Voice registers explained by Andy Follin
Vocal registers are one of the most talked about – and yet still misunderstood – concepts in voice training. Już w latach 70-tych XX wieku Collegium Medicorum Theatri (CoMeT) – międzynarodowa organizacja zrzeszająca specjalistów od emisji głosu – utworzyła komitet, którego zadaniem było podjęcie próby wyjaśnienia pojęcia rejestrów głosowych. Fakt, że debata nadal szaleje prawie pięćdziesiąt lat później jest wskazówką, jak mylące to pojęcie może być.
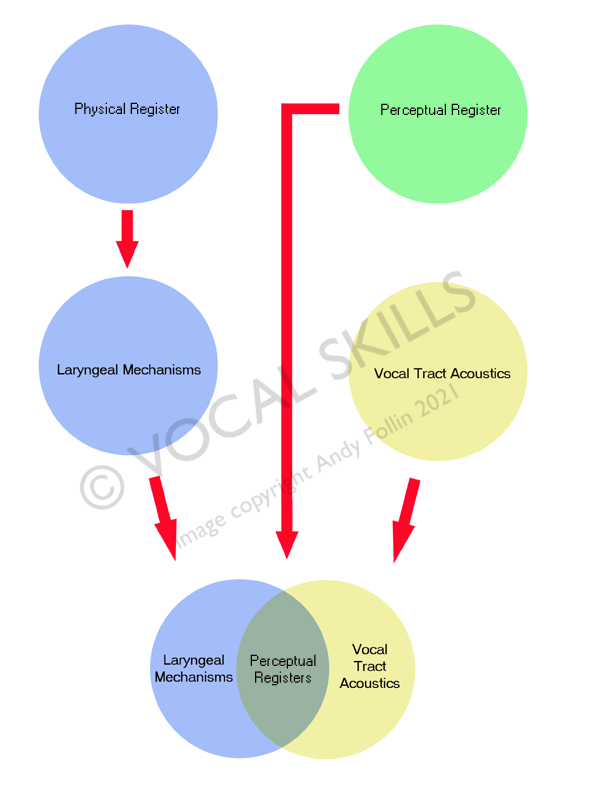
Dezorientacja pochodzi z faktu, że termin „rejestr” oznacza różne rzeczy dla różnych ludzi. Przyjęta definicja mówi, że rejestr to „seria następujących po sobie tonów o podobnych właściwościach”. Ale jakie są te właściwości zależy od punktu widzenia.
- Z czysto krtaniowej perspektywy, rejestr może być zdefiniowany jako seria następujących po sobie tonów produkowanych przez ten sam mechanizm.
- Z akustycznej / percepcyjnej perspektywy, rejestr może być zdefiniowany jako seria następujących po sobie tonów produkowanych z podobną jakością głosu.
Mimo że istnieje pewna korelacja między terminologią rejestrów a mechanizmami zaangażowanymi w ich produkcję, ważne jest rozróżnienie między terminami „mechanizm” i „rejestr”.
Najprostszym sposobem dokonania tego rozróżnienia jest odwołanie się do rejestrów naukowych (tj. mechanicznych) i rejestrów śpiewaczych (tj. percepcyjne)
Rejestry naukowe
Anatomia fałdu głosowego
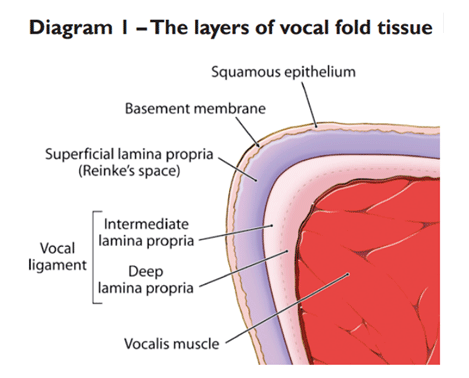
Fałdy głosowe to złożone struktury, składające się z mięśni, więzadeł, skóry i tkanki łącznej. Przekrój poprzeczny wykazuje co najmniej pięć odrębnych warstw (zob. schemat 1).
Głosolog i badacz Minoru Hirano (1974) wprowadził model anatomii fałdów głosowych oparty na modelu „ciało-pokrywa”, w którym pięć warstw tkanki fałdów głosowych można podzielić na dwa elementy – ciało i pokrywę.
W tym modelu pokrywa składa się z dwóch górnych warstw (nabłonek i warstwa powierzchowna blaszki właściwej). Ciało składa się z trzech dolnych warstw (włókien mięśniowych oraz pośredniej i głębokiej warstwy lamina propria, które tworzą więzadło głosowe).
Używając modelu Ciało-Pokrywa wyjaśnionego powyżej, możemy zdefiniować „rejestry” w kategoriach tego, które części fałdu głosowego drgają – Mechanizm Krtaniowy.
Badania przeprowadzone w ostatnich latach (przez Natalie Henrich i innych) zidentyfikowały cztery różne Mechanizmy Krtaniowe, ponumerowane od 0 do 3:
- M0 – gdzie zarówno Ciało jak i Pokrywa są luźne.
- M1 – gdzie zarówno korpus, jak i pokrywa wibrują.
- M2 – gdzie korpus już nie wibruje.
- M3 – gdzie fałdy głosowe są bardzo cienkie i bardzo mocno napięte, a wibruje tylko pokrywa, często z niepełnym zamknięciem fałdów.
Podjęto decyzję o ponumerowaniu mechanizmów krtaniowych, a nie nazwaniu ich, aby odejść od mylących i nieścisłych pojęć rejestrów/głosów „głowy” i „klatki piersiowej”.
Ale jeśli chcesz zrozumieć mechanizmy krtaniowe w innych, bardziej znanych terminach:
- M0 to frytka głosowa, luźne fałdy, Strohbass.
- M1 to głos modalny, grube fałdy, ciężki, 'głos piersiowy’, Mix, Middle.
- M2 to cienkie fałdy, krzyk, lekki, wyniosły, głos 'głowy’ (czasami mylnie nazywany falsetem), Mix, Middle.
- M3 to gwizd, sztywne fałdy.
Zauważysz, że 'Mix’ i 'Middle’ są wymienione zarówno jako M1 i M2. To dlatego, że piosenkarze mają dostęp do ich 'Mix’ na różne sposoby, jak wyjaśniono w tym artykule: Czym jest głos 'Mixed’?
Rejestry śpiewu
Ale chociaż drgania fałdów głosowych mogą być dokładnie określone pod względem zastosowanego mechanizmu krtaniowego, dźwięki wytwarzane przez indywidualny mechanizm mogą mieć duże różnice w barwie i intensywności, ze względu na kształtowanie traktu głosowego.
Trakt głosowy jest miejscem, w którym śpiewacy określają właściwości akustyczne dźwięku, takie jak barwa, rezonans i język (samogłoski i spółgłoski). Z tego powodu, omawiając rejestr śpiewu, musimy wziąć pod uwagę efekty tego, co możemy określić jako zdarzenia rejestracji akustycznej – na przykład fakt, że pewne dźwięki samogłosek faworyzują pewne dźwięki lub barwy. W artykule Belting wyjaśnione, omawiam dwie podstawowe interakcje traktu głosowego z drganiami fałdów głosowych – Yell timbre i Whoop timbre, dwa odrębne dźwięki, które każdy śpiewak lub słuchacz może rozróżnić bez szczególnej potrzeby zrozumienia, co się dzieje.
Dla pełnego zrozumienia rejestrów śpiewu, musielibyśmy spojrzeć bardziej szczegółowo na akustyczne zdarzenia rejestracyjne, takie jak pasywne lub aktywne modyfikacje samogłosek, ale to jest poza zakresem tego artykułu. Wystarczy powiedzieć, że śpiewacy w dużej mierze polegają na akustycznym i percepcyjnym sprzężeniu zwrotnym. Chociaż to sprzężenie zwrotne jest osobiste, ważne jest, aby móc omawiać głos ze śpiewakami w tych kategoriach, ponieważ dźwięk i związane z nim doznania są często wszystkim, na czym mogą się oprzeć.
W moim artykule „Głowa” i „klatka piersiowa” głos wyjaśnione staram się oddzielić pojęcia „Głos” i „Rejestr” poprzez wyjaśnienie ich z perspektywy fałdów głosowych i traktu głosowego. W podobny sposób możemy próbować zrozumieć rejestry naukowy i śpiewny w następujący sposób:
- Rejestr naukowy – Mechanizm krtaniowy (fałdy głosowe)
- Rejestr śpiewu – Jakość głosu (interakcja fałdy głosowe / trakt głosowy)
Niestety, każda dyskusja, która opiera się na postrzeganiu dźwięku i odczuć przez śpiewaków, z konieczności zaczyna być niejasna i subiektywna, stąd też widzimy tak wiele debat na temat „głowy i klatki piersiowej” versus „pasa” i „falsetu” itp.
Ale jakkolwiek nazwiesz jakość głosu, głos nadal podlega tym samym naturalnym prawom i jest produkowany przez struktury fizyczne. Moje osobiste podejście jest takie, że dobrze jest opisać swój głos w kategoriach tego, jak się czuje i brzmi dla ciebie – i „nazwać” go odpowiednio jako rejestr śpiewu – ale zrozumienie mechanizmu produkującego ten dźwięk (rejestr naukowy) jest bardzo pomocne i może wyeliminować wiele wątpliwości i zamieszania.
Problem z wysokością dźwięku
Ale chociaż elastyczne, fałdy głosowe wciąż mają fizyczne ograniczenia. Gdy śpiewasz wyżej w wibracji M1 (Body and Cover, Thick, 'Chest’), tkanki fałdów głosowych rozciągają się. Do pewnej wyższej wysokości (innej u każdego człowieka, ale około B3 do F4) Ciało nadal jest zaangażowane w wibrację. Poza tym punktem, ciało nie może się rozciągnąć i odłącza się, pozostawiając pokrywę do wibracji sam (M2, cienki, „głowa”)
Podobnie, podczas śpiewania z wysokiego do niskiego w M2 wibracji, pokrywa będzie drgać sam, aż do osiągnięcia pewnej niższej wysokości, w którym to momencie ciało będzie gwałtownie wznowić swoje wibracje.
W niewytrenowanego piosenkarza, te przejścia w i z M1 i M2 będzie słychać jako „przerwy”, „pęknięcia” i „jodły”. Wyszkolony śpiewak rozpoznaje te punkty przejściowe i uczy się manipulować innymi czynnikami, aby zminimalizować efekty.
Przejścia rejestrowe zdarzają się wszystkim śpiewakom – ci dobrzy po prostu uczą się je maskować!
Głos 'Mix’
Zakresy częstotliwości wytwarzane przez dwa kolejne mechanizmy częściowo nakładają się na siebie, czasem nawet o oktawę. Mieszanie lub 'miksowanie’ (aka 'śpiewanie w miksie’) jest techniką wokalną wykorzystywaną w tym nakładającym się regionie, w celu ukrycia przejścia z jednego mechanizmu do drugiego.
Może to być mylące pojęcie dla śpiewaków, którzy polegają w dużej mierze na percepcji, ponieważ nie czuje się ani czystego M1 ani czystego M2. Ale to nie jest oddzielny rejestr naukowy.
W pełni wyjaśniam to w tym artykule: What is the 'Mixed’ voice?
Idealna technika
Wyzwaniem dla profesjonalnego śpiewaka jest nauczenie się, jak utrzymać pewien mechanizm poza granicami jego naturalnego stanu atraktora, LUB pozwolić temu mechanizmowi zmieniać się i manipulować innymi strukturami, aby utrzymać spójność dźwięku.
Wspaniała technika pochodzi z solidnego zrozumienia mechanizmów krtaniowych i tego, jak można je wykorzystać. Masa fałdu głosowego, kompresja przyśrodkowa, efekty rezonansowe itd. przyczyniają się do ogólnej jakości głosu. Posiadanie niezależnej, wyodrębnionej kontroli nad każdym z tych elementów daje śpiewakowi możliwość mieszania i dostosowywania dźwięku w bardzo subtelny sposób.
Każdy głos śpiewaka musi zmieniać mechanizmy w różnych punktach zakresu. Umiejętny piosenkarz uczy się ukrywać te zmiany – stąd dlaczego, do słuchacza, to może brzmieć tak, jakby piosenkarz jest w tym samym mechanizmie. Na przykład, gdy słyszysz śpiewaczkę z mocną wysoką nutą, możesz wierzyć, że śpiewa ona w M1. Ale jeśli ta nuta jest poza naturalną granicą jej M1, ona rzeczywiście śpiewa w M2 i sprawia, że brzmi jak M1 – definicja 'Mix’.
making różne rzeczy brzmią tak samo
To jest to błędne przekonanie, które często prowadzi niewyszkolonych lub niedoświadczonych śpiewaków do pchania i wymuszania głosu, błędnie myśląc, że mogą wziąć M1 do tych wyższych dźwięków.
Pomyśl o tym – cały punkt tej techniki jest ukrycie naturalnych zmian fizycznych, które zdarzają się, gdy śpiewasz przez cały swój zakres wokalny. Jeśli słyszysz te zmiany, twoja technika jest wadliwa!
Doskonała technika w pigułce: sprawianie, by różne rzeczy brzmiały tak samo.