av Kajal Yadav, frilansskribent om datavetenskap, nystartade företag och entreprenörskap.

Källa Unsplash, redigerad av författaren.
Är du sugen på att börja arbeta med datavetenskap? Grattis! Det är fortfarande rätt val på grund av den ultimata ökningen av behovet av arbete inom Data Science och artificiell intelligens under denna pandemi.
Men på grund av krisen blir marknaden för närvarande tuffare för att kunna ställa upp igen med mer manskraft som de gör tidigare. Så, Det kan vara möjligt att du måste förbereda dig mentalt för den långa rekryteringsresan och många avslag på vägen.
Härigenom, medan jag skriver den här artikeln, antar jag att du redan vet att en datavetenskapsportfölj är avgörande och hur man bygger upp den.
Du kanske tillbringar det mesta av din tid med data crunching och wrangling och inte med att tillämpa tjusiga modeller.
En fråga som jag har fått om och om igen av datavetenskapliga entusiaster är vilken typ av projekt de bör inkludera i sin portfölj för att bygga upp en enormt bra och unik portfölj.
Nedan ger jag 8 unika idéer för din datavetenskapsportfölj med bifogade referensartiklar varifrån du kommer att få insikter om hur du ska komma igång med en viss idé.
- Sentimentanalys för depression baserat på inlägg i sociala medier
- Sports match video to text summarization using neural network
- Handskriven ekvationslösare med hjälp av CNN
- Generering av sammanfattningar av affärsmöten med hjälp av NLP
- Ansiktsigenkänning för att upptäcka humör och föreslå låtar därefter
- Finnande av beboeliga exoplaneter från bilder tagna av rymdfarkoster som Kepler
- Bildregenerering för gammal skadad rullebild
- Musikgenerering med hjälp av djupinlärning
- Slutord

Foto av dole777 på Unsplash.
Det här ämnet är så känsligt att det ska betraktas nuförtiden och i brådskande behov att göra något åt det. Det finns mer än 264 miljoner människor i världen som lider av depression. Depression är den främsta orsaken till funktionshinder i hela världen och är en betydande supporter av den totala globala sjukdomsbördan, och nästan 800 000 individer biter konsekvent i gräset på grund av självmord varje år. Självmord är den näst vanligaste dödsorsaken bland 15-29-åringar. Behandling av depression försenas ofta, är oprecis eller missas helt.
Internetbaserat liv ger den främsta chansen att förändra tidiga förmedlingstjänster för melankoli, särskilt hos unga vuxna. Konstant twittras ungefär 6 000 Tweets på Twitter, vilket relaterar till mer än 350 000 tweets som skickas för varje ögonblick, 500 miljoner tweets för varje dag och cirka 200 miljarder tweets för varje år.
Som anges av Pew Research Center använder 72 % av allmänheten någon form av internetbaserat liv. Datamängder som frigörs från sociala nätverk är viktiga för många områden, till exempel humaniora och hjärnforskning. Men stöden från en specialiserad synvinkel är långt ifrån tillräckliga, och explicita metoder är desperat chanslösa.
Genom att analysera språkliga markörer i inlägg i sociala medier är det möjligt att skapa en modell för djupinlärning som kan ge en individ insikt i sin mentala hälsa långt tidigare än traditionella metoder.
- You Are What You Tweet – Detecting Depression in Social Media via Twitter Usage
- Early Detection of Depression: Social Network Analysis and Random Forest Techniques – Original paper, University of A Coruna.
- Depression detection from social network data using machine learning techniques
Sports match video to text summarization using neural network

Foto av Aksh yadav på Unsplash.
Den här projektidén bygger i grunden på att få fram ett exakt sammandrag av videoklipp från sportmatcher. Det finns webbplatser för sport som berättar om matchens höjdpunkter. Olika modeller har föreslagits för uppgiften att extrahera sammanfattningar av text, men neurala nätverk gör det bästa jobbet. I regel anspelar sammanfattning på att introducera information i en kort struktur och koncentrera sig på delar som förmedlar fakta och information, samtidigt som betydelsen skyddas.
Automatiskt skapa en sammanfattning av en matchvideo ger upphov till utmaningen att urskilja fascinerande minuter eller höjdpunkter i en match.
Så man kan uppnå detta med hjälp av vissa djupinlärningstekniker som 3D-CNN (tredimensionella konvolutionella nätverk), RNN (Recurrent neural network), LSTM (Long short term memory networks) och även med hjälp av algoritmer för maskininlärning genom att dela in videon i olika sektioner och sedan tillämpa SVM (Support vector machines), NN (Neural Networks) och k-means algoritmer.
För bättre förståelse hänvisar vi till den bifogade artikeln i detalj.
- Scenklassificering för sammanfattning av sportvideor med hjälp av överföringsinlärning – I denna artikel föreslås en ny metod för scenklassificering av sportvideor.
Handskriven ekvationslösare med hjälp av CNN
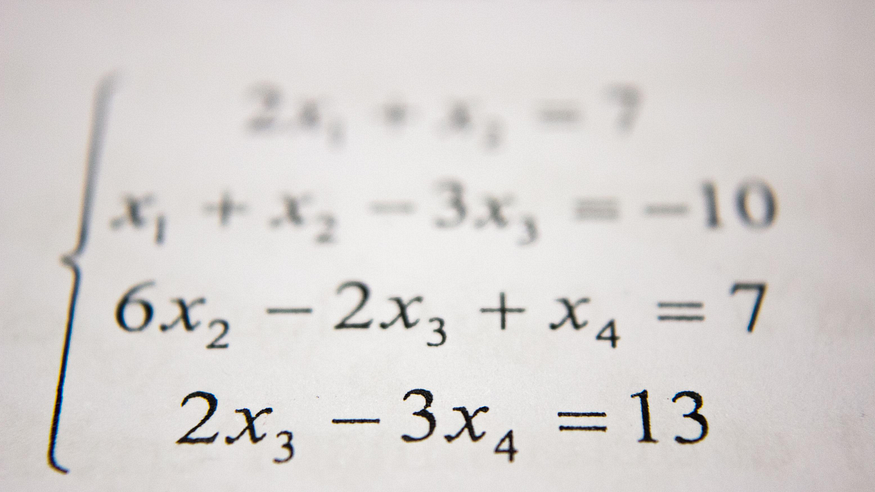
Foto av Antoine Dautry på Unsplash.
Av alla frågor är igenkänning av handskrivna matematiska uttryck en av de förvirrande frågorna inom området datorseendeforskning. Man kan träna en handskriven ekvationslösare med hjälp av handskrivna siffror och matematiska symboler genom att använda Convolutional Neural Network (CNN) med vissa bildbehandlingstekniker. För att utveckla ett sådant system krävs att vi tränar våra maskiner med data, så att de blir skickliga på att lära sig och göra de nödvändiga förutsägelserna.
Se även nedanstående artiklar för att få en bättre förståelse.
- Handskriven ekvationslösare med hjälp av ett konvolutionellt neuralt nätverk
- vipul79321/Handwritten-Equation-Solver – En handskriven ekvationslösare med hjälp av CNN Ekvation kan innehålla valfri siffra från 0-9 och symbol.
- Computer Vision – Automatisk klassificering av handskrivna matematiska svarsblad – Digitalisering av stegen för att lösa en matematisk ekvation som skrivits för hand på ett papper.
- Handskrivna ekvationer till LaTeX
Generering av sammanfattningar av affärsmöten med hjälp av NLP

Foto av Sebastian Herrmann på Unsplash.
Har du någonsin fastnat i en situation där alla vill se en sammanfattning och inte hela rapporten? Ja, det har jag varit med om under min skol- och universitetstid, när vi ägnade mycket tid åt att förbereda en hel rapport, men läraren har bara tid att läsa sammanfattningen.
Sammanfattningar har blivit ett oundvikligt hjälpmedel för att hantera problemet med överflöd av data. Att extrahera information från samtal kan vara av mycket gott kommersiellt och pedagogiskt värde. Detta kan göras genom att man fångar de statistiska, språkliga och känslomässiga aspekterna med samtalets dialogstruktur.
Manuellt ändra rapporten till en sammanfattad form är för tidskrävande, eller hur? Men man kan förlita sig på tekniker för Natural Language Processing (NLP) för att uppnå detta.
Textsammanfattning med hjälp av djupinlärning kan förstå sammanhanget i hela texten. Är det inte en dröm som går i uppfyllelse för alla oss som behöver en snabb sammanfattning av ett dokument!
Se även nedanstående artiklar för bättre förståelse.
- Comprehensive Guide to Text Summarization using Deep Learning in Python – ”I don’t want a full report, just give me a summary of the results.”
- Förstå textresumé och skapa en egen sammanfattare i python – Sammanfattning kan definieras som en uppgift att producera en kortfattad och flytande sammanfattning samtidigt som viktig information bevaras.
Ansiktsigenkänning för att upptäcka humör och föreslå låtar därefter

Foto av Alireza Attari på Unsplash.
Människans ansikte är en viktig del av en individs kropp, och det spelar särskilt en betydande roll för att känna till en persons sinnestillstånd. Detta eliminerar den tråkiga och tråkiga uppgiften att manuellt isolera eller gruppera låtar i olika skivor och hjälper till att generera en lämplig spellista baserad på en individs känslomässiga egenskaper.
Människor tenderar att lyssna på musik baserat på sitt humör och sina intressen. Man kan skapa en applikation som föreslår låtar för användare utifrån deras humör genom att registrera ansiktsuttryck.
Computervision är ett tvärvetenskapligt område som hjälper till att förmedla en förståelse på hög nivå av digitala bilder eller videor till datorer. Datorseendekomponenter kan användas för att fastställa användarens känslor genom ansiktsuttryck.
Det finns också dessa API:er som jag fann intressanta och användbara. Jag har dock inte arbetat med dessa men bifogar här med en förhoppning om att dessa kommer att hjälpa dig.
- 20+ Emotion Recognition APIs That Will Leave You Impressed, and Concerned | Nordic APIs – Om företag skulle kunna känna av känslor med hjälp av teknik hela tiden, skulle de kunna dra nytta av det för att sälja till konsumenten.
Finnande av beboeliga exoplaneter från bilder tagna av rymdfarkoster som Kepler

Foto av Nick Owuor (astro.nic.visuals) på Unsplash.
Under det senaste decenniet övervakades över en miljon stjärnor för att identifiera transiterande planeter. Manuell tolkning av potentiella exoplanetkandidater är arbetsintensiv och föremål för mänskliga misstag, vars konsekvenser är svåra att utvärdera. Konvolutionella neurala nätverk är lämpliga för att identifiera jordliknande exoplaneter i bullriga tidsseriedata med mer framträdande precision än en minsta kvadrat-strategi.
- Exoplanet hunting using Machine Learning – Hunting worlds beyond our solar system.
- Artificiell intelligens, NASA-data används för att upptäcka exoplaneter – Vårt solsystem har nu lika många planeter runt en enda stjärna.
Bildregenerering för gammal skadad rullebild

Källa Pikist.
Jag vet hur tidskrävande och smärtsamt det är att få tillbaka ditt gamla skadade foto i den ursprungliga formen som det var tidigare. Så detta kan göras med hjälp av djupinlärning genom att hitta alla bilddefekter (frakturer, skråmor, hål) och använda inpainting-algoritmer, så att man enkelt kan upptäcka defekterna baserat på pixelvärdena runt omkring dem för att återställa och färglägga de gamla bilderna.
- Färgläggning och återställande av gamla bilder med djupinlärning – Färgläggning av svartvita bilder med djupinlärning har blivit ett imponerande skyltfönster för den verkliga tillämpningen.
- Guide to Image Inpainting: Använd maskininlärning för att redigera och korrigera defekter i foton
- Hur man utför bildrestaurering Absolut DataSet Free
Musikgenerering med hjälp av djupinlärning

Foto av Abigail Keenan på Unsplash.
Musik är ett sortiment av toner med olika frekvenser. Automatisk musikgenerering är alltså en process för att komponera ett kort musikstycke med minsta möjliga mänskliga inblandning. Nyligen har teknik för djupinlärning blivit banbrytande för programmerad musikgenerering.
- Musikgenerering med hjälp av djupinlärning
- Hur man genererar musik med hjälp av ett LSTM-neuralt nätverk i Keras – En introduktion till att skapa musik med hjälp av LSTM-neurala nätverk
Slutord
Jag vet att det är en riktig kamp att bygga upp en häftig datavetenskapsportfölj. Men med en sådan samling som jag har tillhandahållit ovan kan du göra framsteg över genomsnittet på det området. Samlingen är ny, vilket ger möjlighet för forskningsändamål också. Så forskare inom datavetenskap kan också välja dessa idéer att arbeta med så att deras forskning blir en stor hjälp för datavetare att börja med projektet. Dessutom är det roligt att utforska sidor som ingen har gjort tidigare. Även om den här samlingen faktiskt utgör idéer från början till avancerad nivå.
Så jag kommer inte bara att rekommendera den här för nybörjare inom data science-området utan även för erfarna dataforskare. Den kommer att öppna många nya vägar under din karriär, inte bara på grund av projekten utan också genom det nyvunna nätverket.
Dessa idéer visar dig det breda spektrumet av möjligheter och ger dig idéer att tänka utanför boxen.
För mig och mina vänner är inlärningsfaktorerna, att tillföra värde till samhället och den outforskade kunskapen viktiga, och det roliga på sätt och vis är väsentligt. Så i grund och botten tycker jag om att göra sådana projekt som ger oss ett sätt att få enorma kunskaper på ett sätt och låter oss utforska de outforskade dimensionerna. Det är vårt huvudfokus när vi ägnar tid åt sådana projekt.
Original. Återpublicerat med tillstånd.
Bio: Kajal Yadav är frilansskribent som specialiserat sig på datavetenskap, nystartade företag och entreprenörskap. Hon skriver för flera publikationer och arbetar samtidigt med startups om deras strategier för innehållsmarknadsföring.
Relaterat:
- Start din karriär inom maskininlärning i karantän
- Projekt att inkludera i en portfölj inom datavetenskap
- Hur man bygger upp en portfölj inom datavetenskap
.