Von Kajal Yadav, einem freiberuflichen Autor über Data Science, Startups & Entrepreneurship.

Quelle Unsplash, bearbeitet vom Autor.
Sind Sie aufgeregt, in die Data Science Welt einzusteigen? Herzlichen Glückwunsch! Das ist immer noch die richtige Wahl, denn der Bedarf an Arbeit im Bereich Data Science und Künstliche Intelligenz ist in dieser Zeit enorm gestiegen.
Allerdings wird der Markt aufgrund der Krise derzeit härter, um ihn wieder mit mehr Arbeitskräften zu besetzen, als es früher der Fall war. Es könnte also sein, dass du dich mental auf eine lange Einstellungsreise und viele Ablehnungen auf dem Weg vorbereiten musst.
Während ich diesen Artikel schreibe, gehe ich davon aus, dass du bereits weißt, dass ein Data Science Portfolio wichtig ist und wie man es aufbaut.
Du verbringst vielleicht die meiste Zeit damit, Daten zu crunchen und zu verarbeiten, und nicht damit, ausgefallene Modelle anzuwenden.
Eine Frage, die mir immer wieder von Data-Science-Enthusiasten gestellt wird, ist, welche Art von Projekten sie in ihr Portfolio aufnehmen sollten, um ein enorm gutes und einzigartiges Portfolio aufzubauen.
Nachfolgend gebe ich 8 einzigartige Ideen für Ihr Data-Science-Portfolio mit angehängten Referenzartikeln, aus denen Sie die Einblicke erhalten, wie Sie mit einer bestimmten Idee beginnen können.
- Sentiment-Analyse für Depressionen auf der Grundlage von Social-Media-Posts
- Sports match video to text summarization using neural network
- Handschriftlicher Gleichungslöser mit CNN
- Zusammenfassung eines Geschäftstreffens mit NLP
- Gesichtserkennung erkennt Stimmungen und schlägt dementsprechend Lieder vor
- Finden von bewohnbaren Exoplaneten anhand von Bildern, die von Raumfahrzeugen wie Kepler aufgenommen wurden
- Bildregenerierung für altes, beschädigtes Rollenbild
- Musikgenerierung mit Deep Learning
- FINAL WORD
Sentiment-Analyse für Depressionen auf der Grundlage von Social-Media-Posts

Foto von dole777 auf Unsplash.
Dieses Thema ist so sensibel, dass man heutzutage dringend etwas dagegen tun muss. Weltweit gibt es mehr als 264 Millionen Menschen, die an einer Depression leiden. Depressionen sind weltweit die Hauptursache für Behinderungen und tragen wesentlich zur globalen Krankheitslast bei, und jedes Jahr sterben fast 800 000 Menschen durch Selbstmord. Selbstmord ist die zweithäufigste Todesursache bei den 15-29-Jährigen. Die Behandlung von Depressionen wird oft verzögert, ungenau oder ganz versäumt.
Das internetgestützte Leben bietet die Hauptchance, die frühzeitige Vermittlung von Melancholie zu ändern, insbesondere bei jungen Erwachsenen. Ständig werden etwa 6.000 Tweets auf Twitter getwittert, was mehr als 350.000 Tweets pro Moment, 500 Millionen Tweets pro Tag und etwa 200 Milliarden Tweets pro Jahr entspricht.
Wie das Pew Research Center angibt, nutzen 72 % der Öffentlichkeit eine Art von internetbasiertem Leben. Die von sozialen Netzwerken freigegebenen Daten sind für zahlreiche Bereiche wichtig, zum Beispiel für die Humanwissenschaften und die Hirnforschung. Aber die Unterstützung aus fachlicher Sicht reicht bei weitem nicht aus, und explizite Methoden sind hoffnungslos überfordert.
Durch die Analyse linguistischer Marker in Social-Media-Posts ist es möglich, ein Deep-Learning-Modell zu erstellen, das weitaus früher als herkömmliche Ansätze Aufschluss über die psychische Gesundheit einer Person geben kann.
- Du bist, was du twitterst – Erkennung von Depressionen in sozialen Medien anhand der Twitter-Nutzung
- Früherkennung von Depressionen: Social Network Analysis and Random Forest Techniques – Original paper, University of A Coruna.
- Depression detection from social network data using machine learning techniques
Sports match video to text summarization using neural network

Photo by Aksh yadav on Unsplash.
Diese Projektidee basiert also im Grunde darauf, eine präzise Zusammenfassung von Sportvideos zu erstellen. Es gibt Sport-Websites, die über die Höhepunkte des Spiels berichten. Es wurden verschiedene Modelle für die Aufgabe der extraktiven Textzusammenfassung vorgeschlagen, aber neuronale Netze leisten die beste Arbeit. In der Regel geht es bei der Zusammenfassung darum, Informationen in einer kurzen Struktur darzustellen und sich dabei auf die Teile zu konzentrieren, die Fakten und Informationen vermitteln, wobei die Wichtigkeit gewahrt bleibt.
Die automatische Erstellung einer Zusammenfassung eines Spielvideos bringt die Herausforderung mit sich, spannende Minuten oder Höhepunkte eines Spiels zu erkennen.
Das kann man mit Hilfe einiger Deep-Learning-Techniken wie 3D-CNN (dreidimensionale Faltungsnetzwerke), RNN (rekurrentes neuronales Netzwerk), LSTM (Long Short Term Memory-Netzwerke) und auch mit Algorithmen des maschinellen Lernens erreichen, indem man das Video in verschiedene Abschnitte unterteilt und dann SVM (Support Vector Machines), NN (neuronale Netzwerke) und k-means-Algorithmen anwendet.
Für ein besseres Verständnis lesen Sie bitte den beigefügten Artikel im Detail.
- Scene Classification for Sports Video Summarization Using Transfer Learning – Dieser Artikel schlägt eine neuartige Methode zur Klassifizierung von Sportvideoszenen vor.
Handschriftlicher Gleichungslöser mit CNN
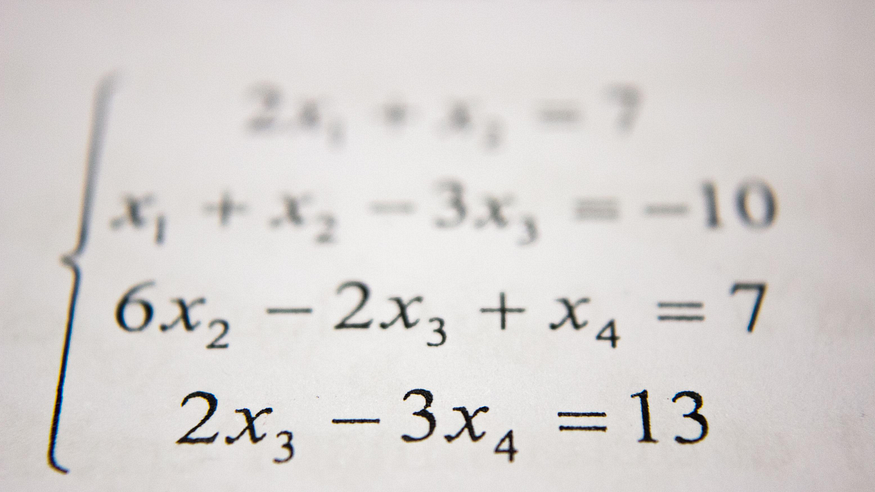
Foto von Antoine Dautry auf Unsplash.
Die Erkennung handgeschriebener mathematischer Ausdrücke ist eines der schwierigsten Probleme im Bereich der Computer Vision Forschung. Man kann einen handschriftlichen Gleichungslöser anhand handgeschriebener Ziffern und mathematischer Symbole trainieren, indem man ein Convolutional Neural Network (CNN) mit einigen Bildverarbeitungstechniken einsetzt. Um ein solches System zu entwickeln, müssen unsere Maschinen mit Daten trainiert werden, damit sie lernen und die erforderlichen Vorhersagen treffen können.
Lesen Sie zum besseren Verständnis die unten angefügten Artikel.
- Handschriftlicher Gleichungslöser mit Convolutional Neural Network
- vipul79321/Handschriftlicher-Gleichungslöser – Ein handschriftlicher Gleichungslöser mit CNN Die Gleichung kann eine beliebige Ziffer von 0-9 und ein Symbol enthalten.
- Computer Vision – Auto grading Handwritten Mathematical Answer Sheets – Digitalisierung der Schritte zum Lösen einer mathematischen Gleichung, die freihändig auf ein Papier geschrieben wurde.
- Handgeschriebene Gleichungen in LaTeX
Zusammenfassung eines Geschäftstreffens mit NLP

Foto von Sebastian Herrmann auf Unsplash.
Sind Sie schon einmal in eine Situation geraten, in der jeder eine Zusammenfassung und nicht den vollständigen Bericht sehen möchte? Nun, ich bin während meiner Schul- und Studienzeit damit konfrontiert worden, dass wir viel Zeit damit verbracht haben, einen ganzen Bericht vorzubereiten, der Lehrer aber nur Zeit hat, die Zusammenfassung zu lesen.
Die Zusammenfassung hat sich als unaufhaltsam hilfreicher Weg erwiesen, um das Problem der Datenflut zu bewältigen. Die Extraktion von Informationen aus Gesprächen kann von großem kommerziellen und pädagogischen Wert sein. Dies kann durch die Erfassung der statistischen, sprachlichen und gefühlsmäßigen Aspekte mit der Dialogstruktur des Gesprächs geschehen.
Die manuelle Umwandlung des Berichts in eine zusammengefasste Form ist zu zeitaufwendig, nicht wahr? Aber man kann sich auf Techniken der natürlichen Sprachverarbeitung (NLP) verlassen, um das zu erreichen.
Die Textzusammenfassung mit Deep Learning kann den Kontext des gesamten Textes verstehen. Ist das nicht ein wahrgewordener Traum für alle, die eine schnelle Zusammenfassung eines Dokuments benötigen?
Lesen Sie zum besseren Verständnis die unten angehängten Artikel.
- Comprehensive Guide to Text Summarization using Deep Learning in Python – „I don’t want a full report, just give me a summary of the results.“
- Verstehen Sie die Textzusammenfassung und erstellen Sie Ihren eigenen Summarizer in Python – Die Zusammenfassung kann als Aufgabe definiert werden, eine prägnante und flüssige Zusammenfassung zu erstellen und dabei die wichtigsten Informationen zu erhalten.
Gesichtserkennung erkennt Stimmungen und schlägt dementsprechend Lieder vor

Foto von Alireza Attari auf Unsplash.
Das menschliche Gesicht ist ein wichtiger Teil des Körpers einer Person, und es spielt vor allem eine wichtige Rolle dabei, den Gemütszustand einer Person zu erkennen. Damit entfällt die langweilige und mühsame Aufgabe, Lieder manuell zu isolieren oder in verschiedene Datensätze zu gruppieren, und es hilft bei der Erstellung einer geeigneten Wiedergabeliste auf der Grundlage der emotionalen Merkmale einer Person.
Menschen neigen dazu, Musik auf der Grundlage ihrer Stimmung und Interessen zu hören. Durch die Erfassung von Gesichtsausdrücken kann eine Anwendung erstellt werden, die dem Benutzer je nach seiner Stimmung Lieder vorschlägt.
Computer Vision ist ein interdisziplinäres Gebiet, das Computern hilft, digitale Bilder oder Videos auf hohem Niveau zu verstehen. Computer-Vision-Komponenten können verwendet werden, um die Emotionen des Benutzers durch Gesichtsausdrücke zu bestimmen.
Es gibt auch diese APIs, die ich interessant und nützlich fand. Ich habe jedoch nicht an ihnen gearbeitet, sondern sie hier angehängt, in der Hoffnung, dass sie Ihnen helfen.
- 20+ Emotion Recognition APIs That Will Leave You Impressed, and Concerned | Nordic APIs – Wenn Unternehmen mit Hilfe von Technologie jederzeit Emotionen erkennen könnten, könnten sie daraus Kapital schlagen, um an den Verbraucher zu verkaufen.
Finden von bewohnbaren Exoplaneten anhand von Bildern, die von Raumfahrzeugen wie Kepler aufgenommen wurden

Foto von Nick Owuor (astro.nic.visuals) auf Unsplash.
In den letzten zehn Jahren wurden über eine Million Sterne beobachtet, um durchziehende Planeten zu identifizieren. Die manuelle Auswertung potenzieller Exoplaneten-Kandidaten ist arbeitsintensiv und anfällig für menschliche Fehler, deren Folgen schwer abzuschätzen sind. Faltungsneuronale Netze eignen sich zur Identifizierung erdähnlicher Exoplaneten in verrauschten Zeitreihendaten mit höherer Präzision als eine Least-Squares-Strategie.
- Exoplanetenjagd mit maschinellem Lernen – Jagd auf Welten jenseits unseres Sonnensystems.
- Künstliche Intelligenz, Daten der NASA zur Entdeckung von Exoplaneten – Unser Sonnensystem hat nun die meisten Planeten um einen einzelnen Stern.
Bildregenerierung für altes, beschädigtes Rollenbild

Quelle Pikist.
Ich weiß, wie zeitaufwendig und schmerzhaft es ist, sein altes, beschädigtes Foto in der ursprünglichen Form wiederzubekommen, wie es früher war. Dies kann mit Hilfe von Deep Learning geschehen, indem man alle Bilddefekte (Brüche, Schrammen, Löcher) findet und Inpainting-Algorithmen einsetzt, so dass man die Defekte anhand der Pixelwerte um sie herum leicht entdecken kann, um die alten Fotos wiederherzustellen und einzufärben.
- Einfärben und Wiederherstellen alter Bilder mit Deep Learning – Das Einfärben von Schwarz-Weiß-Bildern mit Deep Learning hat sich zu einem beeindruckenden Schaufenster für die reale Anwendung entwickelt.
- Guide to Image Inpainting: Mit maschinellem Lernen Defekte in Fotos bearbeiten und korrigieren
- Wie man Bildrestaurierung absolut datensatzfrei durchführt
Musikgenerierung mit Deep Learning

Foto von Abigail Keenan auf Unsplash.
Musik ist eine Zusammenstellung von Tönen verschiedener Frequenzen. Bei der automatischen Musikerzeugung geht es also darum, ein kurzes Musikstück mit möglichst wenig menschlicher Vermittlung zu komponieren. In jüngster Zeit hat sich die Deep-Learning-Technik zum Wegbereiter für die programmierte Musikgenerierung entwickelt.
- Musikgenerierung mit Deep Learning
- Wie man mit einem LSTM Neural Network in Keras Musik generiert – Eine Einführung in die Erstellung von Musik mit LSTM Neural Networks
FINAL WORD
Ich weiß, dass es ein echter Kampf ist, ein cooles Data Science Portfolio aufzubauen. Aber mit einer solchen Sammlung, die ich oben zur Verfügung gestellt habe, können Sie überdurchschnittliche Fortschritte in diesem Bereich machen. Die Sammlung ist neu, was auch die Möglichkeit für Forschungszwecke bietet. Forscher in der Datenwissenschaft können also auch diese Ideen auswählen, um daran zu arbeiten, so dass ihre Forschung eine große Hilfe für Datenwissenschaftler wäre, um mit dem Projekt zu beginnen. Außerdem macht es Spaß, die Seiten zu erforschen, die noch niemand zuvor gemacht hat. Obwohl diese Sammlung eigentlich Ideen vom Anfänger bis zum Fortgeschrittenen darstellt.
So empfehle ich dies nicht nur für Neulinge im Bereich Data Science, sondern auch für ältere Data Scientists. Es wird einem viele neue Wege in der Karriere eröffnen, nicht nur wegen der Projekte, sondern auch durch das neu gewonnene Netzwerk.
Diese Ideen zeigen einem das breite Spektrum an Möglichkeiten und geben einem die Ideen, über den Tellerrand zu schauen.
Für mich und meine Freunde sind die Lernfaktoren, der Mehrwert für die Gesellschaft und das unerforschte Wissen wichtig, und der Spaß ist in gewisser Weise essentiell. Im Grunde genommen genieße ich es also, an solchen Projekten mitzuarbeiten, die uns die Möglichkeit geben, immenses Wissen zu erlangen und unerforschte Dimensionen zu erkunden. Das ist unser Hauptaugenmerk, wenn wir uns solchen Projekten widmen.
Original. Nachdruck mit Genehmigung.
Bio: Kajal Yadav ist eine freiberufliche Autorin, die sich auf Datenwissenschaft, Startups und Unternehmertum spezialisiert hat. Sie schreibt für verschiedene Publikationen und arbeitet gleichzeitig mit Startups an deren Content-Marketing-Strategien.
Verwandt:
- Starten Sie Ihre Machine-Learning-Karriere in Quarantäne
- Projekte, die in ein Data-Science-Portfolio aufgenommen werden sollten
- Wie man ein Data-Science-Portfolio aufbaut