
Jako że wszyscy wkraczamy w trzeci miesiąc pandemii COVID-19 i szukamy nowych projektów, które pozwolą nam zachować zaangażowanie (czytaj: zdrowy rozsądek), czy możemy zainteresować Was nauką podstaw komputerowej pamięci masowej? Po cichu, tej wiosny, omówiliśmy już kilka niezbędnych podstaw, takich jak testowanie szybkości dysków i czym do cholery jest RAID. W drugiej z tych historii obiecaliśmy nawet kontynuację, badającą wydajność różnych topologii wielodyskowych w ZFS, systemie plików nowej generacji, o którym słyszeliście z powodu jego pojawienia się wszędzie, od Apple po Ubuntu.
No cóż, dziś jest dzień na odkrywanie, czytelnicy ciekawi ZFS. Wiedzcie jednak, że według słów twórcy OpenZFS Matta Ahrensa, „to naprawdę skomplikowane.”
Ale zanim przejdziemy do liczb – a one już nadchodzą, obiecuję!-musimy porozmawiać o tym, jak ZFS w ogóle przechowuje dane na dysku.
Zpoole, vdev i urządzenia

Aby naprawdę zrozumieć ZFS, musisz zwrócić uwagę na jego strukturę. ZFS łączy tradycyjne warstwy zarządzania woluminami i systemu plików, oraz używa mechanizmu transakcyjnego copy-on-write – oba te elementy oznaczają, że system jest strukturalnie inny niż konwencjonalne systemy plików i macierze RAID. Pierwszym zestawem głównych bloków, które należy zrozumieć, są zpools, vdevs i devices.
zpool
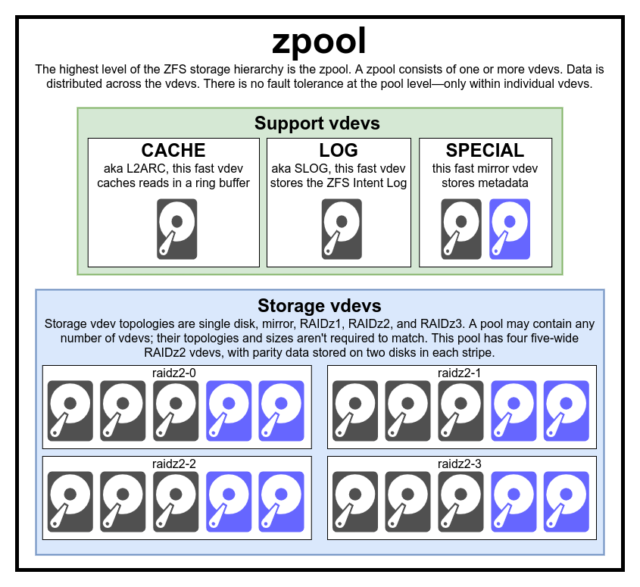
zpool jest najwyższą strukturą ZFS. Zpool zawiera jeden lub więcej vdevs, z których każdy z kolei zawiera jeden lub więcej devices. Zpoole są samodzielnymi jednostkami – jeden komputer fizyczny może mieć dwa lub więcej oddzielnych zpooli, ale każdy z nich jest całkowicie niezależny od pozostałych. Zpoole nie mogą współdzielić vdevs ze sobą.
Nadmiarowość ZFS jest na poziomie vdev, nie na poziomie zpool. Nie ma absolutnie żadnej redundancji na poziomie zpooli – jeśli jakikolwiek magazyn vdev lub SPECIAL vdev zostanie utracony, cały zpool zostanie utracony wraz z nim.
Nowoczesne zpoole mogą przetrwać utratę CACHE lub LOG vdev – chociaż mogą stracić niewielką ilość brudnych danych, jeśli stracą LOG vdev podczas przerwy w dostawie prądu lub awarii systemu.
Powszechne jest błędne przekonanie, że ZFS „paskuje” zapisy w całej puli – ale jest to niedokładne. Zpool nie jest śmiesznie wyglądającym RAID0-em, jest śmiesznie wyglądającym JBOD-em, ze złożonym mechanizmem dystrybucji, który może ulec zmianie.
W większości przypadków, zapisy są rozdzielane na dostępne vdev-y zgodnie z ich dostępną wolną przestrzenią, więc teoretycznie wszystkie vdev-y zapełnią się w tym samym czasie. W nowszych wersjach ZFS, wykorzystanie vdevów może być również brane pod uwagę – jeśli jeden vdev jest znacznie bardziej zajęty niż inny (np. z powodu obciążenia odczytem), może być tymczasowo pominięty przy zapisie, pomimo posiadania najwyższego współczynnika wolnego miejsca.
Mechanizm świadomości wykorzystania wbudowany w nowoczesne metody dystrybucji zapisu ZFS może zmniejszyć opóźnienia i zwiększyć przepustowość w okresach niezwykle wysokiego obciążenia, ale nie powinien być mylony z carte blanche do mieszania wolnych dysków z rdzy i szybkich SSD w tej samej puli. Taka niedopasowana pula nadal będzie działać tak, jakby w całości składała się z najwolniejszego obecnego urządzenia.
vdev
Każdy zpool składa się z jednego lub więcej vdevs (skrót od virtual device). Każdy vdev z kolei składa się z jednego lub więcej rzeczywistych devices. Większość urządzeń vdev jest używana do zwykłej pamięci masowej, ale istnieje również kilka specjalnych klas wsparcia vdev – w tym CACHE, LOG i SPECIAL. Każdy z tych typów vdev może oferować jedną z pięciu topologii – single-device, RAIDz1, RAIDz2, RAIDz3 lub mirror.
RAIDz1, RAIDz2 i RAIDz3 są specjalnymi odmianami tego, co szarzy wyjadacze pamięci masowej nazywają „diagonalną parzystością RAID”. 1, 2 i 3 odnoszą się do tego, ile bloków parzystości jest przypisanych do każdego paska danych. Zamiast całych dysków przeznaczonych na parzystość, urządzenia vdev RAIDz rozdzielają parzystość pół-równomiernie pomiędzy dyski. Macierz RAIDz może stracić tyle dysków, ile ma bloków parzystości; jeśli straci kolejny, to nie powiedzie się, i bierze zpool w dół z nim.
Mirror vdevs są dokładnie to, co brzmi jak w lustrzanym vdev, każdy blok jest przechowywany na każdym urządzeniu w vdev. Chociaż najczęściej spotykane są mirrory o dwóch szerokościach, mirror vdev może zawierać dowolną liczbę urządzeń – trójdrożne są powszechne w większych konfiguracjach ze względu na wyższą wydajność odczytu i odporność na błędy. Mirror vdev może przetrwać każdą awarię, tak długo, jak przynajmniej jedno urządzenie w vdev pozostaje zdrowe.
Urządzenia vdev z pojedynczym urządzeniem są również tym, na co wyglądają – i są z natury niebezpieczne. Urządzenie vdev typu single-device nie może przetrwać żadnej awarii – a jeśli jest używane jako pamięć masowa lub urządzenie vdev SPECIAL, jego awaria spowoduje upadek całego urządzenia zpool wraz z nim. Bądź bardzo, bardzo ostrożny.
CACHE, LOG, i SPECIAL vdevs mogą być utworzone przy użyciu dowolnej z powyższych topologii – ale pamiętaj, utrata SPECIAL vdev oznacza utratę puli, więc redundantna topologia jest silnie zalecana.
device
To prawdopodobnie najłatwiejszy do zrozumienia termin związany z ZFS – jest to dosłownie po prostu urządzenie blokowe o dostępie losowym. Pamiętaj, że vdevs są zrobione z pojedynczych urządzeń, a zpool jest zrobione z vdevs.
Dyski – albo rdzawe, albo solid-state – są najbardziej powszechnymi urządzeniami blokowymi używanymi jako vdev bloki konstrukcyjne. Wszystko z deskryptorem w /dev, który pozwala na dostęp losowy, będzie działać, chociaż – tak jak całe sprzętowe macierze RAID mogą być (i czasami są) używane jako pojedyncze urządzenia.
Zwykły surowy plik jest jednym z najważniejszych alternatywnych urządzeń blokowych, z których można zbudować vdev. Pule testowe wykonane z plików sparse są niezwykle wygodnym sposobem na przećwiczenie komend zpool, oraz sprawdzenie ile miejsca jest dostępne na puli lub vdev o danej topologii.

Powiedzmy, że zastanawiasz się nad zbudowaniem ośmiodyskowego serwera i jesteś pewien, że będziesz chciał użyć dysków o pojemności 10 TB (~9300 GiB), ale nie jesteś pewien, jaka topologia najlepiej odpowiada Twoim potrzebom. W powyższym przykładzie, budujemy pulę testową z plików sparse w kilka sekund – i teraz wiemy, że RAIDz2 vdev wykonany z ośmiu dysków 10TB oferuje 50TiB pojemności użytkowej.
Jest jedna specjalna klasa device – SPARE. Urządzenia Hotspare, w przeciwieństwie do zwykłych urządzeń, należą do całej puli, a nie do pojedynczego vdev. Jeśli dowolny vdev w puli ulegnie awarii, a SPARE jest dołączony do puli i dostępny, SPARE automatycznie dołączy się do zdegradowanego vdev.
Po dołączeniu do zdegradowanego vdev, SPARE zaczyna otrzymywać kopie lub rekonstrukcje danych, które powinny znajdować się na brakującym urządzeniu. W tradycyjnym RAID nazwano by to „odbudową” – w ZFS jest to „resilvering.”
Ważne jest by zauważyć, że urządzenia SPARE nie zastępują na stałe uszkodzonych urządzeń. Są one tylko zastępcze, przeznaczone do zminimalizowania okna, podczas którego vdev działa w sposób zdegradowany. Gdy administrator zastąpi uszkodzone urządzenie vdev’a, a nowe, stałe urządzenie zastępcze resilwersuje, SPARE odłącza się od vdev’a i wraca do pracy w całej puli.
Zbiory danych, bloki i sektory
Kolejny zestaw bloków, które musisz zrozumieć w swojej podróży z ZFS, odnosi się nie tyle do sprzętu, co do tego, jak dane są zorganizowane i przechowywane. Pominiemy tu kilka poziomów – takich jak metaslab – w interesie utrzymania rzeczy tak prostymi jak to tylko możliwe, ale wciąż rozumiejąc ogólną strukturę.
Zbiory danych

ZFS dataset jest z grubsza analogiczny do standardowego, zamontowanego systemu plików. Ale również jak konwencjonalne zamontowane systemy plików, każdy ZFS dataset ma swój własny zestaw podstawowych właściwości.
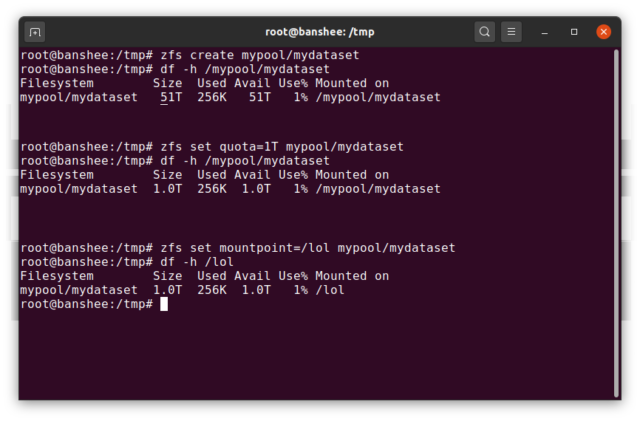
Przede wszystkim, dataset może mieć przypisaną kwotę. Jeśli zfs set quota=100G poolname/datasetname, nie będziesz mógł umieścić więcej niż 100GiB danych w zamontowanym w systemie folderze /poolname/datasetname.
Zauważasz obecność – i brak – ukośników wiodących w powyższym przykładzie? Każdy zbiór danych ma swoje miejsce zarówno w hierarchii ZFS, jak i w hierarchii montowania systemu. W hierarchii ZFS nie ma wiodących ukośników – zaczynasz od nazwy puli, a następnie ścieżki od jednego zbioru danych do następnego – np. pool/parent/child dla zbioru danych o nazwie child pod macierzystym zbiorem danych parent, w puli nazwanej twórczo pool.
Domyślnie, punkt montowania zbioru dataset będzie równoważny jego hierarchicznej nazwie ZFS, z ukośnikiem wiodącym – pula o nazwie pool jest montowana na /pool, zbiór danych parent jest montowany na /pool/parent, a zbiór podrzędny child jest montowany na /pool/parent/child. Systemowy punkt montowania zbioru danych można jednak zmienić.
Gdybyśmy zfs set mountpoint=/lol pool/parent/child, zbiór danych pool/parent/child byłby w rzeczywistości zamontowany w systemie jako /lol.
Oprócz zbiorów danych powinniśmy wspomnieć o zvols. A zvol jest z grubsza analogiczne do dataset, z tą różnicą, że nie ma w nim systemu plików – jest to po prostu urządzenie blokowe. Możesz, na przykład, stworzyć zvol o nazwie mypool/myzvol, sformatować go z systemem plików ext4, a następnie zamontować ten system plików – masz teraz system plików ext4, ale wsparty wszystkimi funkcjami bezpieczeństwa ZFS! Może to brzmieć głupio na jednym komputerze, ale ma dużo więcej sensu jako back-end dla eksportu iSCSI.
Bloki
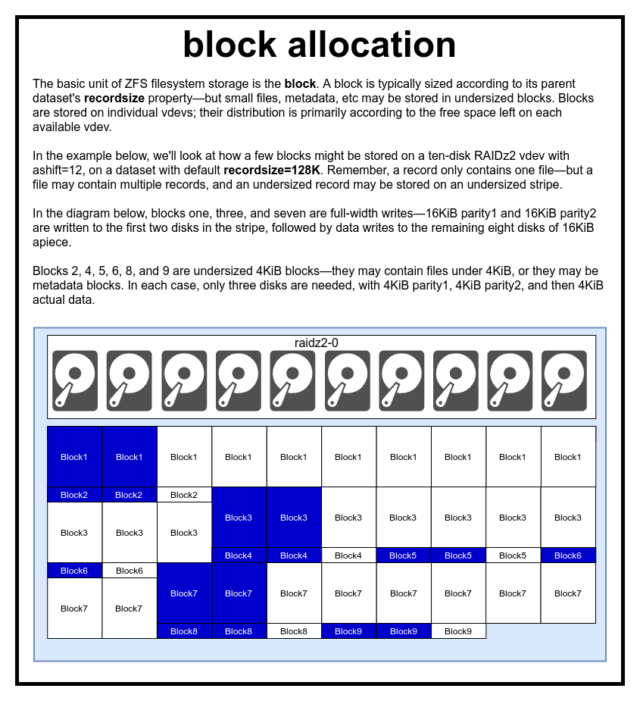

W puli ZFS, wszystkie dane-włącznie z metadanymi- są przechowywane w blocks. Maksymalny rozmiar block jest zdefiniowany dla każdego dataset we właściwości recordsize. Recordsize jest zmienny, ale zmiana recordsize nie zmieni rozmiaru ani układu żadnego z blocks, które już zostały zapisane do zbioru danych – tylko dla nowych bloków, gdy są one zapisywane.
Jeśli nie zdefiniowano inaczej, bieżącym domyślnym recordsize jest 128KiB. Reprezentuje to rodzaj niełatwego kompromisu, w którym wydajność nie będzie idealna dla wielu rzeczy, ale nie będzie też okropna dla wielu rzeczy. Recordsize może być ustawione na dowolną wartość od 4K do 1M. (Recordsize można ustawić na jeszcze większą przy dodatkowym dostrojeniu i wystarczającej determinacji, ale rzadko jest to dobry pomysł.)
Każdy podany block odwołuje się do danych z tylko jednego pliku – nie można upchnąć dwóch oddzielnych plików w tym samym block. Każdy plik będzie składał się z jednego lub więcej blocks, w zależności od rozmiaru. Jeśli plik jest mniejszy niż recordsize, będzie przechowywany w niewymiarowym bloku – na przykład block zawierający plik o rozmiarze 2KiB będzie zajmował tylko pojedynczy sector 4KiB na dysku.
Jeśli plik jest na tyle duży, że wymaga wielu blocks, wszystkie rekordy zawierające ten plik będą miały długość recordsize – łącznie z ostatnim rekordem, który może być w większości wolnym miejscem.
Zvols nie mają właściwości recordsize – zamiast tego mają volblocksize, co jest z grubsza równoważne.
Sektory
Ostatnim elementem konstrukcyjnym, który należy omówić, jest niski sector. A sector jest najmniejszą jednostką fizyczną, która może być zapisana lub odczytana z jej bazowego device. Przez kilkadziesiąt lat większość dysków używała 512-bajtowego sectors. Ostatnio większość dysków używa 4KiB sectors, a niektóre – zwłaszcza SSD – używają 8KiB sectors, a nawet większych.
ZFS ma właściwość, która pozwala na ręczne ustawienie rozmiaru sector, zwaną ashift. Nieco myląco, ashift jest tak naprawdę wykładnikiem binarnym, który reprezentuje rozmiar sektora – na przykład, ustawienie ashift=9 oznacza, że rozmiar sector będzie wynosił 2^9, czyli 512 bajtów.
ZFS odpytuje system operacyjny o szczegóły dotyczące każdego bloku device, gdy jest on dodawany do nowego vdev, i teoretycznie automatycznie ustawi ashift poprawnie w oparciu o te informacje. Niestety, istnieje wiele dysków, które kłamią przez zęby na temat rozmiaru sector, aby zachować zgodność z Windows XP (który nie był w stanie zrozumieć dysków o innym rozmiarze sector).
To oznacza, że administrator ZFS powinien być świadomy rzeczywistego rozmiaru sector swojego devices i ręcznie ustawić odpowiednio ashift. Jeśli ashift jest ustawione zbyt nisko, ponoszona jest astronomiczna kara za wzmocnienie odczytu/zapisu – zapis 512-bajtowych „sektorów” do rzeczywistego sector o rozmiarze 4KiB oznacza konieczność zapisania pierwszego „sektora”, następnie odczytania sector o rozmiarze 4KiB, zmodyfikowania go drugim 512-bajtowym „sektorem”, zapisania go z powrotem do *nowego* sector o rozmiarze 4KiB i tak dalej, przy każdym pojedynczym zapisie.
W realnym świecie ta kara za wzmocnienie uderza w dysk SSD Samsung EVO, który powinien mieć ashift=13, ale kłamie na temat rozmiaru sektora i dlatego domyślnie ustawia się na ashift=9, jeśli nie zostanie zastąpiony przez bystrego administratora – na tyle mocno, że wydaje się wolniejszy niż konwencjonalny dysk z rdzy.
Dla kontrastu, nie ma praktycznie żadnej kary za ustawienie ashift zbyt wysoko. Nie ma realnej kary za wydajność, a wzrost ilości wolnego miejsca jest nieskończenie mały (lub zerowy, przy włączonej kompresji). Zdecydowanie zalecamy, aby nawet dyski, które naprawdę używają sektorów 512-bajtowych, miały ustawione ashift=12 lub nawet ashift=13 dla zabezpieczenia na przyszłość.
Właściwość ashift jest per-vdev-nie per pool, jak się powszechnie i błędnie uważa!-i jest niezmienna, raz ustawiona. Jeśli przypadkowo zawalisz ashift podczas dodawania nowego vdeva do puli, nieodwracalnie zanieczyściłeś tę pulę drastycznie nieefektywnym vdev i generalnie nie masz innego wyjścia, jak tylko zniszczyć pulę i zacząć od nowa. Nawet usunięcie vdev nie uratuje Cię przed błędnym ustawieniem ashift!
Semantyka kopiowania na zapis




CoW-Copy on Write-jest fundamentalną podstawą większości tego, co czyni ZFS niesamowitym. Podstawowa koncepcja jest prosta – jeśli poprosisz tradycyjny system plików o zmodyfikowanie pliku in-place, zrobi on dokładnie to, o co go poprosiłeś. Jeśli poprosisz system plików copy-on-write o zrobienie tego samego, powie „ok” – ale będzie cię okłamywać.
Zamiast tego, system plików copy-on-write wypisze nową wersję block, którą zmodyfikowałeś, a następnie zaktualizuje metadane pliku, aby odłączyć stare block i połączyć nowe block, które właśnie napisałeś.
Odłączenie starego block i dołączenie nowego jest wykonywane w jednej operacji, więc nie można jej przerwać – jeśli zrzucisz zasilanie po tym, jak to się stanie, masz nową wersję pliku, a jeśli zrzucisz zasilanie przed, to masz starą wersję. Zawsze jesteś spójny z systemem plików, tak czy inaczej.
Copy-on-write w ZFS jest nie tylko na poziomie systemu plików, jest także na poziomie zarządzania dyskami. Oznacza to, że dziura w RAID – stan, w którym pasek jest zapisywany tylko częściowo przed awarią systemu, co czyni macierz niespójną i uszkodzoną po restarcie – nie ma wpływu na ZFS. Zapis na pasku jest atomowy, dysk vdev jest zawsze spójny, a Bob jest twoim wujkiem.
ZIL – dziennik intencji ZFS
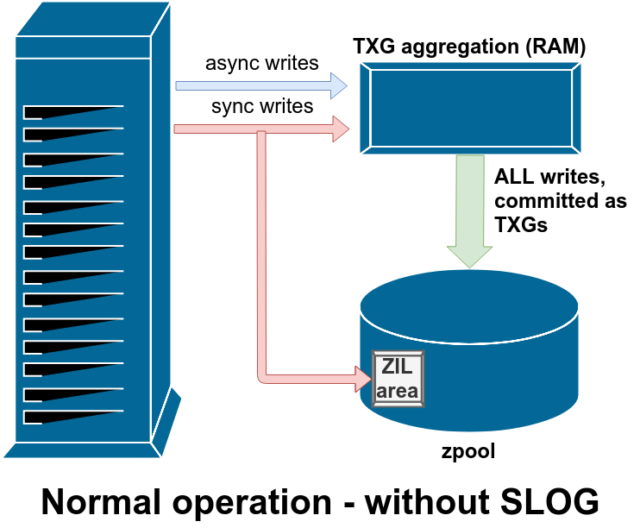

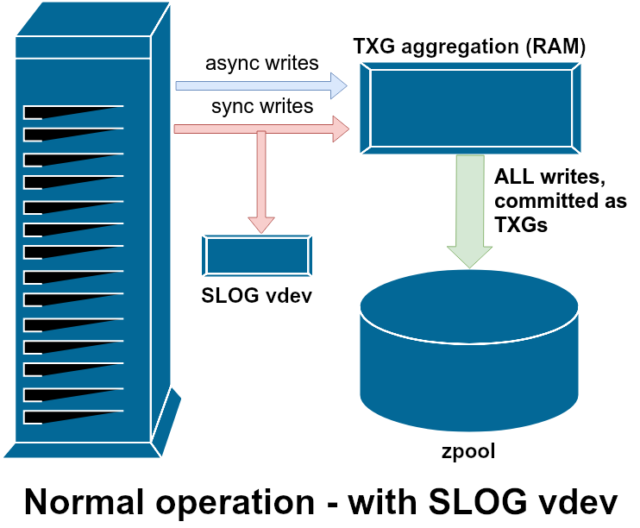

Istnieją dwie główne kategorie operacji zapisu – synchroniczne (sync) i asynchroniczne (async). Dla większości obciążeń, zdecydowana większość operacji zapisu jest asynchroniczna – system plików może je agregować i przesyłać partiami, redukując fragmentację i ogromnie zwiększając przepustowość.
Zapisy synchroniczne to zupełnie inne zwierzę – kiedy aplikacja żąda zapisu synchronicznego, mówi systemowi plików „musisz to teraz przesłać do pamięci nieulotnej, a dopóki tego nie zrobisz, nie mogę zrobić nic więcej”. Dlatego zapisy synchroniczne muszą być natychmiastowo przekazywane na dysk – a jeśli to zwiększy fragmentację lub zmniejszy przepustowość, niech tak będzie.
ZFS obsługuje zapisy synchroniczne inaczej niż normalne systemy plików – zamiast natychmiastowo wypłukiwać zapisy synchroniczne do normalnej pamięci masowej, ZFS przekazuje je do specjalnego obszaru pamięci masowej zwanego ZFS Intent Log, lub ZIL. Sztuczka polega na tym, że te zapisy również pozostają w pamięci, będąc agregowane wraz z normalnymi asynchronicznymi żądaniami zapisu, aby później zostać wypłukane do pamięci jako zupełnie normalne TXG (Transaction Groups).
W normalnej pracy, ZIL jest zapisywany i nigdy więcej nie jest odczytywany. Kiedy zapisy zapisane do ZIL są przekazywane do pamięci głównej z RAM w normalnych TXG kilka chwil później, są one odłączane od ZIL. Jedynym momentem, w którym ZIL jest odczytywany jest import puli.
Jeśli ZFS się zawiesi – lub system operacyjny się zawiesi, lub nastąpi nieobsługiwana przerwa w zasilaniu – gdy w ZIL znajdują się dane, zostaną one odczytane podczas następnego importu puli (np. gdy uszkodzony system zostanie ponownie uruchomiony). Cokolwiek znajduje się w ZIL, zostanie wczytane, zagregowane w TXG, przekazane do głównego magazynu, a następnie odłączone od ZIL podczas procesu importu.
Jedną z klas wsparcia vdev dostępnych jest LOG-znany również jako SLOG, lub wtórne urządzenie LOG. Wszystko, co robi SLOG, to zapewnienie puli z oddzielnym – i miejmy nadzieję, że znacznie szybszym, o bardzo wysokiej wytrzymałości na zapis –vdev do przechowywania ZIL w, zamiast utrzymywania ZIL na głównej pamięci masowej vdevs. Pod wszystkimi względami ZIL zachowuje się tak samo, czy jest na głównej pamięci masowej, czy na LOG vdev – ale jeśli LOG vdev ma bardzo wysoką wydajność zapisu, to powroty zapisu synchronicznego nastąpią bardzo szybko.
Dodanie urządzenia LOG vdev do puli absolutnie nie może i nie poprawi bezpośrednio wydajności zapisu asynchronicznego – nawet jeśli wymusisz wszystkie zapisy w ZIL za pomocą zfs set sync=always, nadal będą one przekazywane do głównej pamięci masowej w TXG w taki sam sposób i w takim samym tempie, jak bez LOG. Jedyne bezpośrednie ulepszenia wydajności dotyczą opóźnień zapisu synchronicznego (ponieważ większa prędkość LOG umożliwia szybszy powrót wywołania sync).
Jednakże w środowisku, które już wymaga wielu zapisów synchronicznych, vdev LOG może pośrednio przyspieszyć również zapisy asynchroniczne i odczyty bez pamięci podręcznej. Odciążenie zapisu ZIL do oddzielnego LOG vdev oznacza mniejszą konkurencję o IOPS na podstawowej pamięci masowej, zwiększając tym samym wydajność wszystkich odczytów i zapisów do pewnego stopnia.
Snapshoty
Semantyka kopiowania na zapisie jest także niezbędnym fundamentem dla atomowych snapshotów ZFS i przyrostowej replikacji asynchronicznej. Żywy system plików ma drzewo wskaźników oznaczających wszystkie records, które zawierają bieżące dane – kiedy robisz snapshot, po prostu robisz kopię tego drzewa wskaźników.
Gdy rekord jest nadpisywany w żywym systemie plików, ZFS najpierw zapisuje nową wersję block do nieużywanej przestrzeni. Następnie odłącza starą wersję block z bieżącego systemu plików. Ale jeśli jakikolwiek snapshot odwołuje się do starego block, nadal pozostaje niezmienny. Stary block nie zostanie faktycznie odzyskany jako wolna przestrzeń, dopóki wszystkie snapshots odwołujące się do tego block nie zostaną zniszczone!
Replikacja

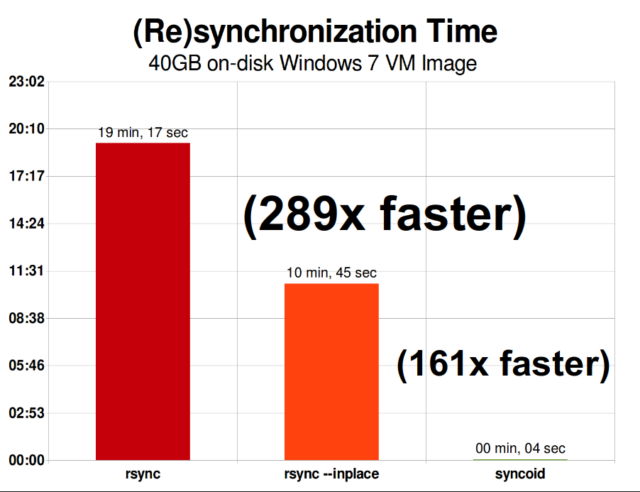
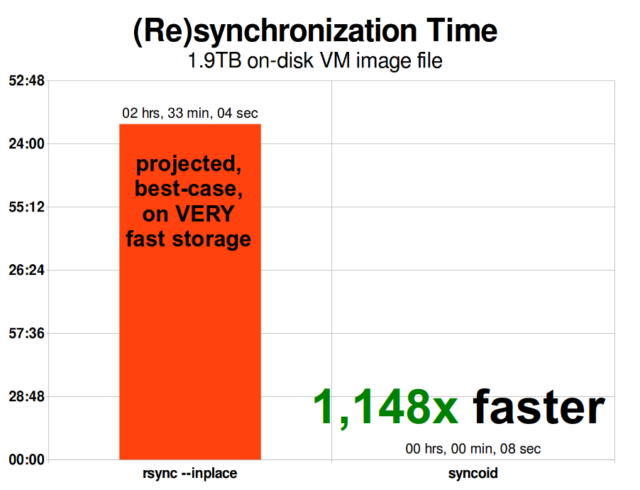 Kiedy już zrozumiesz, jak działają migawki, jesteś w dobrym miejscu, aby zrozumieć replikację. Ponieważ snapshot jest po prostu drzewem wskaźników do
Kiedy już zrozumiesz, jak działają migawki, jesteś w dobrym miejscu, aby zrozumieć replikację. Ponieważ snapshot jest po prostu drzewem wskaźników dorecords, wynika z tego, że jeślizfs sendsnapshot, wysyłamy zarówno to drzewo, jak i wszystkie powiązane z nim rekordy. Kiedy potokujemyzfs senddozfs receivena celu, zapisuje on zarówno rzeczywistą zawartośćblock, jak i drzewo wskaźników odnoszących się doblocks, do docelowego zbioru danych.
Rzeczy stają się bardziej interesujące przy drugim zfs send. Teraz, gdy masz już dwa systemy, z których każdy zawiera migawkę poolname/datasetname@1, możesz wykonać nową migawkę, poolname/datasetname@2. Tak więc na puli źródłowej masz datasetname@1 i datasetname@2, a na puli docelowej, jak dotąd, masz tylko pierwszy snapshot-datasetname@1.
Ponieważ mamy wspólny snapshot pomiędzy źródłem i miejscem docelowym-datasetname@1– możemy zbudować na nim przyrostowe zfs send. Gdy poprosimy system o zfs send -i poolname/datasetname@1 poolname/datasetname@2, porówna on dwa drzewa wskaźników. Wszelkie wskaźniki, które istnieją tylko w @2, w oczywisty sposób odwołują się do nowych blocks – będziemy więc potrzebować również zawartości tych blocks.
W zdalnym systemie pipingowanie w wynikowym przyrostowym send jest podobnie proste. Najpierw wypisujemy wszystkie nowe records zawarte w strumieniu send, a następnie dodajemy wskaźniki do tych blocks. Presto, mamy @2 w nowym systemie!
Asynchroniczna replikacja przyrostowa ZFS jest ogromnym usprawnieniem w stosunku do wcześniejszych, nie opartych na migawkach technik, takich jak rsync. W obu przypadkach, tylko zmienione dane muszą zostać przesłane przez kabel – ale rsync musi najpierw odczytać wszystkie dane z dysku, po obu stronach, w celu ich sprawdzenia i porównania. Dla kontrastu, replikacja ZFS nie musi czytać niczego poza drzewami wskaźników i wszystkimi blockstymi drzewami wskaźników, które nie były już obecne we wspólnym snapshocie.
Kompresja inline
Semantyka kopiowania przy zapisie ułatwia także oferowanie kompresji inline. W tradycyjnym systemie plików oferującym modyfikację in-place, kompresja jest problematyczna – zarówno stara wersja jak i nowa wersja zmodyfikowanych danych musi zmieścić się dokładnie w tej samej przestrzeni.
Jeśli weźmiemy pod uwagę kawałek danych w środku pliku, który zaczyna życie jako 1MiB zer-0x00000000 ad nauseam – bardzo łatwo skompresuje się do pojedynczego sektora dysku. Ale co się stanie, jeśli zastąpimy ten 1MiB zer 1MiB nieściśliwymi danymi, takimi jak JPEG lub pseudolosowy szum? Nagle, ten 1MiB danych wymaga 256 sektorów 4KiB, a nie tylko jednego – a dziura w środku pliku ma tylko jeden sektor szerokości.
ZFS nie ma tego problemu, ponieważ zmodyfikowane rekordy są zawsze zapisywane w niewykorzystanej przestrzeni – oryginalny block zajmuje tylko jeden sektor 4KiB sector, a nowy rekord zajmuje ich 256, ale to nie jest problem – nowo zmodyfikowany fragment ze „środka” pliku zostałby zapisany w niewykorzystanej przestrzeni niezależnie od tego, czy jego rozmiar się zmienił, czy nie, więc dla ZFS ten „problem” to po prostu kolejny dzień w biurze.
Kompresja inline w ZFS jest domyślnie wyłączona, i oferuje podłączalne algorytmy – obecnie są to LZ4, gzip (1-9), LZJB i ZLE.
- LZ4 jest algorytmem strumieniowym oferującym bardzo szybką kompresję i dekompresję, i jest wydajny w większości przypadków użycia – nawet z bardzo anemicznymi procesorami.
- GZIP jest czcigodnym algorytmem znanym i lubianym przez wszystkich użytkowników Uniksa. Można go zaimplementować z poziomami kompresji 1-9, z rosnącym stopniem kompresji i zużyciem procesora w miarę zbliżania się do poziomu 9. Gzip może być dobrym rozwiązaniem dla wszystkich tekstowych (lub w inny sposób ekstremalnie kompresowalnych) przypadków użycia, ale często powoduje wąskie gardła CPU – używaj go ostrożnie, szczególnie na wyższych poziomach.
- LZJB jest oryginalnym algorytmem używanym przez ZFS. Jest on przestarzały i nie powinien być już używany – LZ4 jest lepszy w każdym aspekcie.
- ZLE to Zero Level Encoding – pozostawia normalne dane w spokoju, ale kompresuje duże sekwencje zer. Użyteczne dla całkowicie nieściśliwych zbiorów danych (np. JPEG, MP4 lub inne już skompresowane formaty), ponieważ ignoruje nieściśliwe dane, ale kompresuje przestrzeń luzu na końcowych rekordach.
Zalecamy kompresję LZ4 dla prawie każdego możliwego przypadku użycia; kara za wydajność, gdy napotyka nieściśliwe dane jest bardzo mała, a zysk wydajności dla typowych danych jest znaczący. Kopiowanie obrazu maszyny wirtualnej dla nowej instalacji systemu operacyjnego Windows (tylko zainstalowany system operacyjny Windows, żadnych danych) poszło o 27% szybciej z compression=lz4 niż z compression=none w tym teście z 2015 roku.
ARC-the Adaptive Replacement Cache
ZFS jest jedynym nowoczesnym systemem plików, o którym wiemy, że używa własnego mechanizmu pamięci podręcznej odczytu, zamiast polegać na pamięci podręcznej strony systemu operacyjnego, aby zachować kopie ostatnio czytanych bloków w pamięci RAM.
Mimo, że oddzielny mechanizm pamięci podręcznej ma swoje problemy – ZFS nie może reagować na nowe żądania alokacji pamięci tak natychmiast jak jądro, i dlatego nowe wywołanie mallocate() może zawieść, jeśli potrzebowałoby pamięci RAM aktualnie zajmowanej przez ARC – jest dobry powód, przynajmniej na razie, by się z tym pogodzić.
Każdy znany współczesny system operacyjny – w tym MacOS, Windows, Linux i BSD – używa algorytmu LRU (Least Recently Used) do implementacji pamięci podręcznej strony. LRU jest naiwnym algorytmem, który przesuwa buforowany blok na „górę” kolejki za każdym razem, gdy jest on odczytywany, i eksmituje bloki z „dołu” kolejki, gdy jest to konieczne, aby dodać nowe misses cache (bloki, które musiały być odczytane z dysku, a nie z cache) na „górze”.”
Jest to w porządku do tej pory, ale w systemach z dużymi zestawami danych roboczych, LRU może łatwo skończyć się „thrashingiem” – usunięciem bardzo często potrzebnych bloków, aby zrobić miejsce dla bloków, które nigdy nie zostaną ponownie odczytane z pamięci podręcznej.
ARC jest znacznie mniej naiwnym algorytmem, o którym można myśleć jako o „ważonej” pamięci podręcznej. Za każdym razem, gdy buforowany blok jest odczytywany, staje się nieco „cięższy” i trudniejszy do eksmisji – i nawet po eksmisji, eksmitowany blok jest śledzony przez pewien okres czasu. Blok, który został wyeksmitowany, ale następnie musi być odczytany z powrotem do pamięci podręcznej, również stanie się „cięższy” i trudniejszy do wyeksmitowania.
Wynikiem końcowym tego wszystkiego jest pamięć podręczna z typowo dużo większym współczynnikiem trafień – stosunkiem pomiędzy trafieniami pamięci podręcznej (odczytami serwowanymi z pamięci podręcznej) a chybieniami pamięci podręcznej (odczytami serwowanymi z dysku). Jest to niezwykle ważna statystyka – nie tylko same trafienia w pamięci podręcznej są obsługiwane o rzędy wielkości szybciej, ale również chybienia pamięci podręcznej mogą być obsługiwane szybciej, ponieważ więcej trafień w pamięci podręcznej = mniej równoczesnych żądań na dysk = mniejsze opóźnienia dla tych pozostałych chybień, które muszą być obsługiwane z dysku.
Podsumowanie
Teraz, gdy omówiliśmy podstawową semantykę ZFS – jak działa copy-on-write i relacje między pulami, vdewami, blokami, sektorami i plikami – jesteśmy gotowi do rozmowy o rzeczywistej wydajności, z prawdziwymi liczbami.
Zostańcie z nami do następnej części naszej serii o podstawach przechowywania danych, aby zobaczyć rzeczywistą wydajność w pulach wykorzystujących mirror i RAIDz vdevs, w porównaniu do siebie nawzajem i tradycyjnych topologii RAID jądra Linux, które badaliśmy wcześniej.
Początkowo zajmiemy się tylko podstawami – topologiami ZFS jako takimi – ale potem będziemy gotowi do rozmowy o bardziej zaawansowanej konfiguracji i tuningu ZFS, włączając w to użycie wspierających typów vdev, takich jak L2ARC, SLOG i Alokacja Specjalna.