Af Kajal Yadav, freelance skribent om datalogi, startups & iværksætteri.

Kilde Unsplash, redigeret af forfatteren.
Er du spændt på at komme ind i datalogi verden? Tillykke! Det er stadig det rigtige valg på grund af det ultimative boost i behovet for arbejde udført inden for Data Science og kunstig intelligens under denne pandemi.
Men på grund af krisen bliver markedet i øjeblikket hårdere for at kunne oprette det igen med mere mandskabskraft, som de gør tidligere. Så det kan være muligt, at du skal forberede dig mentalt på den lange ansættelsesrejse og mange afvisninger undervejs.
Dermed, mens jeg skriver denne artikel, går jeg ud fra, at du allerede ved, at en data science-portefølje er afgørende, og hvordan du opbygger den.
Du bruger måske det meste af din tid på at lave data crunching og wrangling og ikke anvende fancy modeller.
Et spørgsmål, som jeg har fået stillet igen og igen af data science entusiaster, er, hvilken slags projekter de bør inkludere i deres portefølje for at opbygge en enormt god og unik portefølje.
Nedenfor giver jeg 8 unikke ideer til din data science-portefølje med vedhæftede referenceartikler, hvorfra du vil få indsigt i, hvordan du kommer i gang med en bestemt idé.
- Sentimentanalyse for depression baseret på sociale medieindlæg
- Sports match video to text summarization using neural network
- Håndskrevet ligningsopløser ved hjælp af CNN
- Generering af resuméer til forretningsmøder ved hjælp af NLP
- Ansigtsgenkendelse til at registrere humør og foreslå sange i overensstemmelse hermed
- Find beboelige exoplaneter ud fra billeder optaget af rumfartøjer som Kepler
- Billedgenoprettelse til gammelt beskadiget rullebillede
- Musikgenerering ved hjælp af deep learning
- FINAL WORD

Foto af dole777 på Unsplash.
Dette emne er så følsomt at blive overvejet i dag og i presserende behov for at gøre noget ved det. Der er mere end 264 millioner mennesker på verdensplan, der lider af depression. Depression er den vigtigste årsag til invaliditet på verdensplan og er en væsentlig bidragyder til den samlede globale sygdomsbyrde, og næsten 800 000 personer bider konsekvent i støvet på grund af selvmord hvert år. Selvmord er den næststørste dødsårsag blandt de 15-29-årige. Behandling af depression er ofte forsinket, upræcis eller overses helt.
Internetbaseret liv giver den vigtigste kant chance for at ændre tidlige melankoliformidlingstjenester, især hos ungdommelige voksne. Konstant bliver der tweetet ca. 6.000 tweets på Twitter, hvilket relaterer til mere end 350.000 tweets sendt for hvert øjeblik, 500 millioner tweets for hver dag og omkring 200 milliarder tweets for hvert år.
Som angivet af Pew Research Center bruger 72% af offentligheden en eller anden form for internetbaseret liv. Datasæt, der frigives fra sociale netværk, er vigtige for mange områder, f.eks. humanvidenskab og hjerneforskning. Men understøttelserne fra et specialiseret synspunkt er langt fra tilstrækkelige, og eksplicitte metoder er desperat uheldige.
Gennem analyse af sproglige markører i indlæg på sociale medier er det muligt at skabe en deep learning-model, der kan give en person indsigt i hans eller hendes mentale helbred langt tidligere end traditionelle tilgange.
- You Are What You Tweet – Detecting Depression in Social Media via Twitter Usage
- Early Detection of Depression: Social Network Analysis and Random Forest Techniques – Original paper, University of A Coruna.
- Depression detection from social network data using machine learning techniques
Sports match video to text summarization using neural network

Foto af Aksh yadav på Unsplash.
Så denne projektidé er grundlæggende baseret på at få et præcist resumé ud af videoer af sportskampe. Der findes sportswebsteder, der fortæller om højdepunkterne i kampen. Der er blevet foreslået forskellige modeller til opgaven med ekstraktiv tekstresumé, men neurale netværk klarer opgaven bedst. Som regel hentyder sammenfatning til at introducere oplysninger i en kort struktur og koncentrere sig om dele, der formidler fakta og oplysninger, samtidig med at vigtigheden sikres.
Automatisk at skabe en oversigt over en kampvideo giver anledning til den udfordring at skelne fascinerende minutter eller højdepunkter i en kamp.
Så man kan opnå dette ved hjælp af nogle dybe læringsteknikker som 3D-CNN (tredimensionelle convolutionelle netværk), RNN (Recurrent neural network), LSTM (Long short term memory networks) og også gennem maskinlæringsalgoritmer ved at opdele videoen i forskellige sektioner og derefter anvende SVM (Support vector machines), NN (Neural Networks) og k-means-algoritmer.
For bedre forståelse henvises til den vedlagte artikel i detaljer.
- Sceneklassificering til sportsvideo-sammenfatning ved hjælp af transferlæring – I denne artikel foreslås en ny metode til klassificering af sportsvideoscener.
Håndskrevet ligningsopløser ved hjælp af CNN
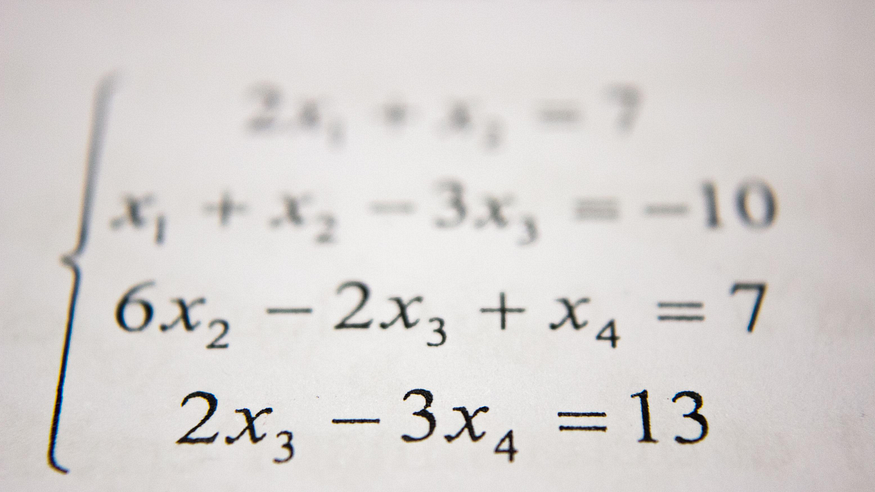
Foto af Antoine Dautry på Unsplash.
Af alle spørgsmål er håndskrevet matematisk udtryksgenkendelse et af de forvirrende spørgsmål i området for computer vision-forskning. Man kan træne en håndskrevet ligningsløser ved hjælp af håndskrevne cifre og matematiske symboler ved hjælp af Convolutional Neural Network (CNN) med nogle billedbehandlingsteknikker. Udvikling af et sådant system kræver, at vi træner vores maskiner med data, så de bliver dygtige til at lære og foretage den nødvendige forudsigelse.
Se nedenstående artikler for bedre forståelse.
- Håndskrevet ligningsopløser ved hjælp af Convolutional Neural Network
- vipul79321/Handwritten-Equation-Solver – An Handwritten Equation solver using CNN Ligning kan indeholde ethvert ciffer fra 0-9 og symbol.
- Computer Vision – Automatisk klassificering af håndskrevne matematiske svarark – Digitalisering af trinene til løsning af en matematisk ligning skrevet i fri hånd på et papir.
- Håndskrevne ligninger til LaTeX
Generering af resuméer til forretningsmøder ved hjælp af NLP

Foto af Sebastian Herrmann på Unsplash.
Er du nogensinde havnet i en situation, hvor alle ønsker at se et resumé og ikke den fulde rapport? Ja, jeg stod over for det i min skole- og universitetstid, hvor vi brugte meget tid på at forberede en hel rapport, men læreren har kun tid til at læse resuméet.
Summarisering er opstået som en uundgåelig hjælpsom måde at tackle problemet med overbelastning af data. Udtrækning af oplysninger fra samtaler kan være af meget god kommerciel og pædagogisk værdi. Dette kan gøres ved at indfange de statistiske, sproglige og følelsesmæssige aspekter med samtalens dialogstruktur.
Manuelt at ændre rapporten til en opsummeret form er for tidskrævende, er det ikke sådan? Men man kan stole på Natural Language Processing (NLP) teknikker til at opnå dette.
Tekstsammenfatning ved hjælp af deep learning kan forstå konteksten i hele teksten. Er det ikke en drøm, der går i opfyldelse for alle os, der har brug for at komme med et hurtigt resumé af et dokument!
Se nedenstående vedhæftede artikler for bedre forståelse.
- Omfattende guide til tekstsammenfatning ved hjælp af Deep Learning i Python – “Jeg vil ikke have en fuld rapport, bare giv mig et resumé af resultaterne.”
- Forstå tekstsammenfatning og opret din egen summarizer i python – Sammenfatning kan defineres som en opgave, der består i at producere et kortfattet og flydende resumé, samtidig med at vigtige oplysninger bevares.
Ansigtsgenkendelse til at registrere humør og foreslå sange i overensstemmelse hermed

Foto af Alireza Attari på Unsplash.
Det menneskelige ansigt er en vigtig del af et individs krop, og det spiller især en væsentlig rolle for at kende en persons sindstilstand. Dette eliminerer den kedelige og kedelige opgave med manuelt at isolere eller gruppere sange i forskellige plader og hjælper med at generere en passende spilleliste baseret på en persons følelsesmæssige træk.
Mennesker har en tendens til at lytte til musik baseret på deres humør og interesser. Man kan oprette en applikation, der foreslår sange til brugere baseret på deres humør ved at registrere ansigtsudtryk.
Computervision er et tværfagligt område, der hjælper med at formidle en forståelse på højt niveau af digitale billeder eller videoer til computere. Computer vision-komponenter kan bruges til at bestemme brugerens følelser gennem ansigtsudtryk.
Der er også disse API’er, som jeg fandt interessante og nyttige. Jeg har dog ikke arbejdet på disse, men vedhæfter her med et håb om, at disse vil hjælpe dig.
- 20+ Emotion Recognition APIs That Will Leave You Impressed, and Concerned | Nordic APIs – Hvis virksomheder kunne fornemme følelser ved hjælp af teknologi på alle tidspunkter, kunne de udnytte det til at sælge til forbrugeren.
Find beboelige exoplaneter ud fra billeder optaget af rumfartøjer som Kepler

Foto af Nick Owuor (astro.nic.visuals) på Unsplash.
I det seneste årti blev over en million stjerner overvåget for at identificere transiterende planeter. Manuel fortolkning af potentielle exoplanetkandidater er arbejdskrævende og udsat for menneskelige fejl, hvis konsekvenser er svære at vurdere. Konvolutionelle neurale netværk er velegnede til at identificere jordlignende exoplaneter i støjende tidsseriedata med en mere fremtrædende præcision end en mindste kvadraters strategi.
- Exoplanetjagt ved hjælp af maskinlæring – Jagt på verdener uden for vores solsystem.
- Kunstig intelligens, NASA-data bruges til at opdage exoplaneter – Vores solsystem er nu bundet for flest antal planeter omkring en enkelt stjerne.
Billedgenoprettelse til gammelt beskadiget rullebillede

Kilde Pikist.
Jeg ved, hvor tidskrævende og smertefuldt det er at få dit gamle beskadigede foto tilbage i den oprindelige form, som det var tidligere. Så dette kan gøres ved hjælp af deep learning ved at finde alle billedets defekter (brud, skrammer, huller) og bruge inpainting-algoritmer, så man nemt kan opdage defekterne baseret på pixelværdierne omkring dem for at genoprette og farvelægge de gamle fotos.
- Farvelægning og genopretning af gamle billeder med deep learning – Farvelægning af sort/hvide billeder med deep learning er blevet et imponerende udstillingsvindue for den virkelige verden.
- Guide til billedinpainting: Brug af maskinlæring til at redigere og rette fejl i fotos
- Sådan udfører du billedrestaurering Absolut DataSet Free
Musikgenerering ved hjælp af deep learning

Foto af Abigail Keenan på Unsplash.
Musik er et sammensurium af toner af forskellige frekvenser. Så automatisk musikgenerering er en proces, der består i at komponere et kort stykke musik med mindst mulig menneskelig formidling. For nylig er deep learning-teknik blevet banebrydende for programmeret musikgenerering.
- Musikgenerering ved hjælp af deep learning
- Sådan genereres musik ved hjælp af et LSTM neuralt netværk i Keras – En introduktion til at skabe musik ved hjælp af LSTM neurale netværk
FINAL WORD
Jeg ved, at det er en reel kamp at opbygge en cool datavidenskabs-portefølje. Men med en sådan samling, som jeg har givet ovenfor, kan du gøre over gennemsnittet fremskridt inden for det område. Samlingen er ny, hvilket også giver mulighed for forskningsformål. Så forskere inden for datalogi kan også vælge disse ideer til at arbejde med, så deres forskning vil være en stor hjælp for dataloger til at starte med projektet. Desuden er det sjovt at udforske de sider, som ingen har gjort før. Selv om denne samling faktisk udgør ideer fra begynder- til avanceret niveau.
Så jeg vil ikke kun anbefale dette til nybegyndere inden for datalogiområdet, men også til ældre dataloger. Den vil åbne mange nye veje i løbet af din karriere, ikke kun på grund af projekterne, men også gennem det nyligt opnåede netværk.
Disse idéer viser dig den brede vifte af muligheder og giver dig ideer til at tænke ud af boksen.
For mig og mine venner er læringsfaktorerne, at tilføre værdi til samfundet og den uudforskede viden vigtig, og det sjove på en måde er afgørende. Så dybest set nyder jeg at lave sådanne projekter, som giver os mulighed for at få en enorm viden på en måde og lader os udforske de uudforskede dimensioner. Det er vores hovedfokus, når vi dedikerer tid til sådanne projekter.
Original. Genudgivet med tilladelse.
Bio: Kajal Yadav er freelanceforfatter med speciale i datavidenskab, startups og iværksætteri. Hun skriver for flere publikationer og arbejder samtidig med startups om deres strategier for indholdsmarkedsføring.
Relateret:
- Start din maskinlæringskarriere i karantæne
- Projekter, der skal indgå i en datalogiportefølje
- Hvordan man opbygger en datalogiportefølje