
Serhii Maksymenko,
Data Science Solution Architect
Technologia rozpoznawania twarzy jawi się dziś w innym świetle. Przypadki użycia obejmują szerokie zastosowanie, od wykrywania przestępstw po identyfikację chorób genetycznych.
Podczas gdy rządy na całym świecie inwestują w systemy rozpoznawania twarzy, niektóre amerykańskie miasta, takie jak Oakland, Somerville i Portland, zakazały ich stosowania z powodu obaw dotyczących praw obywatelskich i prywatności.
Co to jest – bomba zegarowa czy przełom technologiczny? Ten artykuł otwiera czym jest rozpoznawanie twarzy z perspektywy technologii i jak głębokie uczenie zwiększa jego możliwości. Tylko dzięki uświadomieniu sobie, jak technologia rozpoznawania twarzy działa od środka, można zrozumieć, do czego jest zdolna.
Uaktualnienie 06/09/2020: Masked face detection and recognition
How Deep Learning Can Modernize Face Recognition Software
Pobierz PDF
How Does Facial Recognition Work?
Komputerowy algorytm oprogramowania do rozpoznawania twarzy przypomina nieco rozpoznawanie wzroku przez człowieka. Ale jeśli ludzie przechowują dane wizualne w mózgu i automatycznie przywołują dane wizualne, gdy są potrzebne, komputery powinny zażądać danych z bazy danych i dopasować je, aby zidentyfikować ludzką twarz.
W skrócie, skomputeryzowany system wyposażony w kamerę, wykrywa i identyfikuje ludzką twarz, wydobywa cechy twarzy takie jak odległość między oczami, długość nosa, kształt czoła i kości policzkowych. Następnie, system rozpoznaje twarz i dopasowuje ją do obrazów przechowywanych w bazie danych.
Jednakże, tradycyjna technologia rozpoznawania twarzy nie jest jeszcze w pełni doskonała. Ma ona zarówno mocne, jak i słabe strony:
| Siła
Bezkontaktowa identyfikacja biometryczna Do jednej sekundy przetwarzania danych Kompatybilność z większością aparatów fotograficznych Łatwość integracji |
Słabe strony
Tw. i uprzedzenia rasowe Kwestie związane z prywatnością danych Ataki prezentacyjne (PA) Niska dokładność w słabych warunkach oświetleniowych |
Zdanie sobie sprawy ze słabości systemów rozpoznawania twarzy, naukowcy poszli dalej. Stosując tradycyjne techniki widzenia komputerowego i algorytmy głębokiego uczenia, dostroili system rozpoznawania twarzy, aby zapobiec atakom i zwiększyć dokładność. Tak właśnie działa technologia antyspoofingu twarzy.
How Deep Learning Upgrades Face Recognition Software
Głębokie uczenie jest jednym z najbardziej nowatorskich sposobów ulepszania technologii rozpoznawania twarzy. Pomysł polega na wyodrębnieniu embeddingów twarzy z obrazów zawierających twarze. Takie embeddingi twarzy będą unikalne dla różnych twarzy. A trening głębokiej sieci neuronowej jest najbardziej optymalnym sposobem na wykonanie tego zadania.
Zależnie od zadania i ram czasowych, istnieją dwie popularne metody wykorzystania głębokiego uczenia do systemów rozpoznawania twarzy:
Użyj wstępnie wytrenowanych modeli, takich jak dlib, DeepFace, FaceNet i inne. Ta metoda wymaga mniej czasu i wysiłku, ponieważ wstępnie wytrenowane modele mają już zestaw algorytmów do celów rozpoznawania twarzy. Możemy również dostroić wstępnie wytrenowane modele, aby uniknąć uprzedzeń i pozwolić systemowi rozpoznawania twarzy działać poprawnie.
Rozwój sieci neuronowej od podstaw. Ta metoda jest odpowiednia dla złożonych systemów rozpoznawania twarzy o wielofunkcyjnej funkcjonalności. Zajmuje więcej czasu i wysiłku oraz wymaga milionów obrazów w zbiorze danych treningowych, w przeciwieństwie do wstępnie wytrenowanego modelu, który wymaga tylko tysięcy obrazów w przypadku uczenia transferowego.

Ale jeśli system rozpoznawania twarzy zawiera unikalne cechy, może to być optymalny sposób na dłuższą metę. Kluczowe punkty, na które należy zwrócić uwagę, to:
- Poprawny wybór architektury CNN i funkcji straty
- Optymalizacja czasu wnioskowania
- Moc sprzętu
Przy opracowywaniu architektury sieci zaleca się stosowanie konwolwentowych sieci neuronowych (CNN), ponieważ okazały się one skuteczne w zadaniach rozpoznawania i klasyfikacji obrazów. Aby uzyskać oczekiwane rezultaty, lepiej jest użyć ogólnie przyjętej architektury sieci neuronowej jako podstawy, na przykład ResNet lub EfficientNet.
Trenując sieć neuronową dla celów rozwoju oprogramowania do rozpoznawania twarzy, powinniśmy w większości przypadków minimalizować błędy. W tym przypadku kluczowe jest rozważenie funkcji straty używanych do obliczania błędu pomiędzy rzeczywistym a przewidywanym wyjściem. Najczęściej stosowanymi funkcjami w systemach rozpoznawania twarzy są strata potrójna oraz AM-Softmax.
- Trójkowa funkcja straty zakłada posiadanie trzech obrazów dwóch różnych osób. Są to dwa obrazy – kotwica i pozytyw – dla jednej osoby, a trzeci – negatyw – dla drugiej osoby. Parametry sieci są uczone tak, aby zbliżyć te same osoby w przestrzeni cech, a rozdzielić różne osoby.
- FunkcjaAM-Softmax jest jedną z najnowszych modyfikacji standardowej funkcji softmax, która wykorzystuje szczególną regularyzację opartą na addytywnym marginesie. Pozwala ona na osiągnięcie lepszej separowalności klas, a tym samym poprawia dokładność systemu rozpoznawania twarzy.
Istnieje również kilka podejść do ulepszania sieci neuronowych. W systemach rozpoznawania twarzy najciekawsze z nich to destylacja wiedzy, uczenie transferowe, kwantyzacja oraz konwolucje z separacją głębokości.
- Destylacja wiedzy dotyczy dwóch sieci o różnej wielkości, gdy duża sieć uczy swoją mniejszą odmianę. Kluczową wartością jest to, że po treningu mniejsza sieć działa szybciej niż duża, dając ten sam wynik.
- Podejście oparte na uczeniu transferowym pozwala na poprawę dokładności poprzez trening całej sieci lub tylko niektórych warstw na określonym zbiorze danych. Na przykład, jeśli system rozpoznawania twarzy ma problemy z uprzedzeniami rasowymi, możemy wziąć określony zestaw obrazów, powiedzmy, zdjęcia Chińczyków, i trenować sieć tak, aby osiągnąć wyższą dokładność.
- Podejście kwantyzacji poprawia sieć neuronową, aby osiągnąć wyższą prędkość przetwarzania. Poprzez aproksymację sieci neuronowej, która używa liczb zmiennoprzecinkowych, siecią neuronową o małej szerokości bitowej, możemy zmniejszyć rozmiar pamięci i liczbę obliczeń.
- Depthwise separable convolutions jest klasą warstw, które pozwalają budować CNN z dużo mniejszym zestawem parametrów w porównaniu do standardowych CNN. Przy niewielkiej liczbie obliczeń, cecha ta może usprawnić system rozpoznawania twarzy tak, aby nadawał się do zastosowań w mobilnych aplikacjach wizyjnych.
Kluczowym elementem technologii głębokiego uczenia jest zapotrzebowanie na sprzęt o dużej mocy obliczeniowej. Podczas wykorzystywania głębokich sieci neuronowych do tworzenia oprogramowania do rozpoznawania twarzy, celem jest nie tylko zwiększenie dokładności rozpoznawania, ale także skrócenie czasu reakcji. Dlatego na przykład procesor graficzny jest bardziej odpowiedni dla systemów rozpoznawania twarzy opartych na głębokim uczeniu niż procesor centralny.
Jak wdrożyliśmy aplikację do rozpoznawania twarzy opartą na głębokim uczeniu
Podczas rozwijania Big Brothera (aplikacji z kamerą demonstracyjną) w MobiDev, naszym celem było stworzenie oprogramowania do weryfikacji biometrycznej ze strumieniowaniem wideo w czasie rzeczywistym. Będąc aplikacją konsolową dla Ubuntu i Raspbiana, Big Brother został napisany w Golangu i skonfigurowany z lokalnym ID kamery i typem czytnika kamery poprzez plik konfiguracyjny JSON. Ten film opisuje, jak Big Brother działa w praktyce:
Od wewnątrz, cykl pracy aplikacji Big Brother obejmuje:
1. Wykrywanie twarzy
Aplikacja wykrywa twarze w strumieniu wideo. Po przechwyceniu twarzy, obraz jest przycinany i wysyłany do back-end poprzez żądanie HTTP form-data. API back-end zapisuje obraz do lokalnego systemu plików i zapisuje rekord do Detection Log z personID.
Sterowanie back-end wykorzystuje Golang i MongoDB Collections do przechowywania danych pracowników. Wszystkie żądania API są oparte na RESTful API.

2. Błyskawiczne rozpoznawanie twarzy
Dolny koniec ma pracownika tła, który znajduje nowe niesklasyfikowane rekordy i używa Dlib do obliczenia 128-wymiarowego wektora deskryptora cech twarzy. Za każdym razem, gdy wektor jest obliczany, jest on porównywany z wieloma referencyjnymi obrazami twarzy poprzez obliczanie odległości euklidesowej do każdego wektora cech każdej osoby w bazie danych, znajdując dopasowanie.
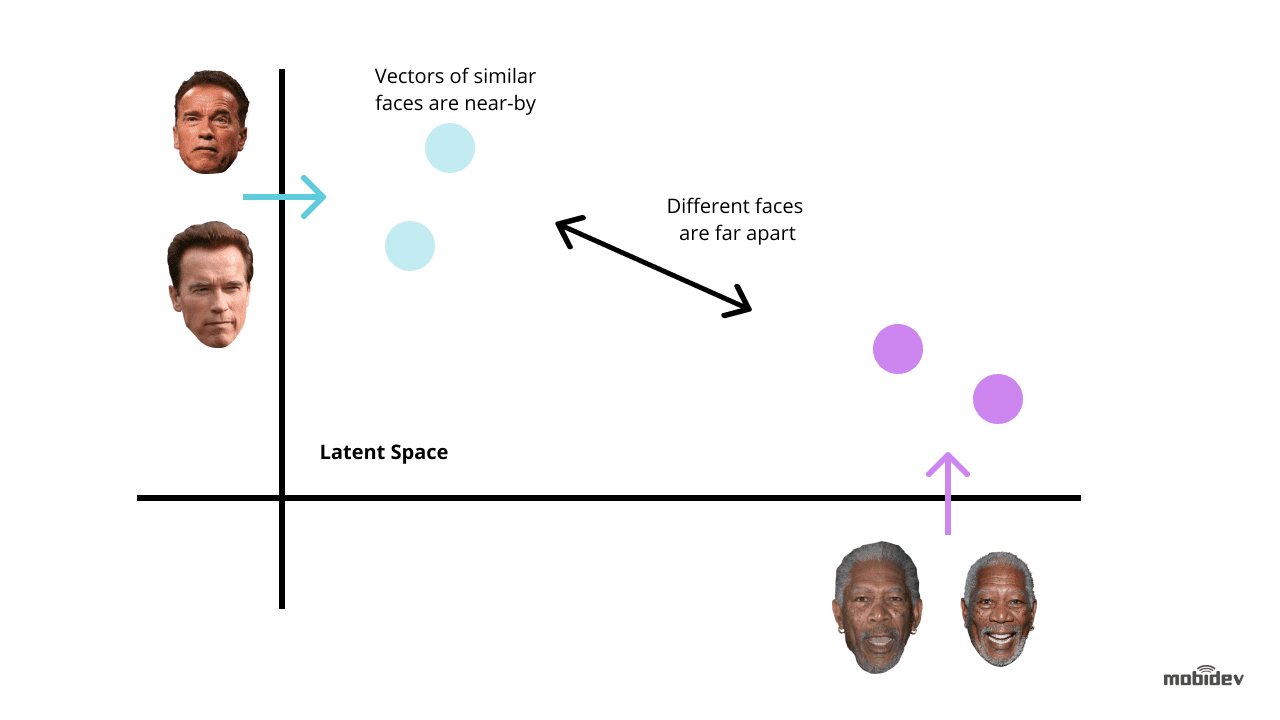
Jeśli odległość euklidesowa do wykrytej osoby jest mniejsza niż 0,6, robotnik ustawia identyfikator osoby w dzienniku wykrywania i oznacza ją jako sklasyfikowaną. Jeśli odległość przekracza 0,6, tworzy nowy Person ID do dziennika.
3. Działania następcze: ostrzeganie, przyznawanie dostępu i inne
Zdjęcia niezidentyfikowanej osoby są wysyłane do odpowiedniego menedżera z powiadomieniami poprzez chatboty w komunikatorach. W aplikacji Big Brother wykorzystaliśmy Microsoft Bot Framework i opartego na Pythonie Errbota, co pozwoliło nam zaimplementować chatbota alarmowego w ciągu pięciu dni.

Potem można zarządzać tymi rekordami poprzez panel administratora, który przechowuje zdjęcia z identyfikatorami w bazie danych. Oprogramowanie do rozpoznawania twarzy działa w czasie rzeczywistym i wykonuje zadania rozpoznawania twarzy natychmiast. Wykorzystując kolekcje Golang i MongoDB do przechowywania danych pracowników, wprowadziliśmy do bazy danych IDs, w tym 200 wpisów.
Oto jak zaprojektowana jest aplikacja do rozpoznawania twarzy Big Brothera:
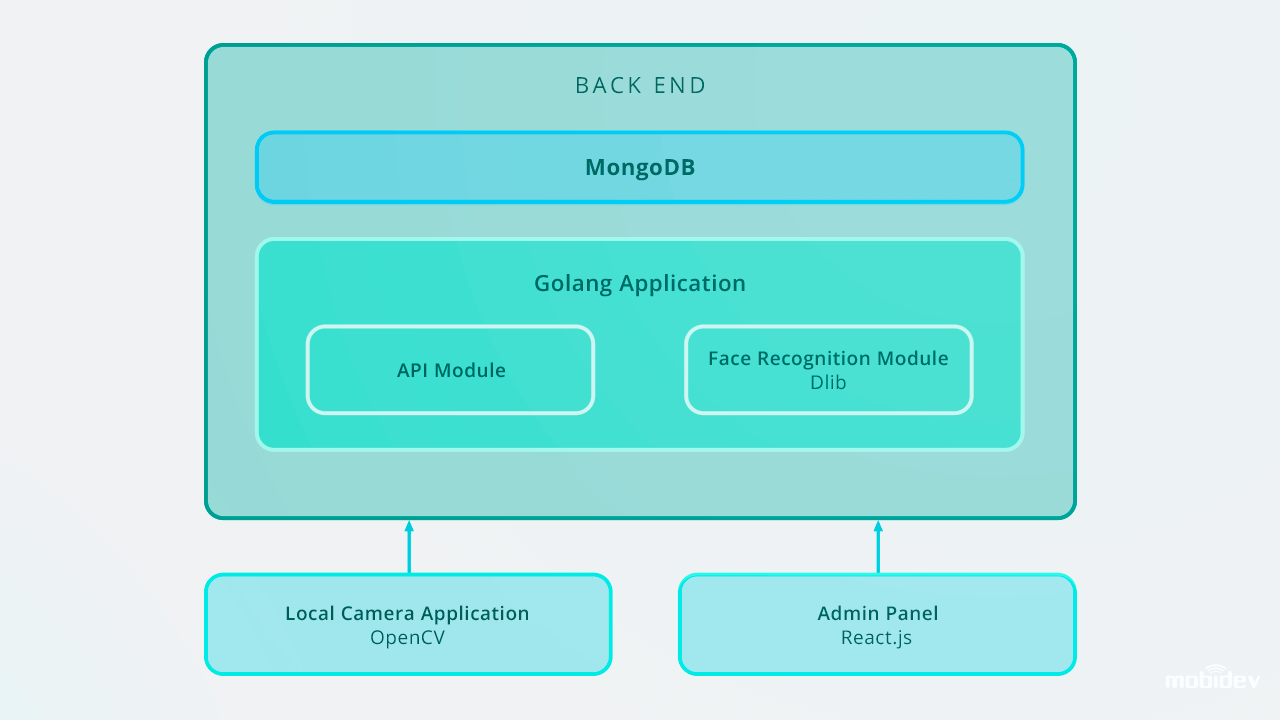
W przypadku skalowania do 10 000 wpisów, zalecalibyśmy ulepszenie systemu rozpoznawania twarzy w celu utrzymania wysokiej prędkości rozpoznawania na zapleczu. Jednym z optymalnych sposobów jest użycie paralelizacji. Poprzez skonfigurowanie load balancera i zbudowanie kilku robotników webowych możemy zapewnić prawidłową pracę części back-endowej i optymalną szybkość całego systemu.
Inne przypadki użycia Deep Learning-Based Recognition
Rozpoznawanie twarzy nie jest jedynym zadaniem, w którym rozwój oprogramowania oparty na głębokim uczeniu może zwiększyć wydajność. Inne przykłady obejmują:
Wykrywanie i rozpoznawanie twarzy zamaskowanych
Odkąd COVID-19 zmusił ludzi w wielu krajach do noszenia masek na twarz, technologia rozpoznawania twarzy stała się bardziej zaawansowana. Dzięki zastosowaniu algorytmu głębokiego uczenia opartego na konwencjonalnych sieciach neuronowych, kamery mogą teraz rozpoznawać twarze zakryte maskami. Inżynierowie data science wykorzystują takie algorytmy, jak modele rozpoznawania wieloocznego i okołoocznego, aby zwiększyć możliwości systemu rozpoznawania twarzy. Poprzez identyfikację takich cech twarzy jak czoło, kontur twarzy, szczegóły oczne i okołooczne, brwi, oczy i kości policzkowe, modele te pozwalają na rozpoznawanie zamaskowanych twarzy z dokładnością do 95%.
Dobrym przykładem takiego systemu jest technologia rozpoznawania twarzy stworzona przez jedną z chińskich firm. System składa się z dwóch algorytmów: rozpoznawania twarzy opartego na głębokim uczeniu oraz termowizyjnego pomiaru temperatury w podczerwieni. Kiedy osoby w maskach stają przed kamerą, system wyodrębnia rysy twarzy i porównuje je z istniejącymi obrazami w bazie danych. Jednocześnie mechanizm pomiaru temperatury za pomocą termowizji na podczerwień mierzy temperaturę, wykrywając w ten sposób osoby o nieprawidłowej temperaturze.
Wykrywanie wad
W ciągu ostatnich kilku lat producenci wykorzystywali opartą na AI inspekcję wizualną do wykrywania wad. Rozwój algorytmów głębokiego uczenia się pozwala temu systemowi na automatyczne definiowanie najdrobniejszych rys i pęknięć, unikając czynnika ludzkiego.
Wykrywanie nieprawidłowości w ciele
Izraelska firma Aidoc opracowała napędzane głębokim uczeniem rozwiązanie dla radiologii. Analizując obrazy medyczne, system ten wykrywa nieprawidłowości w klatce piersiowej, kręgosłupie, głowie i brzuchu.
Identyfikacja mówcy
Technologia identyfikacji mówcy stworzona przez firmę Phonexia również identyfikuje mówców, wykorzystując podejście oparte na metrycznym uczeniu się. System rozpoznaje mówców po głosie, tworząc matematyczne modele ludzkiej mowy zwane voiceprintami. Te voiceprinty są przechowywane w bazach danych, a kiedy dana osoba mówi, technologia identyfikacji mówcy identyfikuje unikalny voiceprint.
Rozpoznawanie emocji
Rozpoznawanie ludzkich emocji jest dziś zadaniem możliwym do wykonania. Śledząc ruchy twarzy za pomocą kamery, technologia Emotion Recognition kategoryzuje ludzkie emocje. Algorytm głębokiego uczenia identyfikuje punkty orientacyjne ludzkiej twarzy, wykrywa neutralny wyraz twarzy i mierzy odchylenia wyrazu twarzy, rozpoznając bardziej pozytywne lub negatywne.
Rozpoznawanie akcji
Visual Jedna z firm, która jest dostawcą Nest Cams, zasilała swój produkt sztuczną inteligencją. Wykorzystując techniki głębokiego uczenia się, dostroili Nest Cams do rozpoznawania nie tylko różnych obiektów, takich jak ludzie, zwierzęta domowe, samochody, itp. Zestaw działań, które mają być rozpoznawane jest konfigurowalny i wybierany przez użytkownika. Na przykład, kamera może rozpoznać kota drapiącego drzwi, lub dziecko bawiące się z piecem.
Jeśli podsumować, głębokie sieci neuronowe są potężnym narzędziem dla ludzkości. I tylko człowiek decyduje o tym, jaka technologiczna przyszłość nadejdzie za chwilę.
How Deep Learning Can Modernize Face Recognition Software
Pobierz PDF
.