbewerkingen-synchroon (sync) en asynchroon (async). Voor de meeste werklasten zijn de meeste schrijfbewerkingen asynchroon – het bestandssysteem mag ze samenvoegen en in batches vastleggen, waardoor fragmentatie wordt verminderd en de doorvoer enorm toeneemt.
Synchrone schrijfbewerkingen zijn een heel ander verhaal – wanneer een applicatie een synchrone schrijfbewerking aanvraagt, wordt er tegen het bestandssysteem gezegd: “Je moet dit nu vastleggen op niet-vluchtige opslag, en totdat je dat doet, kan ik niets anders meer doen. Sync-schrijfopdrachten moeten daarom onmiddellijk op schijf worden vastgelegd – en als dat de fragmentatie verhoogt of de doorvoer verlaagt, het zij zo.
ZFS behandelt sync-schrijfopdrachten anders dan normale bestandssystemen – in plaats van sync-schrijfopdrachten onmiddellijk uit te spoelen naar normale opslag, legt ZFS ze vast in een speciaal opslaggebied genaamd het ZFS Intent Log, of ZIL. De truc hier is dat deze schrijfacties ook in het geheugen blijven, samengevoegd met normale asynchrone schrijfverzoeken, om later naar de opslag te worden gespoeld als volkomen normale TXG’s (Transaction Groups).
In normaal bedrijf wordt er naar de ZIL geschreven en nooit meer van teruggelezen. Wanneer de op de ZIL bewaarde schriften enkele ogenblikken later vanuit het RAM in normale TXG’s naar de hoofdopslag worden gecommit, worden zij van de ZIL losgekoppeld. De enige keer dat de ZIL ooit wordt uitgelezen is bij het importeren van de pool.
Als ZFS crasht – of het besturingssysteem crasht, of er is een onbehandelde stroomonderbreking – terwijl er gegevens in de ZIL staan, zullen die gegevens worden uitgelezen tijdens de volgende pool import (bijvoorbeeld wanneer een gecrasht systeem opnieuw wordt opgestart). Wat er ook in de ZIL zit, het wordt ingelezen, geaggregeerd in TXG’s, gecommit naar de hoofdopslag, en dan ontkoppeld van de ZIL tijdens het import proces.
Eén van de klassen van ondersteuning vdev beschikbaar is LOG-ook bekend als SLOG, of Secondary LOG device. Het enige wat de SLOG doet is de pool voorzien van een aparte-en hopelijk veel sneller, met zeer hoge schrijf-duurzaamheid-vdev om de ZIL in op te slaan, in plaats van de ZIL op de hoofdopslag vdevs te houden. In alle opzichten gedraagt de ZIL zich hetzelfde, of hij nu op de hoofdopslag staat, of op een LOG vdev – maar als de LOG vdev zeer hoge schrijfprestaties heeft, dan zullen sync-schrijfretours zeer snel plaatsvinden.
Een LOG vdev toevoegen aan een pool kan en zal de asynchrone schrijfprestaties absoluut niet direct verbeteren – zelfs als je alle schrijfacties in de ZIL forceert met zfs set sync=always, worden ze nog steeds op dezelfde manier en in hetzelfde tempo gecommit op de hoofdopslag in TXGs als zonder de LOG. De enige directe prestatieverbeteringen zijn voor de synchrone schrijflatentie (omdat de grotere snelheid van LOG de sync aanroep in staat stelt om sneller terug te keren).
In een omgeving die al veel synchrone schrijfbewerkingen vereist, kan een LOG vdev echter indirect ook asynchrone schrijfbewerkingen en ongecacheerde leesbewerkingen versnellen. Het offloaden van ZIL-schrijfbewerkingen naar een aparte LOG vdev betekent minder strijd om IOPS op primaire opslag, waardoor de prestaties voor alle lees- en schrijfbewerkingen tot op zekere hoogte toenemen.
Snapshots
Copy-on-write semantiek is ook de noodzakelijke onderbouwing voor ZFS’s atomaire snapshots en incrementele asynchrone replicatie. Het live bestandssysteem heeft een boom van verwijzingen die alle records die huidige gegevens bevatten markeren – wanneer u een momentopname maakt, maakt u eenvoudig een kopie van die boom van verwijzingen.
Wanneer een record in het live bestandssysteem wordt overschreven, schrijft ZFS de nieuwe versie van de block eerst naar ongebruikte ruimte. Dan maakt het de oude versie van de block los van het huidige bestandssysteem. Maar als een snapshot verwijst naar de oude block, blijft deze nog steeds onveranderlijk. De oude block wordt pas als vrije ruimte teruggehaald als alle snapshots die naar die block verwijzen, zijn vernietigd!
Replicatie

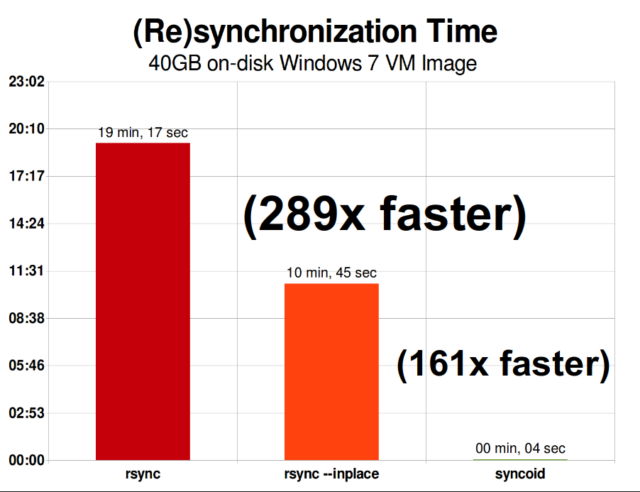
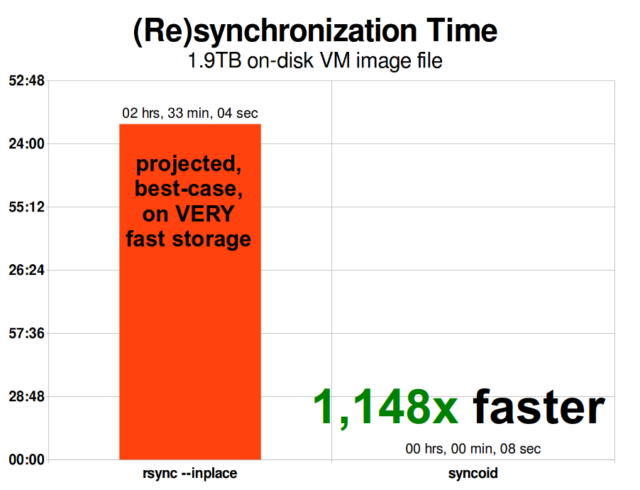 Als u eenmaal begrijpt hoe snapshots werken, bent u op een goede plaats om replicatie te begrijpen. Aangezien een momentopname eenvoudigweg een boom van verwijzingen naar
Als u eenmaal begrijpt hoe snapshots werken, bent u op een goede plaats om replicatie te begrijpen. Aangezien een momentopname eenvoudigweg een boom van verwijzingen naarrecordsis, volgt hieruit dat wanneer wezfs sendeen momentopname maken, we zowel die boom als alle bijbehorende records versturen. Wanneer we diezfs sendnaar eenzfs receiveop het doel pijpen, schrijft het zowel de eigenlijkeblockinhoud, als de boom van verwijzingen die naar deblocksverwijzen, in de doel dataset.
Dat wordt interessanter bij je tweede zfs send. Nu dat je twee systemen hebt, die elk het snapshot poolname/datasetname@1 bevatten, kun je een nieuw snapshot maken, poolname/datasetname@2. Dus op de bron pool, heb je datasetname@1 en datasetname@2, en op de doel pool, heb je tot nu toe alleen het eerste snapshot-datasetname@1.
Omdat we een gemeenschappelijk snapshot hebben tussen bron en doel-datasetname@1– kunnen we er een incrementele zfs send bovenop bouwen. Wanneer we het systeem vragen om zfs send -i poolname/datasetname@1 poolname/datasetname@2, vergelijkt het de twee pointer trees. Alle pointers die alleen bestaan in @2 verwijzen natuurlijk naar de nieuwe blocks, dus we hebben de inhoud van die blocks ook nodig.
Op het andere systeem is het inpassen van de resulterende incrementele send net zo eenvoudig. Eerst schrijven we alle nieuwe records in de send stroom, dan voegen we de verwijzingen naar die blocks toe. Presto, we hebben @2 op het nieuwe systeem!
ZFS asynchrone incrementele replicatie is een enorme verbetering ten opzichte van eerdere, niet-snapshot-gebaseerde technieken zoals rsync. In beide gevallen hoeven alleen de gewijzigde gegevens over de draad te worden verzonden-maar rsync moet eerst alle gegevens van de schijf lezen, aan beide kanten, om ze te controleren en te vergelijken. Daarentegen hoeft ZFS replicatie niets anders te lezen dan de pointer trees-en elke blocks die pointer tree bevat die niet al aanwezig was in de gemeenschappelijke snapshot.
Inline compressie
Copy-on-write semantiek maakt het ook makkelijker om inline compressie aan te bieden. Met een traditioneel bestandssysteem dat in-place modificatie biedt, is compressie problematisch – zowel de oude versie als de nieuwe versie van de gewijzigde gegevens moeten in precies dezelfde ruimte passen.
Als we een brok gegevens in het midden van een bestand beschouwen dat zijn leven begint als 1MiB aan nullen-0x00000000 ad nauseam- dan zou dat heel gemakkelijk tot een enkele schijfsector worden gecomprimeerd. Maar wat gebeurt er als we die 1MiB aan nullen vervangen door 1MiB aan onsamendrukbare gegevens, zoals JPEG of pseudo-willekeurige ruis? Plotseling heeft die 1MiB aan gegevens 256 4KiB sectoren nodig, niet slechts één, en het gat in het midden van het bestand is slechts één sector breed.
ZFS heeft dit probleem niet, omdat gewijzigde records altijd naar ongebruikte ruimte worden geschreven-de originele block neemt slechts een enkele 4KiB sector in beslag, en de nieuwe record neemt er 256 in beslag, maar dat is geen probleem-de nieuw gewijzigde chunk uit het “midden” van het bestand zou naar ongebruikte ruimte zijn geschreven, of de grootte nu veranderde of niet, dus voor ZFS is dit “probleem” gewoon weer een dag op het kantoor.
ZFS’s inline compressie staat standaard uit, en het biedt pluggable algoritmen – momenteel inclusief LZ4, gzip (1-9), LZJB, en ZLE.
- LZ4 is een stream algoritme dat extreem snelle compressie en decompressie biedt, en is een prestatie overwinning voor de meerderheid van de use cases – zelfs met zeer anemische CPU’s.
- GZIP is het eerbiedwaardige algoritme dat alle Unix-achtige gebruikers kennen en liefhebben. Het kan worden geïmplementeerd met compressieniveaus 1-9, met toenemende compressieverhouding en CPU-gebruik als niveaus 9 naderen. Gzip kan een overwinning zijn voor alle tekst (of anderszins extreem comprimeerbare) use-cases, maar leidt anders vaak tot CPU knelpunten-gebruik het met voorzichtigheid, vooral op hogere niveaus.
- LZJB is het oorspronkelijke algoritme dat door ZFS wordt gebruikt. Het is verouderd, en zou niet langer gebruikt moeten worden-LZ4 is superieur in elke metriek.
- ZLE is Zero Level Encoding-het laat normale data volledig met rust, maar comprimeert grote reeksen nullen. Nuttig voor volledig onsamendrukbare datasets (b.v. JPEG, MP4, of andere reeds gecomprimeerde formaten), aangezien het de onsamendrukbare gegevens negeert, maar de vrije ruimte op definitieve records comprimeert.
We bevelen LZ4 compressie aan voor bijna elke denkbare gebruikssituatie; het prestatieverlies wanneer het onsamendrukbare gegevens tegenkomt is zeer klein, en de prestatiewinst voor typische gegevens is aanzienlijk. Het kopiëren van een VM image voor een nieuwe Windows besturingssysteem installatie (alleen het geïnstalleerde Windows besturingssysteem, nog geen data erop) ging 27% sneller met compression=lz4 dan compression=none in deze 2015 test.
ARC-de Adaptive Replacement Cache
ZFS is het enige moderne bestandssysteem dat we kennen dat zijn eigen lees cache mechanisme gebruikt, in plaats van te vertrouwen op de pagina cache van het besturingssysteem om kopieën van recent gelezen blokken in RAM te bewaren voor het.
Hoewel het aparte cache mechanisme zijn problemen heeft-ZFS kan niet zo onmiddellijk reageren op nieuwe verzoeken om geheugen toe te wijzen als de kernel kan, en daarom kan een nieuwe mallocate() aanroep mislukken, als het RAM nodig zou hebben dat op dit moment door de ARC wordt bezet- er is een goede reden, althans voor nu, om het ermee te doen.
Elk bekend modern besturingssysteem – waaronder MacOS, Windows, Linux, en BSD – gebruikt het LRU (Least Recently Used) algoritme voor zijn pagina cache implementatie. LRU is een naïef algoritme dat een blok in de cache naar de “top” van de wachtrij schuift elke keer dat het wordt gelezen, en blokken van de “bottom” van de wachtrij verwijdert als dat nodig is om nieuwe cache missers (blokken die van schijf moesten worden gelezen, in plaats van cache) aan de “top” toe te voegen.”
Dit is prima tot zover het gaat, maar in systemen met grote datasets kan de LRU gemakkelijk eindigen in “thrashing” – het uitwissen van zeer vaak benodigde blokken, om plaats te maken voor blokken die nooit meer uit cache gelezen zullen worden.
De ARC is een veel minder naïef algoritme, dat kan worden gezien als een “gewogen” cache. Elke keer dat een blok uit de cache wordt gelezen, wordt het een beetje “zwaarder” en moeilijker uit te zetten, en zelfs na een uitzetting wordt het uitgezette blok nog een tijd bijgehouden. Een blok dat is uitgezet, maar daarna weer in de cache moet worden ingelezen, wordt ook “zwaarder” en moeilijker uit te zetten.
Het eindresultaat van dit alles is een cache met doorgaans veel hogere hit-ratio’s-de verhouding tussen cache-hits (gelezen vanuit de cache) en cache-misses (gelezen vanaf schijf). Dit is een zeer belangrijke statistiek- niet alleen worden de cache hits sneller geserveerd, ook de cache misses kunnen sneller worden geserveerd, omdat meer cache hits==minder gelijktijdige verzoeken aan de schijf==minder latentie voor de misses die nog van schijf moeten worden geserveerd.
Conclusie
Nu we de basissemantiek van ZFS hebben behandeld hoe copy-on-write werkt, en de relaties tussen pools, vdevs, blokken, sectoren en bestanden-zijn we klaar om over werkelijke prestaties te praten, met echte getallen.
Blijf kijken voor de volgende aflevering van onze opslag fundamentals serie om de werkelijke prestaties te zien in pools die mirror en RAIDz vdevs gebruiken, vergeleken met elkaar en de traditionele Linux kernel RAID topologieën die we eerder hebben onderzocht.
In eerste instantie gaan we alleen de basis behandelen-de ZFS topologieën zelf-maar daarna zullen we klaar zijn om te praten over meer geavanceerde ZFS setup en tuning, inclusief het gebruik van ondersteunende vdev types zoals L2ARC, SLOG, en Speciale Toewijzing.