Par Kajal Yadav, un écrivain indépendant sur la science des données, les startups &l’entrepreneuriat.

Source Unsplash, éditée par l’auteur.
Etes-vous excité d’entrer dans le monde de la science des données ? Félicitations ! C’est encore le bon choix en raison de l’ultime coup de pouce dans le besoin de travail effectué dans la science des données et l’intelligence artificielle au cours de cette pandémie.
Alors que, en raison de la crise, le marché devient actuellement plus difficile à être en mesure de le mettre en place à nouveau avec plus de force d’hommes comme ils le font plus tôt. Donc, Il pourrait possible que vous devez vous préparer mentalement pour le long voyage d’embauche et de nombreux rejets dans le long du chemin.
Hereby, tout en écrivant cet article, je suppose que vous savez déjà qu’un portefeuille de science de données est crucial et comment le construire.
Vous pourriez passer la plupart de votre temps à faire du crunching et du wrangling de données et non à appliquer des modèles fantaisistes.
Une question qui m’a été posée à maintes reprises par des enthousiastes de la science des données est celle de savoir quel type de projets ils devraient inclure dans leur portefeuille pour construire un portefeuille formidablement bon et unique.
Ci-après, je donne 8 idées uniques pour votre portefeuille de science des données avec des articles de référence ci-joints d’où vous obtiendrez les idées de la façon de commencer avec une idée particulière.
- Analyse du sentiment pour la dépression basée sur les messages des médias sociaux
- Sports match video to text summarization using neural network
- Solveur d’équations manuscrites à l’aide de CNN
- Génération de résumé de réunion d’affaires à l’aide de NLP
- La reconnaissance faciale pour détecter l’humeur et suggérer des chansons en conséquence
- Découvrir une exo-planète habitable à partir des images capturées par des véhicules spatiaux comme Kepler
- Régénération d’image pour une vieille photo de bobine endommagée
- Génération de musique à l’aide de l’apprentissage profond
- Mot final
Analyse du sentiment pour la dépression basée sur les messages des médias sociaux

Photo par dole777 sur Unsplash.
Ce sujet est si sensible pour être considéré de nos jours et dans le besoin urgent de faire quelque chose à ce sujet. Il y a plus de 264 millions d’individus dans le monde qui souffrent de dépression. La dépression est la principale cause d’invalidité dans le monde et représente une part importante de la charge globale de morbidité. Chaque année, près de 800 000 personnes se suicident. Le suicide est la deuxième cause de décès chez les 15-29 ans. Le traitement de la dépression est souvent retardé, imprécis ou totalement absent.
La vie sur Internet offre la possibilité de modifier les services de médiation précoce de la mélancolie, en particulier chez les jeunes adultes. En permanence, environ 6 000 tweets sont échangés sur Twitter, ce qui représente plus de 350 000 tweets envoyés à chaque instant, 500 millions de tweets par jour et environ 200 milliards de tweets par an.
Comme l’indique le Pew Research Center, 72% du public utilise une forme de vie basée sur Internet. Les données issues des réseaux sociaux sont importantes pour de nombreux domaines, par exemple les sciences humaines et la recherche sur le cerveau. Mais les supports d’un point de vue spécialisé sont loin d’être suffisants, et les méthodologies explicites manquent cruellement de chance.
En analysant les marqueurs linguistiques dans les messages des médias sociaux, il est possible de créer un modèle d’apprentissage profond qui peut donner à un individu un aperçu de sa santé mentale bien plus tôt que les approches traditionnelles.
- You Are What You Tweet – Detecting Depression in Social Media via Twitter Usage
- Early Detection of Depression : Social Network Analysis and Random Forest Techniques – Article original, Université de La Corogne.
- Depression detection from social network data using machine learning techniques
Sports match video to text summarization using neural network

Photo by Aksh yadav on Unsplash.
So this project idea is basically based on getting a precise summary out of sports match videos. Il existe des sites web sportifs qui racontent les moments forts du match. Différents modèles ont été proposés pour la tâche de résumé de texte extractif, mais les réseaux de neurones font le meilleur travail. En règle générale, le résumé fait allusion à l’introduction d’informations dans une structure brève, en se concentrant sur les parties qui transmettent des faits et des informations, tout en sauvegardant l’importance.
La création automatique d’un plan d’une vidéo de match donne lieu au défi de distinguer les minutes fascinantes ou les moments forts d’un match.
On peut donc y parvenir en utilisant certaines techniques d’apprentissage profond comme le 3D-CNN (réseaux convolutifs tridimensionnels), le RNN (réseau neuronal récurrent), le LSTM (réseaux de mémoire à long terme), et également par le biais d’algorithmes d’apprentissage automatique en divisant la vidéo en différentes sections puis en appliquant les algorithmes SVM (Support vector machines), NN (Neural Networks) et k-means.
Pour une meilleure compréhension, veuillez vous référer à l’article ci-joint en détail.
- Classification de scènes pour le résumé de vidéos sportives en utilisant l’apprentissage par transfert – Cet article propose une nouvelle méthode pour la classification de scènes de vidéos sportives.
Solveur d’équations manuscrites à l’aide de CNN
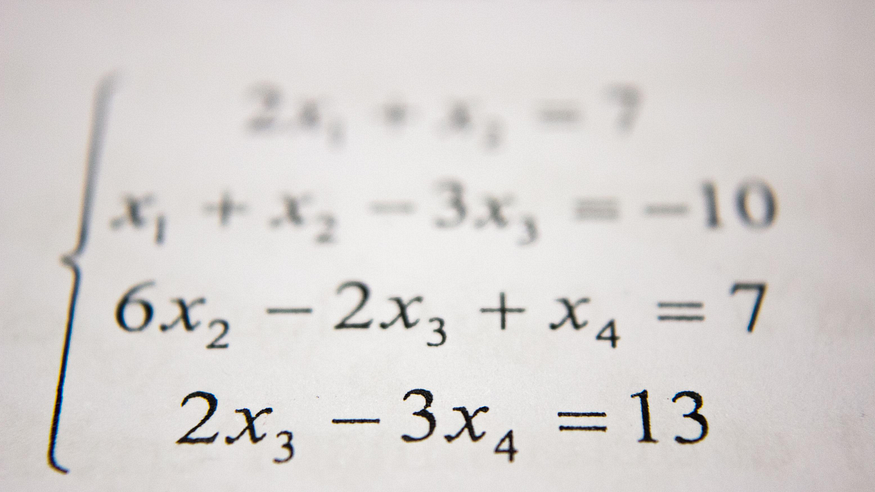
Photo d’Antoine Dautry sur Unsplash.
Parmi tous les problèmes, la reconnaissance d’expressions mathématiques manuscrites est l’un des problèmes confondants dans la région de la recherche en vision par ordinateur. Il est possible d’entraîner un résolveur d’équations manuscrites à partir de chiffres et de symboles mathématiques manuscrits en utilisant un réseau neuronal convolutif (CNN) avec certaines techniques de traitement d’images. Le développement d’un tel système nécessite d’entraîner nos machines avec des données, de les rendre compétentes pour apprendre et faire la prédiction requise.
Veuillez vous référer aux articles joints ci-dessous pour une meilleure compréhension.
- Solveur d’équations manuscrites à l’aide d’un réseau neuronal convolutif
- vipul79321/Handwritten-Equation-Solver – Un solveur d’équations manuscrites à l’aide de CNN L’équation peut contenir n’importe quel chiffre de 0 à 9 et un symbole.
- Vision par ordinateur – Auto grading Handwritten Mathematical Answer sheets – Numérisation des étapes de la résolution d’une équation mathématique écrite à main levée sur un papier.
- Équations manuscrites vers LaTeX
Génération de résumé de réunion d’affaires à l’aide de NLP

Photo de Sebastian Herrmann sur Unsplash.
Vous avez déjà été coincé dans une situation où tout le monde veut voir un résumé et non le rapport complet ? Eh bien, j’y ai été confronté pendant mes années d’école et de collège, où nous avons passé beaucoup de temps à préparer un rapport complet, mais le professeur n’a le temps de lire que le résumé.
La synthèse s’est imposée comme un moyen inexorablement utile de s’attaquer au problème de la surcharge de données. L’extraction d’informations à partir de conversations peut avoir une très bonne valeur commerciale et éducative. Cela peut être fait par la capture de caractéristiques des aspects statistiques, linguistiques et sentimentaux avec la structure de dialogue de la conversation.
Changer manuellement le rapport en une forme résumée prend trop de temps, n’est-ce pas ? Mais on peut s’appuyer sur les techniques de traitement du langage naturel (NLP) pour y parvenir.
Le résumé de texte utilisant l’apprentissage profond peut comprendre le contexte du texte entier. N’est-ce pas un rêve devenu réalité pour tous ceux d’entre nous qui ont besoin de trouver un résumé rapide d’un document !
Veuillez vous référer aux articles ci-joints pour mieux comprendre.
- Guide complet du résumé de texte à l’aide de l’apprentissage profond en Python – « Je ne veux pas un rapport complet, donnez-moi juste un résumé des résultats. »
- Comprendre le résumé de texte et créer votre propre résumeur en python – Le résumé peut être défini comme une tâche consistant à produire un résumé concis et fluide tout en préservant les informations clés.
La reconnaissance faciale pour détecter l’humeur et suggérer des chansons en conséquence

Photo d’Alireza Attari sur Unsplash.
Le visage humain est une partie importante du corps d’un individu, et il joue particulièrement un rôle significatif pour connaître l’état d’esprit d’une personne. Cela élimine la tâche ennuyeuse et fastidieuse d’isoler ou de regrouper manuellement les chansons dans divers enregistrements et aide à générer une liste de lecture appropriée en fonction des caractéristiques émotionnelles d’un individu.
Les gens ont tendance à écouter de la musique en fonction de leur humeur et de leurs intérêts. On peut créer une application pour suggérer des chansons aux utilisateurs en fonction de leur humeur en capturant les expressions faciales.
La vision par ordinateur est un domaine interdisciplinaire qui aide à transmettre une compréhension de haut niveau des images ou des vidéos numériques aux ordinateurs. Les composants de vision par ordinateur peuvent être utilisés pour déterminer l’émotion de l’utilisateur à travers les expressions faciales.
Il y a aussi ces API que j’ai trouvées intéressantes et utiles. Cependant, je n’ai pas travaillé sur ceux-ci mais je joins ici avec l’espoir que ceux-ci vous aideront.
- 20+ Emotion Recognition APIs That Will Leave You Impressed, and Concerned | Nordic APIs – Si les entreprises pouvaient sentir l’émotion en utilisant la technologie à tout moment, elles pourraient capitaliser dessus pour vendre au consommateur.
Découvrir une exo-planète habitable à partir des images capturées par des véhicules spatiaux comme Kepler

Photo de Nick Owuor (astro.nic.visuals) sur Unsplash.
Au cours de la dernière décennie, plus d’un million d’étoiles ont été surveillées pour identifier les planètes en transit. L’interprétation manuelle des candidats potentiels aux exoplanètes demande beaucoup de travail et est sujette à l’erreur humaine, dont les conséquences sont difficiles à évaluer. Les réseaux neuronaux convolutifs sont aptes à identifier des exoplanètes semblables à la Terre dans des données chronologiques bruyantes avec une précision plus proéminente qu’une stratégie des moindres carrés.
- Chasse aux exoplanètes à l’aide de l’apprentissage automatique – Chasser des mondes au-delà de notre système solaire.
- Intelligence artificielle, données de la NASA utilisées pour découvrir une exoplanète – Notre système solaire est maintenant à égalité pour le plus grand nombre de planètes autour d’une seule étoile.
Régénération d’image pour une vieille photo de bobine endommagée

Source Pikist.
Je sais combien il est long et pénible de récupérer votre vieille photo endommagée dans la forme originale comme elle était auparavant. Donc, cela peut être fait en utilisant l’apprentissage profond en trouvant tous les défauts de l’image (fractures, éraflures, trous), et en utilisant des algorithmes d’inpainting, de sorte que l’on peut facilement découvrir les défauts basés sur les valeurs des pixels autour d’eux pour restaurer et coloriser les vieilles photos.
- Colorisation et restauration de vieilles images avec l’apprentissage profond – Coloriser des images en noir et blanc avec l’apprentissage profond est devenu une vitrine impressionnante pour l’application dans le monde réel.
- Guide de l’inpainting d’image : Utiliser l’apprentissage automatique pour éditer et corriger les défauts des photos
- Comment effectuer une restauration d’image absolument sans données
Génération de musique à l’aide de l’apprentissage profond

Photo d’Abigail Keenan sur Unsplash.
La musique est un assortiment de tonalités de différentes fréquences. Ainsi, la génération automatique de musique est un processus de composition d’un court morceau de musique avec le moins de médiation humaine possible. Récemment, l’ingénierie d’apprentissage profond est devenue l’avant-garde pour la génération de musique programmée.
- Génération de musique à l’aide de l’apprentissage profond
- Comment générer de la musique à l’aide d’un réseau neuronal LSTM dans Keras – Une introduction à la création de musique à l’aide de réseaux neuronaux LSTM
Mot final
Je sais que c’est une véritable lutte pour construire un portefeuille de sciences des données cool. Mais avec une telle collection que j’ai fournie ci-dessus, vous pouvez faire des progrès supérieurs à la moyenne dans ce domaine. La collection est nouvelle, ce qui donne l’opportunité à des fins de recherche aussi. Ainsi, les chercheurs en science des données peuvent également choisir ces idées pour travailler sur ces idées afin que leur recherche soit une grande aide pour les scientifiques de données pour commencer avec le projet. De plus, il est amusant d’explorer les côtés que personne n’a fait auparavant. Bien que, cette collection constitue en fait des idées du niveau débutant au niveau avancé.
Donc, je ne le recommanderai pas seulement aux nouveaux venus dans le domaine de la science des données, mais aussi aux scientifiques de données seniors. Il ouvrira de nombreuses nouvelles voies au cours de votre carrière, non seulement en raison des projets, mais aussi grâce au réseau nouvellement acquis.
Ces idées vous montrent le large éventail de possibilités et vous donnent les idées pour sortir des sentiers battus.
Pour moi et mes amis, les facteurs d’apprentissage, la valeur ajoutée à la société et les connaissances inexplorées sont importants, et le plaisir en quelque sorte est essentiel. Donc, fondamentalement, j’aime faire de tels projets qui nous donnent un moyen d’acquérir d’immenses connaissances d’une certaine manière et nous permettent d’explorer les dimensions inexplorées. C’est notre principal objectif lorsque nous consacrons du temps à de tels projets.
Original. Reposé avec permission.
Bio : Kajal Yadav est une rédactrice indépendante spécialisée dans la science des données, les startups et l’entrepreneuriat. Elle écrit pour plusieurs publications et travaille en parallèle avec des startups sur leurs stratégies de marketing de contenu.
Related:
- Débutez votre carrière en apprentissage automatique en quarantaine
- Projets à inclure dans un portefeuille de science des données
- Comment construire un portefeuille de science des données
.